Statistische Definitionen >Faktorenanalyse
Inhalt:
- Was ist die Faktorenanalyse?
- Faktorladungen
- Mehrfache Faktorenanalyse
- Konfirmatorische Faktorenanalyse
- Exploratorische Faktorenanalyse
- Was ist die Generalized Procrustes Analysis (GPA)
- Was sind latente Variablen?
- Was sind manifeste Variablen?
Was ist die Faktorenanalyse?
Die Faktorenanalyse ist ein Weg, eine Masse von Daten zu nehmen und sie auf einen kleineren Datensatz zu schrumpfen, der besser verwaltbar und verständlicher ist. Es ist eine Möglichkeit, versteckte Muster zu finden, zu zeigen, wie sich diese Muster überschneiden und welche Merkmale in mehreren Mustern zu sehen sind. Es wird auch verwendet, um einen Satz von Variablen für ähnliche Elemente in der Menge zu erstellen (diese Sätze von Variablen werden Dimensionen genannt). Es kann ein sehr nützliches Werkzeug für komplexe Datensätze sein, die psychologische Studien, sozioökonomischen Status und andere involvierte Konzepte beinhalten. Ein „Faktor“ ist ein Satz von beobachteten Variablen, die ähnliche Antwortmuster aufweisen; sie sind mit einer versteckten Variable (einer sogenannten Confounding-Variable) verbunden, die nicht direkt gemessen wird. Faktoren werden nach Faktorladungen aufgelistet, oder wie viel Variation in den Daten sie erklären können.
Die zwei Arten: explorativ und konfirmatorisch.
- Explorative Faktorenanalyse ist, wenn Sie keine Ahnung haben, wie Ihre Daten strukturiert sind oder wie viele Dimensionen in einem Satz von Variablen sind.
- Die konfirmatorische Faktorenanalyse wird verwendet, wenn Sie eine bestimmte Vorstellung davon haben, wie Ihre Daten strukturiert sind oder wie viele Dimensionen in einem Satz von Variablen sind.
Faktorladungen
Bild:USGS.gov
Nicht alle Faktoren sind gleich; einige Faktoren haben mehr Gewicht als andere. Ein einfaches Beispiel: Stellen Sie sich vor, Ihre Bank führt eine telefonische Umfrage zur Kundenzufriedenheit durch und die Ergebnisse zeigen die folgenden Faktorladungen:
| Variable | Faktor 1 | Faktor 2 | Faktor 3 | Frage 1 | 0.885 | 0.121 | -0.033 |
|---|---|---|---|
| Frage 2 | 0.829 | 0.078 | 0.157 |
| Frage 3 | 0.777 | 0.190 | 0.540 |
Die Faktoren, die die Frage am meisten beeinflussen (und daher die höchsten Faktorladungen haben), sind fett gedruckt. Faktorladungen sind ähnlich wie Korrelationskoeffizienten, da sie von -1 bis 1 variieren können. Je näher die Faktoren bei -1 oder 1 liegen, desto stärker beeinflussen sie die Variable. Eine Faktorladung von Null würde keinen Effekt anzeigen.
Zurück zum Anfang
Mehrfache Faktorenanalyse
Diese Untergruppe der Faktorenanalyse wird verwendet, wenn Ihre Variablen in Variablengruppen strukturiert sind. Zum Beispiel könnten Sie einen Fragebogen zur Gesundheit von Schülern mit mehreren Items wie Schlafverhalten, Süchte, psychische Gesundheit oder Lernbehinderungen haben.
Die zwei Schritte, die bei der multiplen Faktorenanalyse durchgeführt werden, sind:
- Die Hauptkomponentenanalyse wird für jeden Datensatz durchgeführt. Dies ergibt einen Eigenwert, der zur Normalisierung der Datensätze verwendet wird.
- Die neuen Datensätze werden zu einer einzigen Matrix zusammengeführt und eine zweite, globale PCA wird durchgeführt.
Durchführung der Faktorenanalyse
Die Faktorenanalyse ist ein äußerst komplexes mathematisches Verfahren und wird mit Software durchgeführt.
Anleitungen für Stata finden Sie hier.
Anleitungen für Minitab finden Sie hier.
Für SPSS finden Sie diesen Artikel.
Der Kaiser-Meyer-Olkin-Test prüft, ob Ihre Daten für die FA geeignet sind.
Zurück zum Anfang
Was ist die konfirmatorische Faktorenanalyse?
Die konfirmatorische Faktorenanalyse ermöglicht es einem Forscher herauszufinden, ob eine Beziehung zwischen einem Satz von beobachteten Variablen (auch manifeste Variablen genannt) und den ihnen zugrunde liegenden Konstrukten besteht. Sie ist ähnlich wie die explorative Faktorenanalyse. Der Hauptunterschied zwischen den beiden ist:
- Wenn Sie Muster untersuchen wollen, verwenden Sie die EFA.
- Wenn Sie Hypothesentests durchführen wollen, verwenden Sie die CFA.
Die EFA liefert Informationen über die optimale Anzahl von Faktoren, die zur Darstellung des Datensatzes erforderlich sind. Bei der konfirmatorischen Faktorenanalyse können Sie die Anzahl der benötigten Faktoren angeben. CFA kann zum Beispiel Fragen beantworten wie „Misst meine Umfrage mit zehn Fragen genau einen bestimmten Faktor?“. Obwohl sie technisch auf jede Disziplin anwendbar ist, wird sie typischerweise in den Sozialwissenschaften eingesetzt.
Implementierung der Confirmatory Factor Analysis
Diane Suhr, PhD, schlägt auf der SAS-Website folgende Schritte vor:
- Führen Sie eine Literaturanalyse durch, um ein geeignetes Modell auszuwählen. Sie könnten z. B. ein Diagramm oder Gleichungen wählen.
- Bestimmen Sie, ob eindeutige Werte für die Schätzung der Populationsparameter möglich sind.
- Erheben Sie Ihre Daten.
- Führen Sie eine erste Datenanalyse durch, um Probleme wie fehlende Daten, Kollinearität oder Ausreißer zu überprüfen.
- Schätzen Sie die Populationsparameter.
- Bestimmen Sie, ob das von Ihnen gewählte Modell funktioniert. Wenn das Modell inakzeptabel ist, erwägen Sie die Durchführung einer erklärenden Faktorenanalyse.
- Interpretieren Sie Ihre Ergebnisse.
Nach Angaben von IBM hat die EFA die CFA als Mittel der Faktorenanalyse überholt. „Der vorherrschende CFA-Ansatz besteht heute darin, CFA als einen Spezialfall der Strukturgleichungsmodellierung (SEM) zu betrachten. Man spezifiziert die Faktorladungen als einen Satz von Regressionsaussagen vom Faktor zu den beobachteten Variablen.“ Mit EFA ist es möglich, ein paar Faktoren und eine bestimmte Rotation zu spezifizieren; Sie können dann Ihre Ergebnisse vergleichen, um zu sehen, ob sie zu Ihrem Modell passen.
Durchführung der CFA
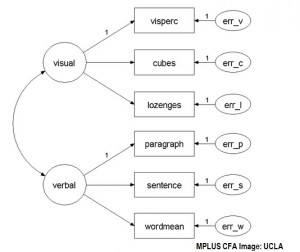
Für die Durchführung der konfirmatorischen Faktorenanalyse wird in der Regel eine Software benötigt. SAS kann zur Durchführung der CFA verwendet werden. Zum Zeitpunkt der Erstellung dieses Artikels ist SPSS nur auf EFA beschränkt.
- SAS CFA-Prozedur.
- AMOS-Anleitung (Download-Dokument von der East Carolina University).
- AMOS, LISREL, MPLUS-Prozeduren.
Zurück zum Anfang
Was ist eine explorative Faktorenanalyse?
Die explorative Faktorenanalyse (EFA) wird verwendet, um die zugrunde liegende Struktur einer großen Menge von Variablen zu finden. Sie reduziert die Daten auf einen viel kleineren Satz von zusammenfassenden Variablen.
EFA ist fast identisch mit der Konfirmatorischen Faktorenanalyse(CFA). Beide Techniken können (vielleicht überraschenderweise) zur Bestätigung oder zur Exploration verwendet werden. Die Gemeinsamkeiten sind:
- Untersuchen Sie die interne Reliabilität einer Messung.
- Untersuchen Sie Faktoren oder theoretische Konstrukte, die durch Item-Sets repräsentiert werden. Sie gehen davon aus, dass die Faktoren nicht korreliert sind.
- Untersuchen Sie die Qualität einzelner Items.
Es gibt jedoch einige Unterschiede, vor allem in Bezug darauf, wie Faktoren behandelt/verwendet werden. EFA ist im Grunde ein datengesteuerter Ansatz, bei dem alle Items auf alle Faktoren laden können, während Sie bei CFA angeben müssen, welche Faktoren geladen werden sollen. EFA ist eine gute Wahl, wenn Sie keine Ahnung haben, welche gemeinsamen Faktoren vorhanden sein könnten. EFA kann eine große Anzahl von möglichen Modellen für Ihre Daten generieren, was nicht möglich ist, wenn ein Forscher Faktoren spezifizieren muss. Wenn Sie eine Vorstellung davon haben, wie die Modelle aussehen, und Sie Ihre Hypothesen über die Datenstruktur testen wollen, ist CFA ein besserer Ansatz.
Was ist die verallgemeinerte Prokrustes-Analyse (GPA)?
Die Prokrustes-Analyse ist eine Möglichkeit, zwei Sätze von Konfigurationen oder Formen zu vergleichen. Ursprünglich entwickelt, um zwei Lösungen aus der Faktorenanalyse zu vergleichen, wurde das Verfahren zur verallgemeinerten Prokrustes-Analyse erweitert, damit mehr als zwei Formen verglichen werden können. Die Formen werden an einer Zielform oder aneinander ausgerichtet.
GPA verwendet geometrische Transformationen (d. h. isotrope Umskalierung, Reflexion, Rotation oder Translation) von Matrizen, um die Datensätze zu vergleichen. Das folgende Bild zeigt eine Reihe von Transformationen auf ein grünes Zieldreieck.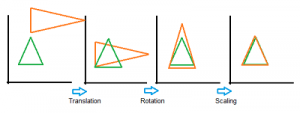
Die Konsensmatrix ist (wie der Name schon sagt), das Ergebnis der Durchschnitte aller Eingangsmatrizen. Die Matrizen, die während des Prozesses der verallgemeinerten Prokrustes-Analyse gebildet werden, können in die Hauptkomponentenanalyse eingegeben und auf den zweidimensionalen Raum projiziert werden, um leicht verständliche Ergebnisse zu erhalten.
Verwendung in der sensorischen Profilierung
Die verallgemeinerte Prokrustes-Analyse ist eine Möglichkeit, eine zugrundeliegende Struktur in der sensorischen Profilierung zu finden, die in zwei Kategorien fällt: die konventionelle Profilierung und die Free-Choice-Profilierung.
Bei der konventionellen Profilerstellung wird den Beurteilern ein fester Satz an beschreibenden Begriffen zur Verfügung gestellt. Die Bewerter sind in der Regel gut ausgebildete Personen. Sie könnten zum Beispiel drei Experten nach ihrer Meinung zu Körper, Geruch und Geschmack von vier Weinmarken fragen. Die festgelegten Beschreibungen könnten z.B. knackig, kantig und buttrig sein. Die Ergebnisse können gemittelt werden, so dass es möglich ist, die Faktorenanalyse oder die Hauptkomponentenanalyse – wie auch die GPA – zur Analyse des Tests zu verwenden.
Das Free-Choice-Profiling gibt den Befragten die Freiheit, die Fragen in ihren eigenen beschreibenden Begriffen zu beantworten. Da es keine festen Begriffe gibt, die gemittelt werden müssen, ist es nicht möglich, Faktorenanalyse oder PCA zu verwenden. K-Sets-Methoden, wie PCA, werden bei dieser Art von Free-Choice-Profiling eingesetzt.
Die Kategorien sind die Dimensionen der Generalized Procrustes Analysis. Im Idealfall ist die Anzahl der Dimensionen überall gleich (in diesem Beispiel würde das bedeuten, dass der Experte in allen drei Bereichen eine Bewertung abgegeben hat). Es ist jedoch möglich, die verallgemeinerte Procrustes-Analyse mit ungleichen Dimensionen auszuführen.
Zurück zum Anfang
Was sind latente Variablen?
 Eine latente Variable oder „versteckte“ Variable wird im Allgemeinen als eine Variable betrachtet, die nicht direkt messbar oder beobachtbar ist. Zum Beispiel sind der Grad der Neurose, Gewissenhaftigkeit oder Offenheit einer Person alles latente Variablen. Obwohl Sie diese zugrundeliegenden Variablen nicht sehen können (sie sind nicht Teil des Datensatzes eines Experiments), können sie Effekte in Ihren experimentellen Ergebnissen verursachen. Latente Variablen sind auch bekannt als:
Eine latente Variable oder „versteckte“ Variable wird im Allgemeinen als eine Variable betrachtet, die nicht direkt messbar oder beobachtbar ist. Zum Beispiel sind der Grad der Neurose, Gewissenhaftigkeit oder Offenheit einer Person alles latente Variablen. Obwohl Sie diese zugrundeliegenden Variablen nicht sehen können (sie sind nicht Teil des Datensatzes eines Experiments), können sie Effekte in Ihren experimentellen Ergebnissen verursachen. Latente Variablen sind auch bekannt als:
- Konstrukte oder hypothetische Konstrukte.
- Faktoren.
- Versteckte Variablen.
- Hypothetische Variablen.
- True Scores.
- Ungemessene Variablen.
- Unbeobachtete Variablen.
Eines der frühesten Beispiele für eine latente Variable wurde 1904 veröffentlicht, als Spearman die Intelligenz mithilfe der Faktorenanalyse maß. Eine genauere Definition von latenten Variablen wird manchmal verwendet. Zum Beispiel beschreibt MacCallum & Austin(2000) diese Variablen als „hypothetische Konstrukte, die nicht direkt gemessen werden können.“ Sie sind hypothetisch, weil sie nur in den Köpfen des Forschers existieren.
Die latente Variable in der statistischen Modellierung
Latente Variablen werden manchmal in statistischen Modellierungstechniken wie der Faktorenanalyse verwendet, wo sie durch Modellierungstechniken abgeleitet werden können. Latente Variablen sind in fast allen Regressionsanalysen allgegenwärtig, da alle additiven Fehlerterme nicht messbar (und daher latent) sind.
Statistische Modellierungsmethoden, die oft zur Identifizierung latenter Variablen verwendet werden, umfassen:
- EM-Algorithmen.
- Faktorenanalyse.
- Hidden Markov Models.
- Latent Semantic Analysis.
- Principal Component Analysis.
- Structural Equation Modeling.
Eine latente Variable kann auch vorhanden sein (und in ein Modell aufgenommen werden), wenn es kein Ziel gibt, sie tatsächlich zu messen. Melanie Wall von der Columbia University nennt die folgenden drei Beispiele für latente Variablen, die nicht gemessen werden sollen:
- Unbeobachtete Heterogenität (z.B.. Schwächen in Überlebensanalysen, zufällige Effekte in Längsschnittdaten oder geclusterten Daten)
- Fehlende Daten
- Kontrafaktische oder ‚potentielle Ergebnisse‘
Zurück zum Anfang
Was sind manifeste Variablen?
Manifeste Variablen (auch beobachtbare Variablen genannt) können direkt gemessen oder beobachtet werden. Sie sind das Gegenteil von latenten Variablen. Zum Beispiel sind Alter und Geschlecht beobachtbare Variablen. Es ist jedoch selten, dass man sich über eine Variable zu 100 % sicher sein kann; selbst das „Geschlecht“, wenn es beobachtet wird, ist nicht zu 100 % sicher, da Personen auf ihrem Formular lügen, ihr wahres Geschlecht verschleiern oder eine Transgender-Person sein können. Daher sollten Sie, wann immer möglich, latente Variablen verwenden.
Referenz:
MacCallum RC, Austin JT. 2000. Applications of structural equation modeling in psychological research. Annu. Rev. Psychol. 51:
201-26
Stephanie Glen. „Factor analysis: Easy Definition“ von StatisticsHowTo.com: Elementare Statistik für den Rest von uns! https://www.statisticshowto.com/factor-analysis/
——————————————————————————
Brauchen Sie Hilfe bei einer Hausaufgabe oder Testfrage? Mit Chegg Study können Sie Schritt-für-Schritt-Lösungen zu Ihren Fragen von einem Experten auf dem Gebiet erhalten. Ihre ersten 30 Minuten mit einem Chegg Tutor sind kostenlos!