Wenn Sie meine Einführung in Hadoop/Spark-Dateiformate gelesen haben, werden Sie wissen, dass es mehrere Möglichkeiten gibt, Daten in HDFS, S3 oder Blob-Storage zu speichern, und jeder dieser Dateitypen hat unterschiedliche Eigenschaften, die sie für unterschiedliche Dinge gut (oder schlecht) machen.
Während dieser Artikel kein technischer Tiefgang ist, werde ich Ihnen einen Überblick darüber geben, warum (und wie) Sie Parquet gegenüber einem anderen beliebten Format, Avro, verwenden sollten.
Was ist Parquet?
Auf einer hohen Ebene ist Parquet ein Dateiformat zum Speichern strukturierter Daten. Zum Beispiel können Sie Parquet verwenden, um eine Reihe von Datensätzen zu speichern, die wie folgt aussehen:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Sie könnten diese Daten tatsächlich in fast jedem Dateiformat speichern, eine leserfreundliche Art, diese Daten zu speichern, ist in einer CSV- oder TSV-Datei. Hier sehen Sie, wie einige Daten in diesem Schema in einem CSV-Format aussehen könnten:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, In einer JSON-Flat-Datei würden wir jede Zeile als JSON-Objekt speichern:
Im Gegensatz dazu ist hier ein Screenshot der gleichen Daten in einem anschaulichen Columnar-Dateiformat, das ich Columnar CSV (CCSV) nenne:
Verwirrt über Columnar-Dateiformate? Lesen Sie meine Einführung in Columnar-Dateiformate, bevor Sie weitermachen
Ganz anders, oder? Parquet geht noch einen Schritt weiter – es ist ein binärbasiertes Format, kein textbasiertes Format. Keine Sorge, es gibt viele Tools, mit denen Sie Parquet-Dateien inspizieren und lesen und die Ergebnisse sogar in das gute alte JSON exportieren können. Zum Beispiel Parquet Tools
Parquet kümmert sich um Ihr Schema
Eine Einschränkung von CSV/TSV-Daten ist, dass Sie nicht wissen, wie das genaue Schema aussehen soll, oder den gewünschten Typ jedes Feldes.
Anhand unseres obigen Beispiels, ohne das Schema, sollten die ‚True‘-Werte in boolean umgewandelt werden? Wie können wir sicher sein, ohne das Schema vorher zu kennen?
JSON verbessert CSV, da jede Zeile einen Hinweis auf das Schema liefert, aber ohne eine spezielle Header-Zeile gibt es keine Möglichkeit, ein Schema für jeden Datensatz in der Datei abzuleiten, und es ist nicht immer klar, als welcher Typ ein ‚Null‘-Wert interpretiert werden soll.
Avro und Parquet hingegen verstehen das Schema der Daten, die sie speichern. Wenn Sie eine Datei in diesen Formaten schreiben, müssen Sie Ihr Schema angeben. Wenn Sie die Datei zurücklesen, sagt sie Ihnen das Schema der darin gespeicherten Daten. Das ist super nützlich für ein Framework wie Spark, das diese Informationen nutzen kann, um Ihnen mit minimalem Aufwand einen vollständig geformten Datenrahmen zu liefern.
Lassen Sie uns über Parquet vs. Avro sprechen
Auf den ersten Blick sind sich Avro und Parquet ähnlich, sie schreiben beide das Schema ihrer eingeschlossenen Daten in einen Datei-Header und kommen gut mit Schema-Drift (Hinzufügen/Entfernen von Spalten) zurecht. Sie sind sich in dieser Hinsicht so ähnlich, dass Parquet sogar nativ Avro-Schemata unterstützt, so dass Sie Ihre Avro-Pipelines im Handumdrehen in die Parquet-Speicherung migrieren können.
Der große Unterschied zwischen den beiden Formaten besteht darin, dass Avro Daten ZEILEWEISE speichert, während Parquet Daten SPALTENWEISE speichert.
- Oh hai! Vergessen Sie nicht meinen Leitfaden zu kolumnaren Dateiformaten, wenn Sie mehr darüber erfahren wollen
Vorteile von Parquet gegenüber Avro
Um meinen Leitfaden zu kolumnaren Dateiformaten zu rekapitulieren, die Vorteile von Parquet (und kolumnaren Dateiformaten im Allgemeinen) sind hauptsächlich zwei:
- Reduzierte Speicherkosten (typischerweise) im Vergleich zu Avro
- 10-100-fache Verbesserung beim Lesen von Daten, wenn Sie nur wenige Spalten benötigen
Ich kann den Vorteil einer 100-fachen Verbesserung des Satzdurchsatzes gar nicht hoch genug einschätzen. Sie stellt eine wirklich massive und grundlegende Verbesserung für Datenverarbeitungspipelines dar, die nur schwer zu übersehen ist.
Hier ist eine Illustration dieses Vorteils aus einer Cloudera-Fallstudie aus dem Jahr 2016 mit einem kleinen Datensatz von weniger als 200 GB.
Beim einfachen Zählen von Zeilen bläst Parquet Avro weg, dank der Metadaten, die Parquet im Header von Zeilengruppen speichert.
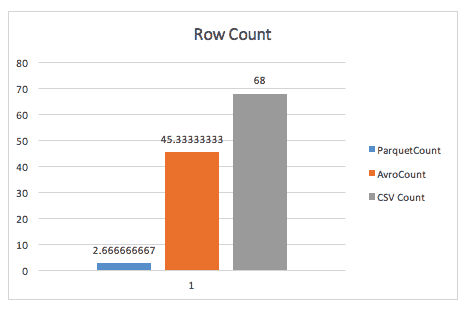
Bei der Ausführung einer Group-by-Abfrage ist Parquet immer noch fast 2x schneller (obwohl ich mir über die genaue Abfrage, die hier verwendet wurde, nicht sicher bin).
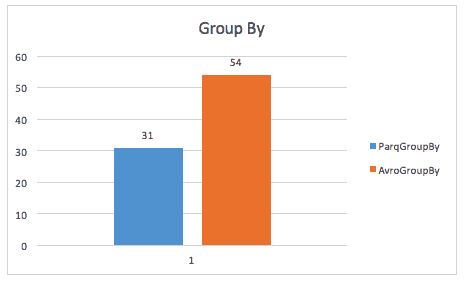
Die gleiche Fallstudie findet auch Verbesserungen beim Speicherplatz und sogar beim Scannen einer ganzen Tabelle, was wahrscheinlich darauf zurückzuführen ist, dass Spark eine kleinere Datenmenge scannen muss.
Vorteile von Avro gegenüber Parquet
Ich habe gehört, dass einige Leute für Avro gegenüber Parquet argumentieren. Solche Argumente basieren typischerweise auf zwei Punkten:
- Wenn Sie ganze Datensätze auf einmal lesen, gewinnt Avro in der Leistung.
- Die Schreibzeit ist beim Schreiben von Parquet-Dateien gegenüber Avro-Dateien drastisch erhöht
Während diese beiden Punkte gültig sind, sind sie kleine Fußnoten gegenüber den Leistungsverbesserungen von Parquet insgesamt. Es gibt viele online verfügbare Benchmarks für Avro vs. Parquet, aber lassen Sie mich ein Diagramm aus einer Präsentation von Hortonworks aus dem Jahr 2016 zeichnen, in dem die Leistung des Dateiformats in verschiedenen Situationen verglichen wird.
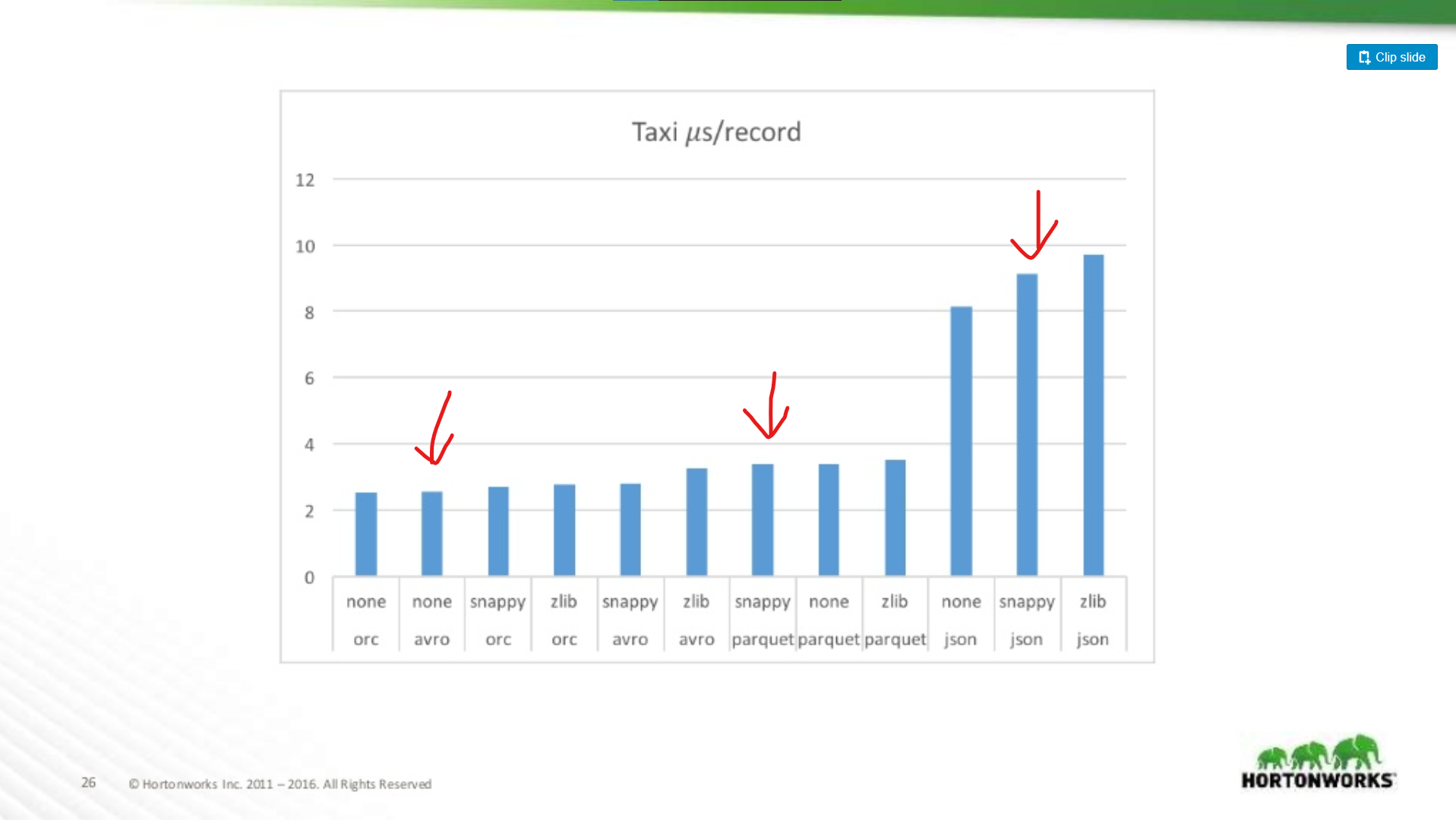
Wie viel schlechter ist Parquet für Scans ganzer Datensätze?
Hier vergleichen wir die Leistung von Avro, JSON und Parquet auf einem Taxi-Datensatz mit ~18 Spalten. In diesem Test wurden ganze Datensätze als Teil eines MapReduce-Jobs gelesen, diese Art von Arbeitslast ist die Worst-Case-Performance von Parquet, und hier entspricht sie fast der Leseleistung von Avro.
Am anderen Ende des Spektrums wurde gegen einen Github-Datensatz gelaufen, der extreme 704 Spalten an Daten pro Datensatz enthielt. Hier sehen wir einen signifikanteren Vorteil für Avro:
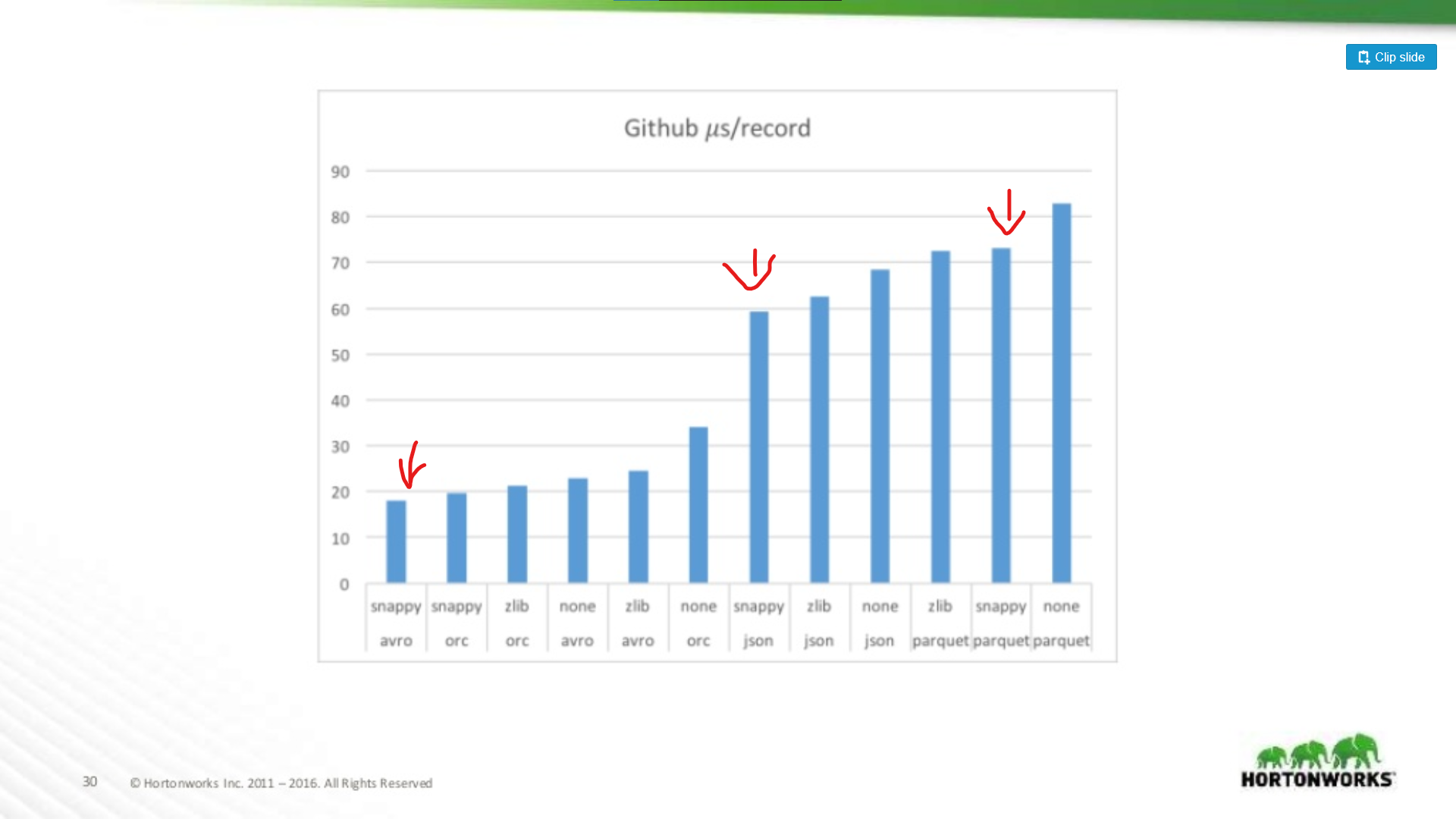
Je größer also Ihr Datensatz ist, desto schlechter wird Parquet beim Scannen ganzer Datensätze (was Sinn macht). Dies ist ein extremes Beispiel, die meisten Datensätze sind nicht 700 Spalten breit, für alles, was vernünftig ist (< 100), ist die Leseleistung von Parquet nahe genug an Avro, um nicht ins Gewicht zu fallen.
Parquet-Investitionen
Das heißt, dass die Abschwächung der negativen Eigenschaften von Parquet ein Schwerpunkt für erhebliche Investitionen ist. Siehe zum Beispiel diesen Artikel von Cloudera über die Verwendung von Vectorization, um den CPU-Overhead von Parquet zu begrenzen.
Ich sehe immer noch einige Leute, die für Avro gegenüber Parquet argumentieren, auch wenn Full-Record-Reads in Avro langsamer sind. Meine Meinung ist, dass Speicher billig ist! CPUs sind es nicht. Derselbe Artikel zeigt einen Leistungsvorteil von über 200x, wenn nur eine einzige Spalte aus der Datei gelesen wird. Das ist wirklich signifikant, und wenn Ihr Datensatz wächst, wird er eine beträchtliche Menge an Rechenressourcen einsparen.
Parquet ist wahrscheinlich so oder so die richtige Wahl
Wenn ein Datensatz also nur für MapReduce gedacht ist, sollte er dann in Avro laufen? Nein. Es ist ungemein hilfreich, in einen Datensatz „hineinschauen“ zu können und schnell Informationen über seinen Inhalt zu finden, außerdem erweitern viele MapReduce-Frameworks ihre Parquet-Unterstützung um Predicate-Pushdown. Parquet ist nicht nur für Analytics!
Selbst wenn Sie die Laufzeit Ihrer Produktionsjobs ignorieren, lassen Sie mich einige meiner bevorzugten Möglichkeiten zur Verwendung von Parquet außerhalb von Analytics-Workloads skizzieren:
-
Datenvalidierung – müssen Sie einige grobe Zählungen durchführen, um zu überprüfen, ob Ihre Daten vollständig sind? Solche Prüfungen können mit Parquet in wenigen Sekunden durchgeführt werden, selbst bei einem 1 TB großen Datensatz.
-
Debugging – hat Ihre Pipeline das Richtige getan? Hat sie die richtigen Datensätze hinzugefügt/entfernt/geändert? Mit Parquet können Sie schnell und einfach Informationen (z. B. alle eindeutigen Werte einer Spalte) in wenigen Sekunden erfassen, ohne die gesamte Datei zu scannen.
-
Schnelle Extraktion von Metriken – Sie möchten in Ihrem Überwachungssystem eine Zählung einer Teilmenge von Datensätzen in Ihrem Dataset aufzeichnen? Früher habe ich diese Informationen durch Ausführen einer Folgepipeline erfasst, aber mit Parquet ist es eine sehr schnelle Abfrage über Hive oder Spark SQL.
-
Weniger Redundanz – Sie benötigen einen ähnlichen Datensatz für zwei verschiedene Pipelines? Anstatt für jede einen eigenen Datensatz zu erstellen, können Sie mit Parquet einfach einen größeren, umfassenden Datensatz dynamisch abfragen, ohne die Nachteile des Scannens einer ganzen Datei.
-
Analytics – Ok, ich habe geschummelt und es trotzdem reingeschrieben. Ja, Parquet ist AMAZING für Analytik, jeder, der SQL-Abfragen durchführt, wird es Ihnen danken, dass Sie ihm Stunden am Tag vor einer SQL-Eingabeaufforderung ersparen, wenn seine Abfragen bis zu 1000x schneller laufen.
Meine Meinung: Benutzen Sie einfach Parquet
Während ich denke, dass es Anwendungsfälle für Avro gegenüber Parquet gibt, werden diese Anwendungsfälle immer weniger.
- Industrie-Tools schließen sich um Parquet als Standard-Datenspeicherformat zusammen. Sehen Sie sich zum Beispiel Amazon Web Services an. Sie geben Ihnen einen Dump der Nutzungsdaten in Parquet (oder CSV), und ihr EMR-Produkt bietet spezielle Schreiboptimierungen für Parquet. Das Gleiche gilt nicht für Avro.
- Frameworks wie MapReduce treten zugunsten dynamischerer Frameworks wie Spark zur Seite, diese Frameworks bevorzugen einen „Datenrahmen“-Programmierstil, bei dem Sie nur die benötigten Spalten verarbeiten und den Rest ignorieren. Das ist großartig für Parquet.
- Parquet ist einfach flexibler. Auch wenn Sie vielleicht nicht immer eine Sparse-Query in einem Datensatz benötigen, ist die Möglichkeit dazu in einer Reihe von Situationen verdammt nützlich. Das können Sie mit Avro, CSV oder JSON einfach nicht tun.