
Über den Autor
Krasimir Tsonev ist ein Coder mit über zehn Jahren Erfahrung in der Webentwicklung. Er ist Autor von zwei Büchern über Node.js. Er arbeitet als Senior Front-End-Entwickler für …Mehr überKrasimir↬
- 20 min read
- UI,Apps,JavaScript
- Speichern zum Offline-Lesen
- Share on Twitter, LinkedIn


Es ist bereits 2018 und unzählige Frontend-Entwickler führen immer noch einen Kampf gegen Komplexität und Unbeweglichkeit. Monat für Monat sind sie auf der Suche nach dem heiligen Gral: einer fehlerfreien Anwendungsarchitektur, die ihnen hilft, schnell und mit hoher Qualität zu liefern. Ich bin einer dieser Entwickler, und ich habe etwas Interessantes gefunden, das helfen könnte.
Mit Tools wie React und Redux haben wir einen guten Schritt nach vorne gemacht. Allerdings reichen sie bei großen Anwendungen alleine nicht aus. Dieser Artikel wird Ihnen das Konzept der Zustandsautomaten im Kontext der Frontend-Entwicklung vorstellen. Wahrscheinlich haben Sie schon einige von ihnen gebaut, ohne es zu merken.
Eine Einführung in Zustandsautomaten
Ein Zustandsautomat ist ein mathematisches Modell für Berechnungen. Es ist ein abstraktes Konzept, bei dem der Automat verschiedene Zustände haben kann, aber zu einem bestimmten Zeitpunkt nur einen davon erfüllt. Es gibt verschiedene Arten von Zustandsautomaten. Der berühmteste ist, glaube ich, die Turing-Maschine. Sie ist eine unendliche Zustandsmaschine, was bedeutet, dass sie eine unendliche Anzahl von Zuständen haben kann. Die Turing-Maschine passt nicht gut in die heutige UI-Entwicklung, da wir in den meisten Fällen eine endliche Anzahl von Zuständen haben. Deshalb sind endliche Zustandsautomaten wie Mealy und Moore sinnvoller.
Der Unterschied zwischen ihnen ist, dass der Moore-Automat seinen Zustand nur auf Basis des vorherigen Zustands ändert. Leider haben wir eine Menge externer Faktoren, wie Benutzerinteraktionen und Netzwerkprozesse, was bedeutet, dass der Moore-Automat für uns auch nicht gut genug ist. Was wir suchen, ist die Mealy-Maschine. Sie hat einen Anfangszustand und geht dann, basierend auf Eingaben und ihrem aktuellen Zustand, in neue Zustände über.
Eine der einfachsten Möglichkeiten, die Funktionsweise einer Zustandsmaschine zu veranschaulichen, ist die Betrachtung eines Drehkreuzes. Es hat eine endliche Anzahl von Zuständen: verriegelt und unverriegelt. Hier ist eine einfache Grafik, die uns diese Zustände mit ihren möglichen Eingängen und Übergängen zeigt.

Der Anfangszustand des Drehkreuzes ist gesperrt. Egal wie oft wir es betätigen, es bleibt in diesem verriegelten Zustand. Wenn wir ihm jedoch eine Münze zuwerfen, geht es in den unverriegelten Zustand über. Eine weitere Münze an diesem Punkt würde nichts bewirken; sie wäre immer noch im unverriegelten Zustand. Ein Druck von der anderen Seite würde funktionieren, und wir wären in der Lage, weiterzugeben. Diese Aktion versetzt den Automaten auch in den anfänglichen gesperrten Zustand.
Wenn wir eine einzelne Funktion implementieren wollten, die das Drehkreuz steuert, hätten wir wahrscheinlich zwei Argumente: den aktuellen Zustand und eine Aktion. Wenn Sie Redux verwenden, kommt Ihnen das wahrscheinlich bekannt vor. Es ähnelt der bekannten reducer-Funktion, bei der wir den aktuellen Zustand erhalten und basierend auf der Nutzlast der Aktion entscheiden, was der nächste Zustand sein wird. Der reducer ist die Transition im Kontext von Zustandsautomaten. Tatsächlich kann jede Anwendung, die einen Zustand hat, den wir irgendwie ändern können, als Zustandsautomat bezeichnet werden. Es ist nur so, dass wir alles immer wieder manuell implementieren.
Wie ist eine State Machine besser?
Bei der Arbeit verwenden wir Redux, und ich bin recht zufrieden damit. Allerdings habe ich angefangen, Muster zu sehen, die ich nicht mag. Mit „nicht mögen“ meine ich nicht, dass sie nicht funktionieren. Es ist eher so, dass sie die Komplexität erhöhen und mich zwingen, mehr Code zu schreiben. Ich musste ein Nebenprojekt in Angriff nehmen, bei dem ich Raum zum Experimentieren hatte, und ich beschloss, unsere Entwicklungspraktiken für React und Redux zu überdenken. Ich fing an, mir Notizen über die Dinge zu machen, die mir Sorgen machten, und mir wurde klar, dass eine State-Machine-Abstraktion einige dieser Probleme wirklich lösen würde. Lassen Sie uns einsteigen und sehen, wie man einen Zustandsautomaten in JavaScript implementiert.
Wir werden ein einfaches Problem angehen. Wir wollen Daten von einer Back-End-API abrufen und sie dem Benutzer anzeigen. Der allererste Schritt besteht darin, zu lernen, in Zuständen zu denken, anstatt in Übergängen. Bevor wir uns mit Zustandsautomaten beschäftigen, sah mein Arbeitsablauf für die Erstellung einer solchen Funktion in etwa so aus:
- Wir zeigen eine Schaltfläche zum Abrufen von Daten an.
- Der Benutzer klickt auf die Schaltfläche zum Abrufen von Daten.
- Abfeuern der Anfrage an das Backend.
- Abrufen der Daten und Parsen.
- Anzeigen der Daten beim Benutzer.
- Oder, wenn ein Fehler auftritt, die Fehlermeldung anzeigen und die Schaltfläche „fetch-data“ anzeigen, damit wir den Prozess erneut auslösen können.

Wir denken linear und versuchen grundsätzlich alle möglichen Richtungen zum Endergebnis abzudecken. Ein Schritt führt zum nächsten, und schnell würden wir anfangen, unseren Code zu verzweigen. Was ist mit Problemen wie dem Doppelklick des Benutzers auf die Schaltfläche oder dem Klicken des Benutzers auf die Schaltfläche, während wir auf die Antwort des Backends warten, oder die Anfrage war erfolgreich, aber die Daten sind beschädigt. In diesen Fällen würden wir wahrscheinlich verschiedene Flags haben, die uns zeigen, was passiert ist. Flaggen zu haben bedeutet mehr ifKlauseln und, in komplexeren Anwendungen, mehr Konflikte.

Das liegt daran, dass wir in Übergängen denken. Wir konzentrieren uns darauf, wie diese Übergänge ablaufen und in welcher Reihenfolge. Wenn wir uns stattdessen auf die verschiedenen Zustände der Anwendung konzentrieren würden, wäre es viel einfacher. Wie viele Zustände haben wir, und was sind ihre möglichen Eingaben? Mit dem gleichen Beispiel:
- Idle
In diesem Zustand zeigen wir die Schaltfläche zum Abrufen der Daten an, sitzen und warten. Die möglichen Aktionen sind:- Klick
Wenn der Benutzer auf die Schaltfläche klickt, feuern wir die Anfrage an das Backend und gehen dann in den Zustand „Fetching“ über.
- Klick
- Fetching
Die Anfrage ist im Flug, und wir sitzen und warten. Die Aktionen sind:- Erfolg
Die Daten kommen erfolgreich an und sind nicht beschädigt. Wir verwenden die Daten auf irgendeine Weise und gehen zurück in den Zustand „Leerlauf“. - Fehler
Wenn es einen Fehler bei der Anfrage oder beim Parsen der Daten gibt, gehen wir in den Zustand „Fehler“ über.
- Erfolg
- Fehler
Wir zeigen eine Fehlermeldung und die Schaltfläche „Daten holen“ an. Dieser Zustand lässt eine Aktion zu:- retry
Wenn der Benutzer auf die Schaltfläche „retry“ klickt, feuern wir die Anfrage erneut ab und gehen in den Zustand „fetching“ über.
- retry
Wir haben ungefähr die gleichen Prozesse beschrieben, aber mit Zuständen und Eingaben.
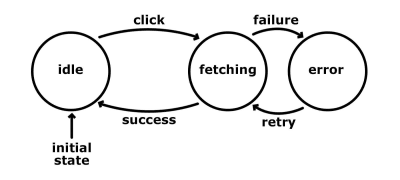
Das vereinfacht die Logik und macht sie vorhersehbarer. Es löst auch einige der oben erwähnten Probleme. Beachten Sie, dass wir, während wir uns im „Abruf“-Zustand befinden, keine Klicks akzeptieren. Selbst wenn der Benutzer also auf die Schaltfläche klickt, wird nichts passieren, da der Rechner nicht so konfiguriert ist, dass er auf diese Aktion reagiert, solange er sich in diesem Zustand befindet. Dieser Ansatz eliminiert automatisch die unvorhersehbaren Verzweigungen unserer Codelogik. Das bedeutet, dass wir beim Testen weniger Code abdecken müssen. Außerdem können einige Arten von Tests, wie z. B. Integrationstests, automatisiert werden. Stellen Sie sich vor, wir hätten eine wirklich klare Vorstellung davon, was unsere Anwendung tut, und könnten ein Skript erstellen, das die definierten Zustände und Übergänge durchgeht und Assertions generiert. Diese Assertions könnten beweisen, dass wir jeden möglichen Zustand erreicht oder einen bestimmten Weg zurückgelegt haben.
In der Tat ist es einfacher, alle möglichen Zustände aufzuschreiben als alle möglichen Übergänge, weil wir wissen, welche Zustände wir brauchen oder haben. Übrigens würden die Zustände in den meisten Fällen die Geschäftslogik unserer Anwendung beschreiben, während die Transitionen am Anfang sehr oft unbekannt sind. Die Fehler in unserer Software sind das Ergebnis von Aktionen, die in einem falschen Zustand und/oder zum falschen Zeitpunkt ausgeführt werden. Sie lassen unsere App in einem Zustand zurück, von dem wir nichts wissen, und das macht unser Programm kaputt oder lässt es sich falsch verhalten. Natürlich wollen wir nicht in eine solche Situation geraten. Zustandsautomaten sind gute Firewalls. Sie schützen uns davor, unbekannte Zustände zu erreichen, weil wir Grenzen dafür setzen, was wann passieren kann, ohne explizit zu sagen, wie. Das Konzept eines Zustandsautomaten lässt sich sehr gut mit einem unidirektionalen Datenfluss kombinieren. Zusammen reduzieren sie die Komplexität des Codes und klären das Geheimnis, woher ein Zustand kommt.
Erstellen einer State Machine in JavaScript
Genug geredet – sehen wir uns etwas Code an. Wir werden das gleiche Beispiel verwenden. Ausgehend von der obigen Liste beginnen wir mit folgendem:
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } }}Wir haben die Zustände als Objekte und ihre möglichen Eingänge als Funktionen. Es fehlt allerdings der Anfangszustand. Ändern wir den obigen Code in diesen:
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } }}Wenn wir alle für uns sinnvollen Zustände definiert haben, sind wir bereit, die Eingabe zu senden und den Zustand zu ändern. Dazu verwenden wir die beiden folgenden Hilfsmethoden:
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions; const action = this.transitions; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ...}Die dispatch-Funktion prüft, ob in den Übergängen des aktuellen Zustands eine Aktion mit dem angegebenen Namen vorhanden ist. Wenn ja, feuert sie diese mit der angegebenen Nutzlast ab. Wir rufen auch den action Handler mit dem machine als Kontext auf, so dass wir weitere Aktionen mit this.dispatch(<action>) absetzen oder den Zustand mit this.changeStateTo(<new state>) ändern können.
Wenn wir der User Journey unseres Beispiels folgen, ist die erste Aktion, die wir versenden müssen, click. So sieht der Handler dieser Aktion aus:
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ...}machine.dispatch('click');Wir ändern zunächst den Zustand der Maschine auf fetching. Dann lösen wir die Anfrage an das Backend aus. Nehmen wir an, wir haben einen Dienst mit einer Methode getData, die ein Versprechen zurückgibt. Wenn es aufgelöst wird und das Parsen der Daten in Ordnung ist, versenden wir success, wenn nicht failure.
So weit, so gut. Als nächstes müssen wir success und failure Aktionen und Eingaben unter dem fetching Zustand implementieren:
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ...}Beachten Sie, wie wir unser Gehirn davon befreit haben, über den vorherigen Prozess nachdenken zu müssen. Wir kümmern uns nicht um die Klicks des Benutzers oder was mit der HTTP-Anfrage passiert. Wir wissen, dass sich die Anwendung in einem fetching-Zustand befindet, und wir erwarten nur diese beiden Aktionen. Es ist ein bisschen wie das Schreiben neuer Logik in Isolation.
Das letzte Stück ist der error Zustand. Es wäre schön, wenn wir diese Wiederholungslogik bereitstellen würden, damit die Anwendung sich von einem Fehler erholen kann.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } }}Hier müssen wir die Logik duplizieren, die wir im click-Handler geschrieben haben. Um das zu vermeiden, sollten wir entweder den Handler als Funktion definieren, auf die beide Aktionen zugreifen können, oder wir gehen zuerst in den idle-Zustand über und versenden dann die click-Aktion manuell.
Ein vollständiges Beispiel des funktionierenden Zustandsautomaten finden Sie in meinem Codepen.
Zustandsautomaten mit einer Bibliothek verwalten
Das endliche Zustandsautomatenmuster funktioniert unabhängig davon, ob wir React, Vue oder Angular verwenden. Wie wir im vorigen Abschnitt gesehen haben, können wir einen Zustandsautomaten ohne viel Mühe implementieren. Manchmal bietet jedoch eine Bibliothek mehr Flexibilität. Einige der guten sind Machina.js und XState. In diesem Artikel werden wir jedoch über Stent sprechen, meine Redux-ähnliche Bibliothek, die das Konzept der endlichen Zustandsautomaten einbindet.
Stent ist eine Implementierung eines Zustandsautomaten-Containers. Sie folgt einigen der Ideen der Projekte Redux und Redux-Saga, bietet aber meiner Meinung nach einfachere und kesselplattenfreie Abläufe. Es wird mit readme-driven development entwickelt, und ich habe buchstäblich Wochen nur mit dem API-Design verbracht. Da ich die Bibliothek schrieb, hatte ich die Möglichkeit, die Probleme zu beheben, auf die ich bei der Verwendung der Redux- und Flux-Architekturen gestoßen bin.
Maschinen erstellen
In den meisten Fällen decken unsere Anwendungen mehrere Domänen ab. Wir können uns nicht mit nur einer Maschine begnügen. Daher erlaubt Stent die Erstellung vieler Maschinen:
import { Machine } from 'stent';const machineA = Machine.create('A', { state: ..., transitions: ...});const machineB = Machine.create('B', { state: ..., transitions: ...});Später können wir mit der Methode Machine.get Zugriff auf diese Maschinen erhalten:
const machineA = Machine.get('A');const machineB = Machine.get('B');Verbinden der Maschinen mit der Rendering-Logik
Das Rendering erfolgt in meinem Fall über React, aber wir können jede andere Bibliothek verwenden. Es läuft darauf hinaus, einen Callback zu feuern, in dem wir das Rendering auslösen. Eine der ersten Funktionen, an denen ich gearbeitet habe, war die connect-Funktion:
import { connect } from 'stent/lib/helpers';Machine.create('MachineA', ...);Machine.create('MachineB', ...);connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here });Wir sagen, welche Maschinen für uns wichtig sind und geben ihre Namen an. Der Callback, den wir an map übergeben, wird einmal am Anfang abgefeuert und dann später jedes Mal, wenn sich der Zustand einiger der Maschinen ändert. An dieser Stelle lösen wir das Rendering aus. Zu diesem Zeitpunkt haben wir direkten Zugriff auf die angeschlossenen Maschinen, so dass wir den aktuellen Zustand und die Methoden abrufen können. Es gibt auch mapOnce, um den Callback nur einmal feuern zu lassen, und mapSilent, um diese erste Ausführung zu überspringen.
Zur Vereinfachung wird ein Helper speziell für die React-Integration exportiert. Er ist dem connect(mapStateToProps) von Redux sehr ähnlich.
import React from 'react';import { connect } from 'stent/lib/react';class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... }}// MachineA and MachineB are machines defined// using Machine.create functionexport default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos });Stent führt unseren Mapping-Callback aus und erwartet, ein Objekt zu erhalten – ein Objekt, das als props an unsere React-Komponente gesendet wird.
Was ist State im Kontext von Stent?
Bislang war unser State eine einfache Zeichenkette. Leider müssen wir in der realen Welt mehr als eine Zeichenkette im Zustand halten. Aus diesem Grund ist der Zustand von Stent eigentlich ein Objekt mit Eigenschaften darin. Die einzige reservierte Eigenschaft ist name. Alles andere sind app-spezifische Daten. Zum Beispiel:
{ name: 'idle' }{ name: 'fetching', todos: }{ name: 'forward', speed: 120, gear: 4 }Meine bisherigen Erfahrungen mit Stent zeigen mir, dass, wenn das Zustandsobjekt größer wird, wir wahrscheinlich eine weitere Maschine benötigen, die diese zusätzlichen Eigenschaften handhabt. Die Identifizierung der verschiedenen Zustände nimmt etwas Zeit in Anspruch, aber ich glaube, dass dies ein großer Schritt nach vorne ist, um besser handhabbare Anwendungen zu schreiben. Es ist ein bisschen so, als würde man die Zukunft vorhersagen und Rahmen für die möglichen Aktionen zeichnen.
Arbeiten mit der State Machine
Analog zum Beispiel am Anfang müssen wir die möglichen (endlichen) Zustände unserer Maschine definieren und die möglichen Eingaben beschreiben:
import { Machine } from 'stent';const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } }});Wir haben unseren Anfangszustand, idle, der eine Aktion von run akzeptiert. Sobald sich die Maschine in einem running-Zustand befindet, können wir die stop-Aktion abfeuern, die uns zurück in den idle-Zustand bringt.
Sie werden sich wahrscheinlich an die dispatch und changeStateTo Helfer aus unserer früheren Implementierung erinnern. Diese Bibliothek bietet die gleiche Logik, aber sie ist intern versteckt, und wir müssen nicht darüber nachdenken. Der Einfachheit halber generiert Stent, basierend auf der Eigenschaft transitions, das Folgende:
- Hilfsmethoden, um zu prüfen, ob sich die Maschine in einem bestimmten Zustand befindet – für den Zustand
idlewird die MethodeisIdle()erzeugt, fürrunninghaben wirisRunning(); - Hilfsmethoden für das Dispatching von Aktionen:
runPlease()undstopNow().
Im obigen Beispiel können wir also folgendes verwenden:
machine.isIdle(); // booleanmachine.isRunning(); // booleanmachine.runPlease(); // fires actionmachine.stopNow(); // fires actionKombinieren wir die automatisch generierten Methoden mit der connect Utility-Funktion, können wir den Kreis schließen. Eine Benutzerinteraktion löst die Maschineneingabe und -aktion aus, wodurch der Zustand aktualisiert wird. Aufgrund dieser Aktualisierung wird die an connect übergebene Mapping-Funktion abgefeuert, und wir werden über die Zustandsänderung informiert. Dann wird neu gerendert.
Eingabe- und Aktionshandler
Der wohl wichtigste Teil sind die Aktionshandler. Dies ist der Ort, an dem wir den größten Teil der Anwendungslogik schreiben, da wir auf Eingaben und veränderte Zustände reagieren. Etwas, das ich an Redux sehr mag, ist auch hier integriert: die Unveränderlichkeit und Einfachheit der Reducer-Funktion. Die Essenz des Action-Handlers von Stent ist die gleiche. Er erhält den aktuellen Zustand und die Action-Payload, und er muss den neuen Zustand zurückgeben. Wenn der Handler nichts zurückgibt (undefined), dann bleibt der Zustand der Maschine gleich.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = ; return { name: 'idle', todos }; } }}Angenommen, wir müssen Daten von einem entfernten Server abrufen. Wir feuern die Anfrage ab und versetzen den Rechner in einen fetching Zustand. Sobald die Daten vom Backend kommen, feuern wir eine success-Aktion ab, etwa so:
machine.success({ label: '...' });Dann gehen wir zurück in einen idle-Zustand und halten einige Daten in Form des todos-Arrays. Es gibt ein paar andere mögliche Werte, die als Action-Handler gesetzt werden können. Der erste und einfachste Fall ist, wenn wir nur einen String übergeben, der zum neuen Zustand wird.
transitions: { 'idle': { 'run': 'running' }}Dies ist ein Übergang von { name: 'idle' } zu { name: 'running' } unter Verwendung der run()-Aktion. Dieser Ansatz ist nützlich, wenn wir synchrone Zustandsübergänge haben und keine Metadaten haben. Wenn wir also etwas anderes im Zustand halten, wird diese Art der Transition es ausspülen. Auf ähnliche Weise können wir ein Zustandsobjekt direkt übergeben:
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: } }}Wir gehen von editing zu idle mit Hilfe der deleteAllTodos-Aktion über.
Wir haben bereits den Funktionshandler gesehen, und die letzte Variante des Aktionshandlers ist eine Generatorfunktion. Sie ist vom Redux-Saga-Projekt inspiriert, und sie sieht so aus:
import { call } from 'stent/lib/helpers';Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } }});Wenn Sie keine Erfahrung mit Generatoren haben, könnte das etwas kryptisch aussehen. Aber die Generatoren in JavaScript sind ein mächtiges Werkzeug. Wir können unseren Action-Handler pausieren, den Zustand mehrfach ändern und asynchrone Logik handhaben.
Spaß mit Generatoren
Als ich Redux-Saga zum ersten Mal kennenlernte, dachte ich, es sei eine zu komplizierte Art, asynchrone Operationen zu handhaben. Tatsächlich ist es eine ziemlich intelligente Implementierung des Befehlsentwurfsmusters. Der Hauptvorteil dieses Musters ist, dass es den Aufruf der Logik und ihre tatsächliche Implementierung trennt.
Mit anderen Worten: Wir sagen, was wir wollen, aber nicht, wie es geschehen soll. Die Blogserie von Matt Hink hat mir geholfen zu verstehen, wie Sagas implementiert werden, und ich empfehle dringend, sie zu lesen. Ich habe die gleichen Ideen in Stent eingebracht, und für den Zweck dieses Artikels werden wir sagen, dass wir durch das Ausgeben von Dingen Anweisungen darüber geben, was wir wollen, ohne es tatsächlich zu tun. Sobald die Aktion ausgeführt ist, erhalten wir die Kontrolle zurück.
Zurzeit können ein paar Dinge ausgesendet (yielded) werden:
- ein Zustandsobjekt (oder eine Zeichenkette) zum Ändern des Zustands der Maschine;
- ein Aufruf des
call-Helpers (er akzeptiert eine synchrone Funktion, also eine Funktion, die ein Versprechen oder eine andere Generatorfunktion zurückgibt) – wir sagen im Grunde: „Führe das für mich aus, und wenn es asynchron ist, warte. Wenn du fertig bist, gib mir das Ergebnis.“; - ein Aufruf des
wait-Helfers (er akzeptiert einen String, der eine andere Aktion repräsentiert); wenn wir diese Hilfsfunktion verwenden, halten wir den Handler an und warten darauf, dass eine andere Aktion versendet wird.
Hier ist eine Funktion, die die Varianten veranschaulicht:
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... });}...transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } }}Wie wir sehen können, sieht der Code synchron aus, aber in Wirklichkeit ist er es nicht. Es ist nur Stent, das den langweiligen Teil des Wartens auf das aufgelöste Versprechen oder die Iteration über einen anderen Generator erledigt.
Wie Stent meine Redux-Bedenken löst
Zu viel Boilerplate-Code
Die Redux- (und Flux-) Architektur verlässt sich auf Aktionen, die in unserem System zirkulieren. Wenn die Anwendung wächst, haben wir in der Regel eine Menge Konstanten und Aktionsersteller. Diese beiden Dinge befinden sich sehr oft in verschiedenen Ordnern, und die Verfolgung der Ausführung des Codes nimmt manchmal Zeit in Anspruch. Außerdem müssen wir, wenn wir eine neue Funktion hinzufügen, immer mit einer ganzen Reihe von Aktionen umgehen, was bedeutet, dass wir mehr Aktionsnamen und Aktionsersteller definieren müssen.
In Stent haben wir keine Aktionsnamen, und die Bibliothek erstellt die Aktionsersteller automatisch für uns:
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } }});machine.addTodo({ title: 'Fix that bug' });Wir haben den machine.addTodo Aktionsersteller direkt als Methode der Maschine definiert. Dieser Ansatz löste auch ein weiteres Problem, mit dem ich konfrontiert war: das Finden des Reduzierers, der auf eine bestimmte Aktion reagiert. Normalerweise sehen wir in React-Komponenten Action-Creator-Namen wie addTodo; in den Reducern arbeiten wir jedoch mit einem Aktionstyp, der konstant ist. Manchmal muss ich zum Code des Action-Creators springen, nur damit ich den genauen Typ sehen kann. Hier haben wir überhaupt keine Typen.
Unvorhersehbare Zustandsänderungen
Im Allgemeinen leistet Redux gute Arbeit bei der Verwaltung des Zustands auf unveränderliche Weise. Das Problem liegt nicht in Redux selbst, sondern darin, dass es dem Entwickler erlaubt ist, zu jeder Zeit eine beliebige Aktion zu dispatchen. Wenn wir sagen, dass wir eine Aktion haben, die das Licht einschaltet, ist es dann in Ordnung, diese Aktion zweimal hintereinander auszulösen? Wenn nicht, wie sollen wir dann dieses Problem mit Redux lösen? Nun, wir würden wahrscheinlich etwas Code in den Reducer einbauen, der die Logik schützt und der überprüft, ob die Lichter bereits eingeschaltet sind – vielleicht eine if-Klausel, die den aktuellen Zustand überprüft. Die Frage ist nun, ob das nicht außerhalb des Aufgabenbereichs des Reduzierers liegt. Sollte der Reducer über solche Randfälle Bescheid wissen?
Was ich in Redux vermisse, ist eine Möglichkeit, das Dispatching einer Aktion basierend auf dem aktuellen Zustand der Anwendung zu stoppen, ohne den Reducer mit bedingter Logik zu belasten. Und ich möchte diese Entscheidung auch nicht in die View-Schicht verlagern, wo der Action-Creator gefeuert wird. Mit Stent geschieht dies automatisch, da die Maschine nicht auf Aktionen reagiert, die nicht im aktuellen Zustand deklariert sind. Zum Beispiel:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } }});// this is finemachine.run();// This will do nothing because at this point// the machine is in a 'running' state and there is// only 'stop' action there.machine.jump();Die Tatsache, dass die Maschine zu einem bestimmten Zeitpunkt nur bestimmte Eingaben akzeptiert, schützt uns vor seltsamen Bugs und macht unsere Anwendungen vorhersehbarer.
Zustände, nicht Übergänge
Redux, wie auch Flux, lässt uns in Begriffen von Übergängen denken. Das mentale Modell der Entwicklung mit Redux ist ziemlich stark von Aktionen getrieben und wie diese Aktionen den Zustand in unseren Reduzierern transformieren. Das ist nicht schlecht, aber ich habe festgestellt, dass es sinnvoller ist, stattdessen in Zuständen zu denken – in welchen Zuständen sich die App befinden könnte und wie diese Zustände die geschäftlichen Anforderungen repräsentieren.
Fazit
Das Konzept der Zustandsautomaten in der Programmierung, insbesondere in der UI-Entwicklung, hat mir die Augen geöffnet. Ich habe angefangen, überall Zustandsautomaten zu sehen, und ich habe den Wunsch, immer zu diesem Paradigma zu wechseln. Ich sehe auf jeden Fall die Vorteile, die es hat, streng definierte Zustände und Übergänge zwischen ihnen zu haben. Ich bin immer auf der Suche nach Möglichkeiten, meine Anwendungen einfach und lesbar zu machen. Ich glaube, dass Zustandsautomaten ein Schritt in diese Richtung sind. Das Konzept ist einfach und gleichzeitig mächtig. Es hat das Potenzial, eine Menge Bugs zu eliminieren.