Se leu a minha introdução aos formatos de ficheiro Hadoop/Spark, estará ciente de que existem múltiplas formas de armazenar dados em HDFS, S3, ou Blob storage, e cada um destes tipos de ficheiro tem propriedades diferentes que os tornam bons (ou maus) em coisas diferentes.
Embora este artigo não seja um aprofundamento técnico, vou dar-lhe o resumo do porquê (e como) deve usar Parquet sobre outro formato popular, Avro.
O que é Parquet?
A um nível elevado, Parquet é um formato de ficheiro para armazenamento de dados estruturados. Por exemplo, pode usar o parquet para armazenar um monte de registos que se pareçam com isto:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Poderia, de facto, armazenar estes dados em quase qualquer formato de ficheiro, uma forma amigável de armazenar estes dados é num ficheiro CSV ou TSV. Eis o que alguns dados neste esquema podem parecer num formato CSV:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, Num ficheiro plano JSON, armazenaríamos cada linha como um objecto JSON:
Em contraste, aqui está uma captura de ecrã dos mesmos dados num formato de ficheiro colunar ilustrativo a que chamo CSV Colunar (CCSV):
Confused about Columnar file formats? Leia a minha introdução aos formatos de ficheiro colunar antes de ir mais longe
Totally different right? Parquet vai um passo além – é um formato baseado em binários, não um formato baseado em texto. Não se preocupe, há muitas ferramentas que pode utilizar para inspeccionar e ler ficheiros Parquet e até exportar os resultados para o bom velho JSON. Por exemplo, Parquet Tools
Parquet Cares About Your Schema
Uma limitação dos dados CSV/TSV é que não sabe qual é o esquema exacto, ou o tipo desejado de cada campo.
Usando o nosso exemplo acima, sem o esquema, será que os valores ‘Verdadeiros’ devem ser lançados para booleano? Como podemos ter a certeza sem conhecer previamente o esquema?
JSON melhora o CSV uma vez que cada linha fornece alguma indicação do esquema, mas sem uma linha de cabeçalho especial, não há forma de derivar um esquema para cada registo no ficheiro, e nem sempre é claro que tipo de valor ‘nulo’ deve ser interpretado como.
Avro e Parquet, por outro lado, entendem o esquema dos dados que armazenam. Quando se escreve um ficheiro nestes formatos, é necessário especificar o esquema. Quando lê o ficheiro de volta, ele diz-lhe o esquema dos dados armazenados no seu interior. Isto é super útil para uma estrutura como a Spark, que pode utilizar esta informação para lhe dar uma estrutura de dados totalmente formada com um esforço mínimo.
Vamos falar de Parquet vs Avro
Na sua cara, Avro e Parquet são semelhantes, ambos escrevem o esquema dos seus dados anexos num cabeçalho de ficheiro e lidam bem com o desvio do esquema (adição/remoção de colunas). São tão semelhantes a este respeito que Parquet até suporta nativamente esquemas Avro, pelo que pode migrar as suas condutas Avro para o armazenamento Parquet numa pitada.
A grande diferença nos dois formatos é que Avro armazena dados POR ROW, e Parquet armazena dados POR COLUMN..
- Oh hai! Não se esqueça do meu guia de formatos de ficheiro colunar se quiser saber mais sobre eles
Benefícios de Parquet sobre Avro
Para recapitular no meu guia de formatos de ficheiro colunar, a vantagem de Parquet (e formatos de ficheiro colunar em geral) são principalmente duas dobras:
- Custos de armazenamento reduzidos (tipicamente) vs Avro
- 10-100x de melhoria na leitura de dados quando são necessárias apenas algumas colunas
Não posso exagerar o benefício de uma melhoria de 100x no rendimento recorde. Proporciona uma melhoria verdadeiramente maciça e fundamental aos pipelines de processamento de dados que é muito difícil de ignorar.
Aqui está uma ilustração deste benefício de um estudo de caso da Cloudera em 2016 num pequeno conjunto de dados de menos de 200GB.
Quando simplesmente se contam linhas, Parquet sopra Avro, graças aos metadados que Parquet armazena no cabeçalho dos grupos de linhas.
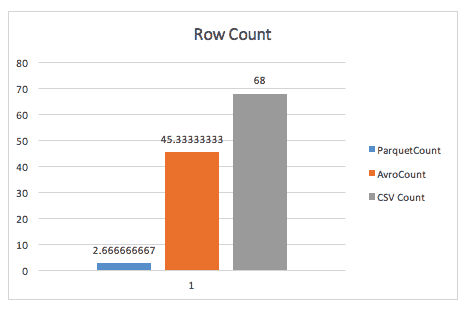
Ao executar uma consulta grupo a grupo, Parquet ainda é quase 2x mais rápido (embora não tenha a certeza da consulta exacta aqui utilizada).
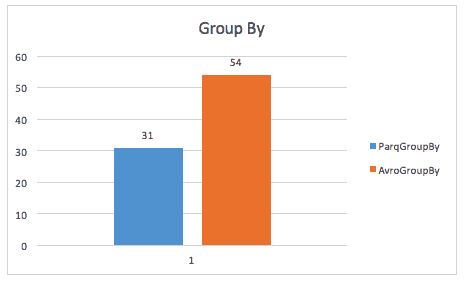
O mesmo estudo de caso também encontra melhorias no espaço de armazenamento, e mesmo em varreduras de mesa completa, provavelmente devido ao Spark ter de digitalizar um tamanho de dados mais pequeno.
Benefícios do Avro sobre Parquet
Escutei algumas pessoas argumentarem a favor do Avro vs Parquet. Tais argumentos são tipicamente baseados em dois pontos:
- Quando se lê registos inteiros de uma só vez, Avro ganha em desempenho.
- O tempo de escrita é aumentado drasticamente para escrever ficheiros Parquet vs Avro
-
Validação de dados – precisa de fazer algumas contagens aproximadas para verificar se os seus dados estão completos? Tais verificações podem ser feitas em poucos segundos com Parquet, mesmo com um conjunto de dados 1TB.
-
Debugging – o seu pipeline fez a coisa certa? Adicionou/removeu/modificou os registos correctos? Com o parquet pode capturar informação rápida e fácil (como todos os valores únicos de uma coluna) em poucos segundos sem digitalizar o ficheiro inteiro.
-
Extracção rápida de métricas – quer registar no seu sistema de monitorização uma contagem de um subconjunto de registos no seu conjunto de dados? Anteriormente capturei esta informação ao executar um pipeline de seguimento, mas com Parquet é uma consulta muito rápida através de Hive ou Spark SQL.
-
Sem redundância – Precisa de um conjunto de dados semelhante para dois pipelines diferentes? Em vez de construir um conjunto de dados distinto para cada um, Parquet permite-lhe apenas consultar dinamicamente um conjunto de dados maior e mais abrangente sem as penalidades de digitalizar um ficheiro inteiro.
-
Analytics – Ok, eu fiz batota e coloquei-o de qualquer forma. Sim, Parquet é AMAZENTE para análises, qualquer pessoa que execute consultas SQL agradecer-lhe-á por poupar horas por dia em frente a uma solicitação SQL, quando as suas consultas correm até 1000x mais depressa.
Embora estes dois pontos sejam válidos, são notas de rodapé menores contra as melhorias de desempenho de Parquet em geral. Há muitas referências disponíveis online para Avro vs Parquet, mas deixe-me desenhar um gráfico de uma apresentação Hortonworks 2016 comparando o desempenho do formato de ficheiro em várias situações.
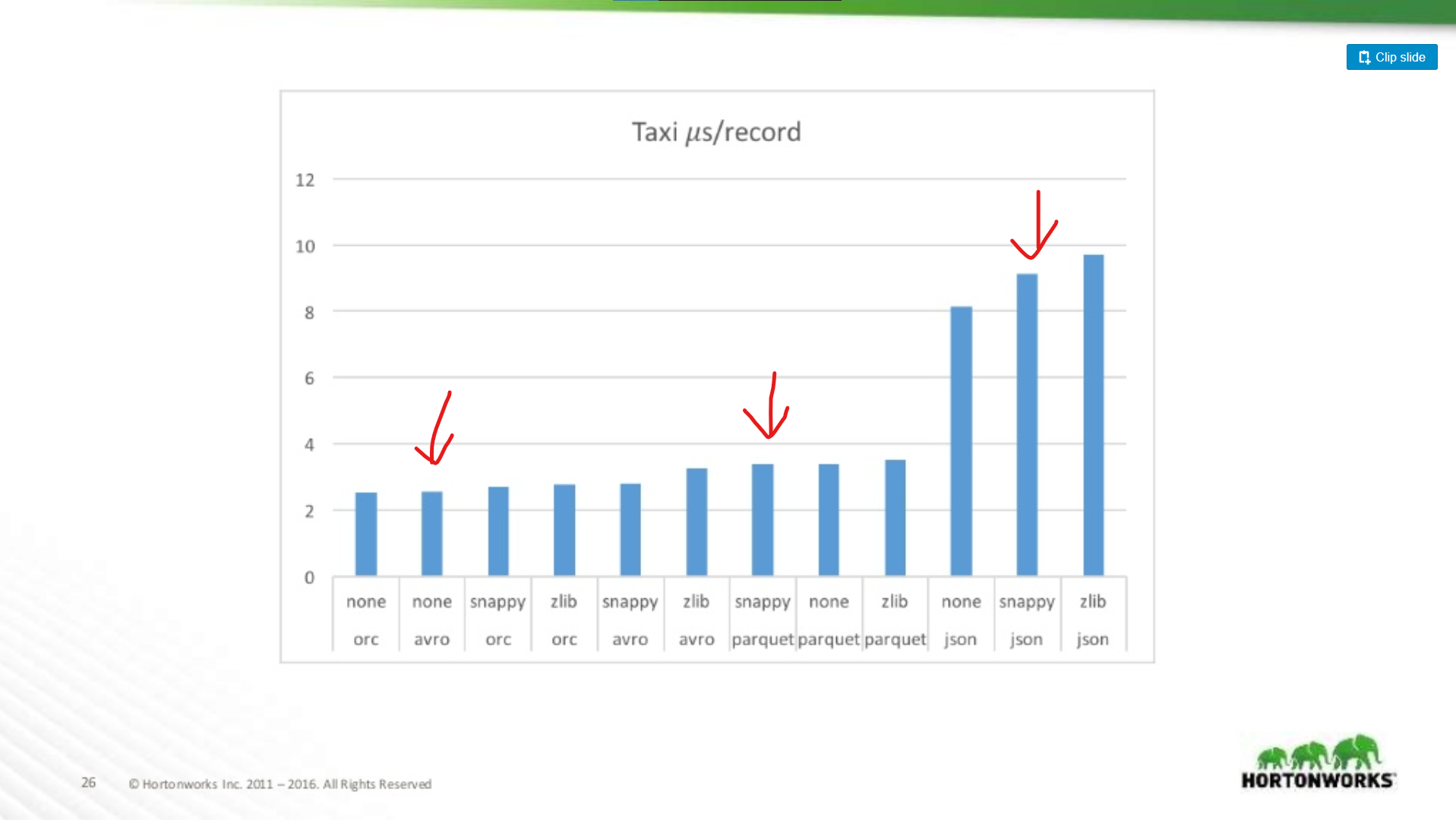
Quanto pior é Parquet para digitalizações de registos inteiros?
Aqui comparamos o desempenho de Avro, JSON, e Parquet num conjunto de dados de táxi contendo ~18 colunas. Neste teste eles estavam a ler registos inteiros como parte de um trabalho MapReduce, este tipo de trabalho é o pior caso de desempenho de Parquet, e aqui quase corresponde ao desempenho de leitura do Avro.
No outro extremo do espectro eles correram contra uma descarga de dados Github que tinha um extremo de 704 colunas de dados por registo. Aqui vemos uma vantagem mais significativa para Avro:
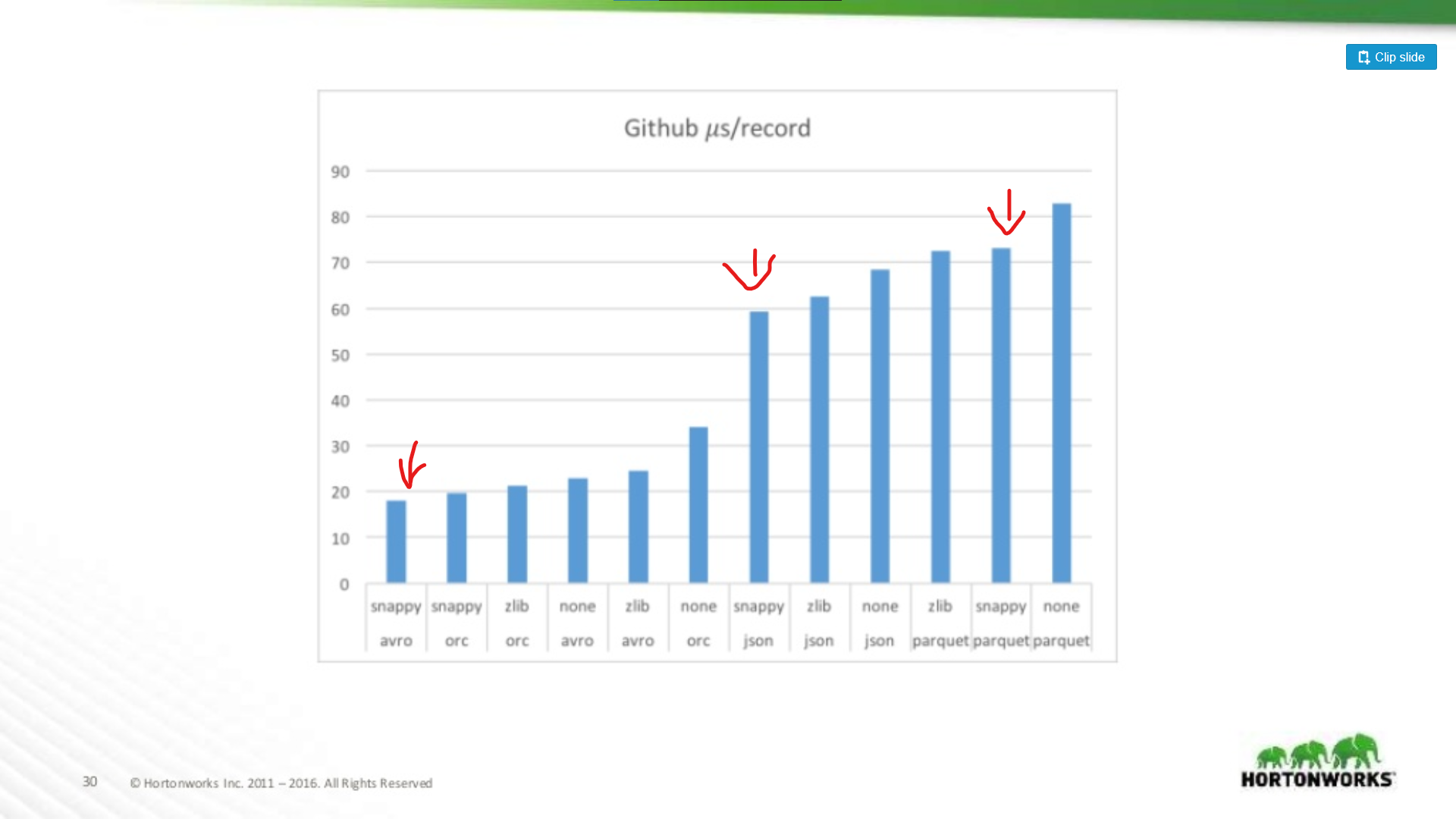
Assim, quanto mais largo for o seu conjunto de dados, pior será o Parquet para digitalizar registos inteiros (o que faz sentido). Este é um exemplo extremo, a maioria dos conjuntos de dados não têm 700 colunas de largura, para qualquer coisa razoável (< 100) O desempenho de Parquet lido é suficientemente próximo de Avro para não importar.
Parquet Investments
Dito isto, mitigar os negativos de Parquet é um foco de investimento significativo. Por exemplo, ver este artigo da Cloudera sobre a utilização da Vectorização para limitar a sobrecarga de CPU do parquet.
Continuo a ver algumas pessoas defenderem o Avro sobre Parquet, mesmo quando as leituras de registos completos são mais lentas no Avro. A minha opinião é que o armazenamento é barato! As CPUs não são. Esse mesmo artigo mostra um benefício de desempenho superior a 200x quando se lê apenas uma única coluna do ficheiro. Isso é verdadeiramente significativo, e à medida que o seu conjunto de dados cresce, irá poupar uma quantidade significativa de recursos computacionais.
Parquet é Provavelmente A Escolha Certa De Qualquer Forma
Então, se um conjunto de dados é apenas para o MapReduce, deverá ir em Avro? Não. É tremendamente útil poder ‘espreitar’ dentro de um conjunto de dados e encontrar informação rápida sobre o seu conteúdo, além disso, muitas estruturas MapReduce estão a adicionar o suporte de parquet de forma predicada. Parquet não é apenas para Analytics!
P>Even ignorando o tempo de execução dos seus trabalhos de produção, deixe-me delinear algumas das minhas formas preferidas de usar Parquet fora das cargas de trabalho de análise:
My Take: Just Use Parquet
Enquanto eu penso que há casos de uso para Avro sobre Parquet, esses casos de uso estão a desaparecer.
- O ferramental da indústria está a coalescer em torno de Parquet como um formato padrão de armazenamento de dados. Ver para Amazon Web Services, por exemplo. Eles dar-lhe-ão uma descarga de dados de utilização em Parquet (ou CSV), e o seu produto EMR fornece optimizações de escrita especiais para Parquet. O mesmo não acontece com Avro.
- Frameworks como MapReduce estão a afastar-se em favor de frameworks mais dinâmicos, como Spark, estes frameworks favorecem um estilo de programação ‘dataframe’ onde só se processam as colunas de que se precisa, e ignora-se o resto. Isto é óptimo para Parquet.
- Parquet é apenas mais flexível. Apesar de nem sempre ser necessário adquirir um conjunto de dados de forma esparsa, ser capaz de o fazer é muito útil em diversas situações. Só não se pode fazer isso com Avro, CSV, ou JSON.