Berechnung der Chi-Quadrat-Statistik für Kreuztabellen
Die Chi-Quadrat-Statistik wird berechnet, indem zuerst ein Chi-Quadrat-Wert für jede einzelne Zelle der Tabelle berechnet wird und diese dann aufsummiert werden, um einen gesamten Chi-Quadrat-Wert für die Tabelle zu bilden. Der Chi-Quadrat-Wert für die Zelle wird berechnet als: (Beobachteter Wert – Erwarteter Wert)2 / (Erwarteter Wert). Die Chi-Quadrat-Berechnungen sind grau hervorgehoben.
In dieser Beispieltabelle sehen wir, dass der Chi-Quadrat-Wert für die Tabelle 19,35 beträgt und eine zugehörige Wahrscheinlichkeit hat, dass er weniger als einmal in 1000 Fällen zufällig auftritt. Wir verwerfen daher die Nullhypothese, dass es keinen Unterschied gibt, und schließen daraus, dass es eine Beziehung zwischen den Variablen geben muss. Wir können die Beziehung an zwei Stellen in der Tabelle beobachten.
Am offensichtlichsten ist der für jede Zelle berechnete Chi-Quadrat-Wert. Wir stellen fest, dass die Zellen „Red Socks und Boston“, „Blue Jays und Montreal“ und „Red Socks und Montpellier, Vermont“ die drei Zellen waren, in denen die Anzahl der beobachteten Befragten größer war als erwartet. Wir stellen außerdem fest, dass bei der Betrachtung der erwarteten und beobachteten Häufigkeiten die Häufigkeiten von „Yankees und Montreal“, „Red Socks und Montpellier, Vermont“ und „Red Socks und Montreal“ geringer waren als erwartet.
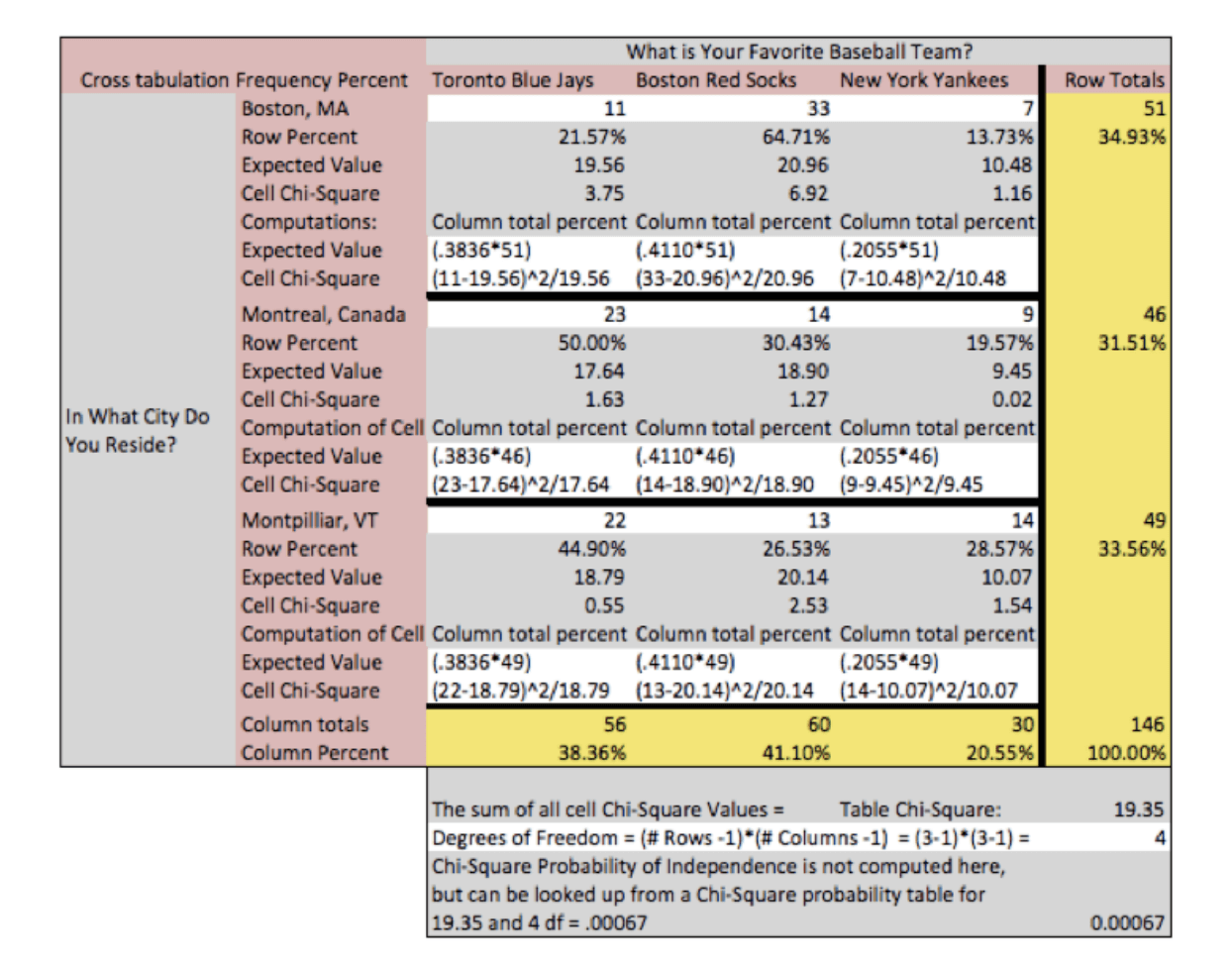
Da die Chi-Quadrat-Werte der Zelle und die erwarteten Werte oft nicht angezeigt werden, kann man dieselben Beziehungen beobachten, indem man die Prozentwerte der Spaltensumme mit den Prozentwerten der Zelle (der Zeilensumme) vergleicht. In der Zelle „Rote Socken und Boston“ würden wir 41,10 % mit 64,71 % vergleichen und feststellen, dass mehr Fans der Roten Socken Boston mögen als erwartet. Bei der Interpretation von Beziehungen, die in einer statistischen Analyse gefunden werden, ist Vorsicht geboten. Wir wollen oft „erklären“ oder „Kausalität“ aus Analysen schließen, wenn die Daten entweder nicht dafür ausgelegt sind oder nicht die Kraft haben, solche Schlussfolgerungen zu unterstützen.
In der aktuellen Tabelle sehen wir, dass „Rote Socken und Boston“ das größte Delta zwischen der Anzahl der beobachteten und der erwarteten Befragten für jede Teampräferenz und jeden Wohnort aufweist. Wir müssen jedoch vorsichtig sein, wenn wir daraus schließen, dass die Red Socks die Befragten dazu veranlasst haben, nach Boston zu ziehen, oder dass Boston als Wohnort die Fantreue verursacht. Rote Socken und Boston sind die am häufigsten beobachtete Fan- und Stadtbeziehung, sind aber höchstwahrscheinlich völlig unabhängig, wenn man andere Konzepte oder Beziehungen betrachtet.
Kreuztabellen und Chi-Quadrat sind leistungsfähige Methoden, um Ihre Umfragedaten zu analysieren. Ein weiteres beliebtes Werkzeug, das in der Forschung eine Rolle spielt, ist die Conjoint-Analyse.