Hintergrund
Backpropagation ist eine gängige Methode zum Trainieren eines neuronalen Netzwerks. Es gibt keinen Mangel an Abhandlungen im Internet, die zu erklären versuchen, wie Backpropagation funktioniert, aber nur wenige, die ein Beispiel mit tatsächlichen Zahlen enthalten. Dieser Beitrag ist mein Versuch, die Funktionsweise anhand eines konkreten Beispiels zu erklären, mit dem die Leute ihre eigenen Berechnungen vergleichen können, um sicherzustellen, dass sie Backpropagation richtig verstehen.
Backpropagation in Python
Sie können mit einem Python-Skript herumspielen, das ich geschrieben habe und das den Backpropagation-Algorithmus in diesem Github Repo implementiert.
Visualisierung der Backpropagation
Für eine interaktive Visualisierung, die zeigt, wie ein neuronales Netzwerk lernt, schauen Sie sich meine Visualisierung des neuronalen Netzwerks an.
Zusätzliche Ressourcen
Wenn Sie dieses Tutorial nützlich finden und weiter über neuronale Netzwerke, maschinelles Lernen und Deep Learning lernen wollen, empfehle ich Ihnen das neue Buch von Adrian Rosebrock, Deep Learning for Computer Vision with Python. Ich habe das Buch wirklich genossen und werde bald eine vollständige Rezension veröffentlichen.
Übersicht
Für dieses Tutorial werden wir ein neuronales Netzwerk mit zwei Eingängen, zwei versteckten Neuronen und zwei Ausgangsneuronen verwenden. Zusätzlich werden die versteckten Neuronen und die Ausgangsneuronen einen Bias enthalten.
Hier ist die Grundstruktur:
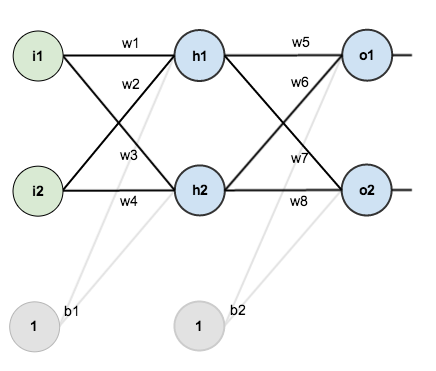
Um ein paar Zahlen zum Arbeiten zu haben, sind hier die anfänglichen Gewichte, die Verzerrungen und die Trainingsinputs/-outputs:

Das Ziel der Backpropagation ist es, die Gewichte zu optimieren, damit das neuronale Netz lernen kann, wie es beliebige Eingaben korrekt auf Ausgaben abbildet.
Für den Rest dieses Tutorials werden wir mit einem einzigen Trainingsset arbeiten: Bei Eingaben von 0,05 und 0,10 soll das neuronale Netz 0,01 und 0,99 ausgeben.
Der Vorwärtsdurchlauf
Zu Beginn sehen wir uns an, was das neuronale Netz bei den obigen Gewichten und Verzerrungen und den Eingaben von 0,05 und 0,10 derzeit vorhersagt. Dazu werden wir diese Eingaben vorwärts durch das Netz leiten.
Wir ermitteln die gesamte Netzeingabe für jedes Neuron der versteckten Schicht, zerquetschen die gesamte Netzeingabe mithilfe einer Aktivierungsfunktion (hier verwenden wir die logistische Funktion) und wiederholen den Vorgang dann mit den Neuronen der Ausgabeschicht.
Hier sehen Sie, wie wir die Gesamtnetzeingabe für 
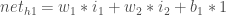

Wir zerlegen es dann mit der logistischen Funktion, um die Ausgabe von

Wenn man den gleichen Prozess für 
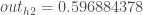
Wir wiederholen diesen Vorgang für die Neuronen der Ausgabeschicht und verwenden die Ausgaben der Neuronen der versteckten Schicht als Eingaben.
Hier ist die Ausgabe für 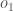



Und wenn wir den gleichen Prozess für 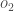
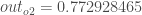
Berechnen des Gesamtfehlers
Wir können nun den Fehler für jedes Ausgangsneuron mit Hilfe der quadratischen Fehlerfunktion berechnen und diese addieren, um den Gesamtfehler zu erhalten:
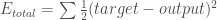
 ist enthalten, damit der Exponent beim späteren Differenzieren aufgehoben wird. Das Ergebnis wird schließlich ohnehin mit einer Lernrate multipliziert, so dass es keine Rolle spielt, dass wir hier eine Konstante einführen.
ist enthalten, damit der Exponent beim späteren Differenzieren aufgehoben wird. Das Ergebnis wird schließlich ohnehin mit einer Lernrate multipliziert, so dass es keine Rolle spielt, dass wir hier eine Konstante einführen.Zum Beispiel ist die Zielausgabe für

Wenn wir diesen Vorgang für

Der Gesamtfehler für das neuronale Netz ist die Summe dieser Fehler:

Der Rückwärtsdurchlauf
Unser Ziel bei der Backpropagation ist es, jedes der Gewichte im Netzwerk so zu aktualisieren, dass sie die tatsächliche Ausgabe näher an die Zielausgabe heranführen, wodurch der Fehler für jedes Ausgangsneuron und das Netzwerk als Ganzes minimiert wird.
Output Layer
Betrachten Sie 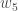
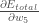
 wird gelesen als „die partielle Ableitung von
wird gelesen als „die partielle Ableitung von  nach
nach  „. Man kann auch sagen „die Steigung in Bezug auf „.
„. Man kann auch sagen „die Steigung in Bezug auf „.Durch Anwendung der Kettenregel wissen wir, dass:
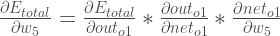
Visuell gesehen, machen wir Folgendes:

Wir müssen jeden Teil in dieser Gleichung herausfinden.
Erstens, wie stark ändert sich der Gesamtfehler in Bezug auf die Ausgabe?
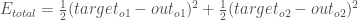
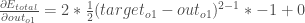

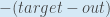 wird manchmal ausgedrückt als
wird manchmal ausgedrückt als 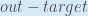
 nehmen, wird die Größe
nehmen, wird die Größe 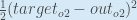 Null, weil sie nicht beeinflusst, was bedeutet, dass wir die Ableitung einer Konstanten nehmen, die Null ist.
Null, weil sie nicht beeinflusst, was bedeutet, dass wir die Ableitung einer Konstanten nehmen, die Null ist.Nächste Frage: Wie stark ändert sich der Ausgang von
Die partielle Ableitung der logistischen Funktion ist der Output multipliziert mit 1 minus dem Output:

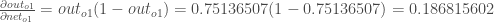
Schließlich, wie stark ändert sich der gesamte Netto-Input von 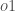
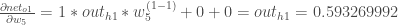
Alles zusammenfassen:


Sie werden diese Berechnung oft in Form der Delta-Regel kombiniert sehen:

Alternativ, haben wir 



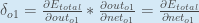
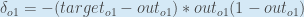
Daraus folgt:

Einige Quellen extrahieren das negative Vorzeichen aus 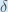
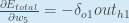
Um den Fehler zu verringern, subtrahieren wir dann diesen Wert von der aktuellen Gewichtung (optional multipliziert mit einer Lernrate, eta, die wir auf 0 setzen werden.5):

 (alpha), um die Lernrate darzustellen, andere verwenden
(alpha), um die Lernrate darzustellen, andere verwenden  (eta), und wieder andere verwenden sogar
(eta), und wieder andere verwenden sogar  (epsilon).
(epsilon).Wir können diesen Vorgang wiederholen, um die neuen Gewichte 
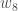
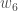
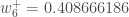


Wir führen die eigentlichen Aktualisierungen im neuronalen Netz durch, nachdem wir die neuen Gewichte haben, die in die Neuronen der versteckten Schicht führen (d. h., wir verwenden die ursprünglichen Gewichte, nicht die aktualisierten Gewichte, wenn wir unten mit dem Backpropagation-Algorithmus fortfahren).
Hintere Schicht
Als Nächstes setzen wir den Rückwärtsdurchlauf fort, indem wir neue Werte für 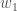


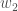
Im Großen und Ganzen müssen wir folgendes herausfinden:

Visuell:

Wir werden ein ähnliches Verfahren wie für die Ausgabeschicht verwenden, aber etwas anders, um der Tatsache Rechnung zu tragen, dass die Ausgabe jedes Neurons der versteckten Schicht zur Ausgabe (und damit zum Fehler) mehrerer Ausgangsneuronen beiträgt. Wir wissen, dass 




Beginnend mit 
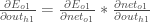
Wir können 

Und 

Einstecken:

Wenn wir den gleichen Prozess für 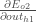

Daher:

Nun, da wir 


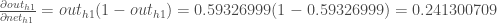
Wir berechnen die partielle Ableitung des gesamten Netzeingangs für


Zusammengefasst:
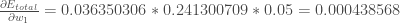
Sie könnten dies auch geschrieben sehen als:

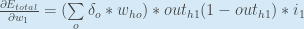

Wir können nun

Wiederhole dies für
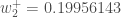

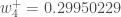
Zuletzt haben wir alle unsere Gewichte aktualisiert! Als wir ursprünglich die 0,05- und 0,1-Eingänge weiterleiteten, betrug der Fehler des Netzwerks 0,298371109. Nach dieser ersten Runde der Backpropagation ist der Gesamtfehler jetzt auf 0,291027924 gesunken. Das mag nicht viel erscheinen, aber nachdem dieser Prozess beispielsweise 10.000 Mal wiederholt wurde, sinkt der Fehler auf 0,0000351085. An diesem Punkt, wenn wir 0,05 und 0,1 vorwärts einspeisen, erzeugen die beiden Ausgänge Neuronen 0,015912196 (gegenüber dem 0,01-Ziel) und 0,984065734 (gegenüber dem 0,99-Ziel).
Wenn Sie es bis hierher geschafft haben und irgendwelche Fehler in den obigen Ausführungen gefunden haben oder Ihnen eine Möglichkeit einfällt, es für zukünftige Leser klarer zu machen, zögern Sie nicht, mir eine Nachricht zu schicken. Danke!