Si vous avez lu mon introduction aux formats de fichiers Hadoop/Spark, vous savez qu’il existe plusieurs façons de stocker des données dans HDFS, S3 ou le stockage Blob, et que chacun de ces types de fichiers a des propriétés différentes qui les rendent bons (ou mauvais) à différentes choses.
Bien que cet article ne soit pas une plongée profonde sur le plan technique, je vais vous donner le récapitulatif des raisons pour lesquelles (et comment) vous devriez utiliser Parquet plutôt qu’un autre format populaire, Avro.
Qu’est-ce que Parquet ?
À un niveau élevé, parquet est un format de fichier pour le stockage de données structurées. Par exemple, vous pouvez utiliser parquet pour stocker un tas d’enregistrements qui ressemblent à ceci:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Vous pourriez, en fait, stocker ces données dans presque n’importe quel format de fichier, une façon conviviale de stocker ces données est dans un fichier CSV ou TSV. Voici à quoi pourraient ressembler certaines données de ce schéma dans un format CSV :
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, Dans un fichier plat JSON, nous stockerions chaque ligne en tant qu’objet JSON :
En revanche, voici une capture d’écran des mêmes données dans un format de fichier columnar illustratif que j’appelle Columnar CSV (CCSV) :
Confus des formats de fichiers columnar ? Lisez mon introduction aux formats de fichiers columnar avant d’aller plus loin
Totalement différent n’est-ce pas ? Parquet va un peu plus loin – c’est un format basé sur le binaire, et non sur le texte. Ne vous inquiétez pas, il existe de nombreux outils que vous pouvez utiliser pour inspecter et lire les fichiers Parquet et même exporter les résultats vers le bon vieux JSON. Par exemple Parquet Tools
Parquet se soucie de votre schéma
Une des limites des données CSV/TSV est que vous ne savez pas quel est le schéma exact censé être, ou le type souhaité de chaque champ.
En reprenant notre exemple ci-dessus, sans le schéma, les valeurs ‘True’ devraient-elles être coulées en booléen ? Comment pouvons-nous en être sûrs sans connaître le schéma au préalable ?
JSON s’améliore par rapport au CSV car chaque ligne fournit une certaine indication du schéma, mais sans une ligne d’en-tête spéciale, il n’y a aucun moyen de dériver un schéma pour chaque enregistrement du fichier, et il n’est pas toujours clair quel type une valeur ‘null’ doit être interprétée comme.
Avro et Parquet, en revanche, comprennent le schéma des données qu’ils stockent. Lorsque vous écrivez un fichier dans ces formats, vous devez spécifier votre schéma. Lorsque vous relisez le fichier, il vous indique le schéma des données qui y sont stockées. C’est super utile pour un framework comme Spark, qui peut utiliser cette information pour vous donner un cadre de données entièrement formé avec un effort minimal.
Parlons de Parquet vs Avro
En apparence, Avro et Parquet sont similaires ils écrivent tous deux le schéma de leurs données incluses dans un en-tête de fichier et traitent bien la dérive du schéma (ajout/suppression de colonnes). Ils sont si semblables à cet égard que Parquet prend même en charge nativement les schémas Avro, de sorte que vous pouvez migrer vos pipelines Avro vers le stockage Parquet en un tour de main.
La grande différence entre les deux formats est qu’Avro stocke les données PAR RANGÉE, et Parquet stocke les données PAR COLONNE..
- Oh hai ! N’oubliez pas mon guide des formats de fichiers colonnaires si vous voulez en savoir plus
Avantages de Parquet par rapport à Avro
Pour récapituler sur mon guide des formats de fichiers colonnaires, l’avantage de Parquet (et des formats de fichiers colonnaires en général) est principalement double :
- Réduction des coûts de stockage (généralement) par rapport à Avro
- Amélioration de 10 à 100x de la lecture des données lorsque vous n’avez besoin que de quelques colonnes
Je ne saurais trop insister sur l’avantage d’une amélioration de 100x du débit d’enregistrement. Il apporte une amélioration vraiment massive et fondamentale aux pipelines de traitement des données qu’il est très difficile de négliger.
Voici une illustration de cet avantage à partir d’une étude de cas Cloudera de retour en 2016 sur un petit ensemble de données de moins de 200 Go.
Lorsqu’on compte simplement les lignes, Parquet souffle Avro, grâce aux métadonnées que Parquet stocke dans l’en-tête des groupes de lignes.
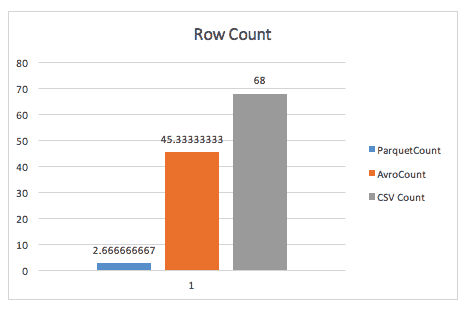
Lors de l’exécution d’une requête group-by, parquet est encore presque 2x plus rapide (bien que je ne sois pas sûr de la requête exacte utilisée ici).
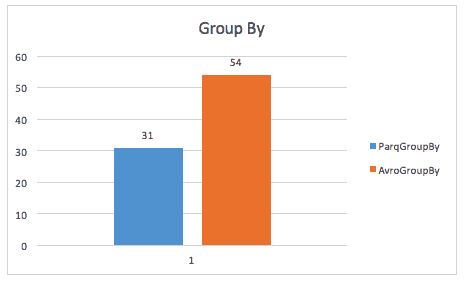
La même étude de cas trouve également des améliorations dans l’espace de stockage, et même dans les analyses de tables complètes, probablement en raison du fait que Spark doit analyser une plus petite taille de données.
Avantages d’Avro par rapport à Parquet
J’ai entendu certaines personnes argumenter en faveur d’Avro par rapport à Parquet. Ces arguments s’articulent généralement autour de deux points :
- Lorsque vous lisez des enregistrements entiers en une seule fois, Avro gagne en performance.
- Le temps d’écriture est augmenté de façon drastique pour l’écriture de fichiers Parquet par rapport aux fichiers Avro
Bien que ces deux points soient valides, ils sont des notes de bas de page mineures par rapport aux améliorations de performance de Parquet dans l’ensemble. Il existe de nombreux benchmarks disponibles en ligne pour Avro vs Parquet, mais permettez-moi de tirer un graphique d’une présentation Hortonworks 2016 comparant les performances du format de fichier dans diverses situations.
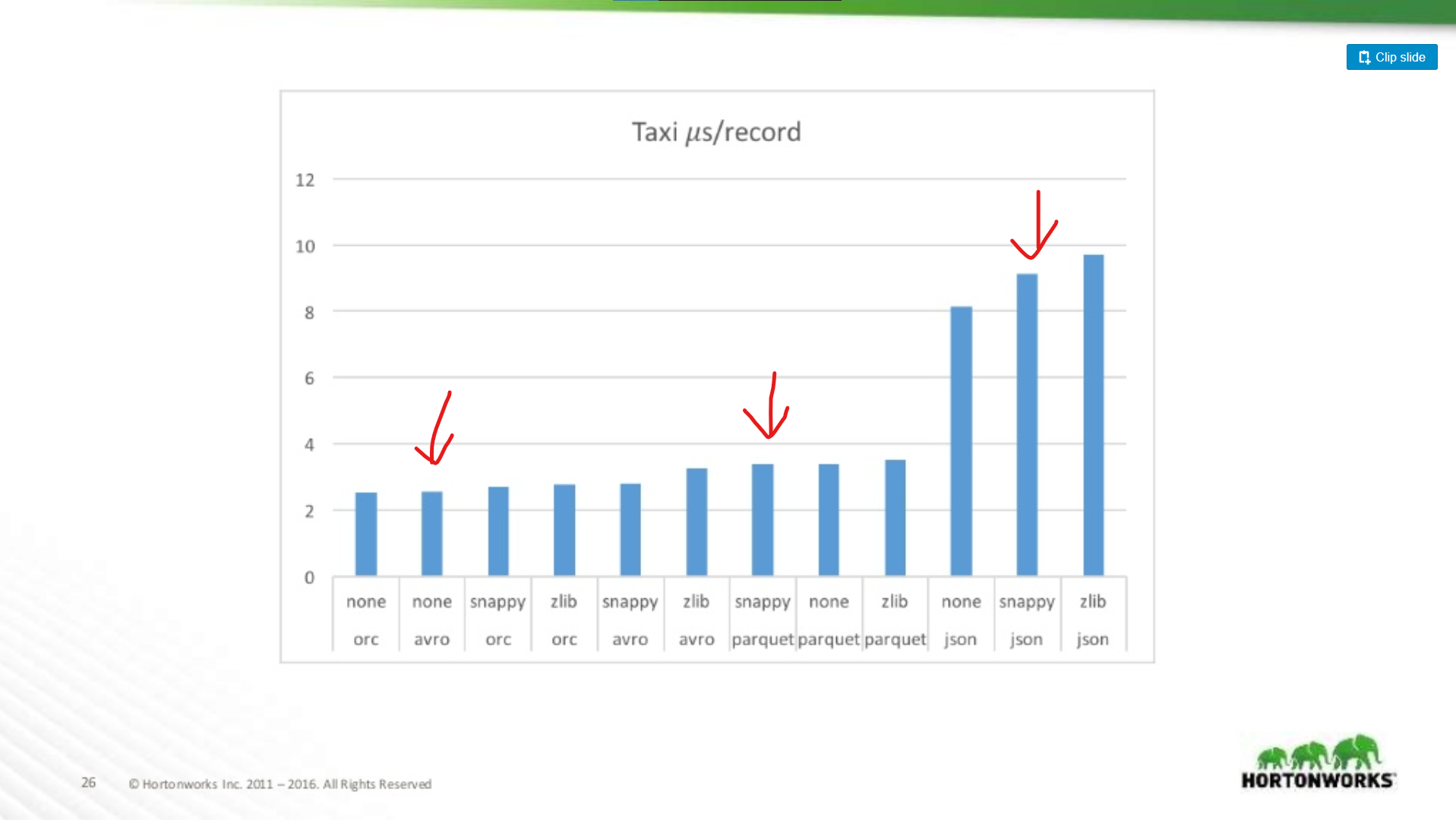
À quel point Parquet est-il pire pour les analyses d’enregistrements entiers ?
Ici, nous comparons les performances d’Avro, JSON et Parquet sur un ensemble de données Taxi contenant ~18 colonnes. Dans ce test, ils lisaient des enregistrements entiers dans le cadre d’un travail MapReduce, ce type de charge de travail est le pire cas de performance de Parquet, et ici il correspond presque à la performance de lecture d’Avro.
À l’autre extrémité du spectre, ils ont couru contre un vidage de données Github qui avait un extrême 704 colonnes de données par enregistrement. Ici, nous voyons un avantage plus significatif pour Avro:
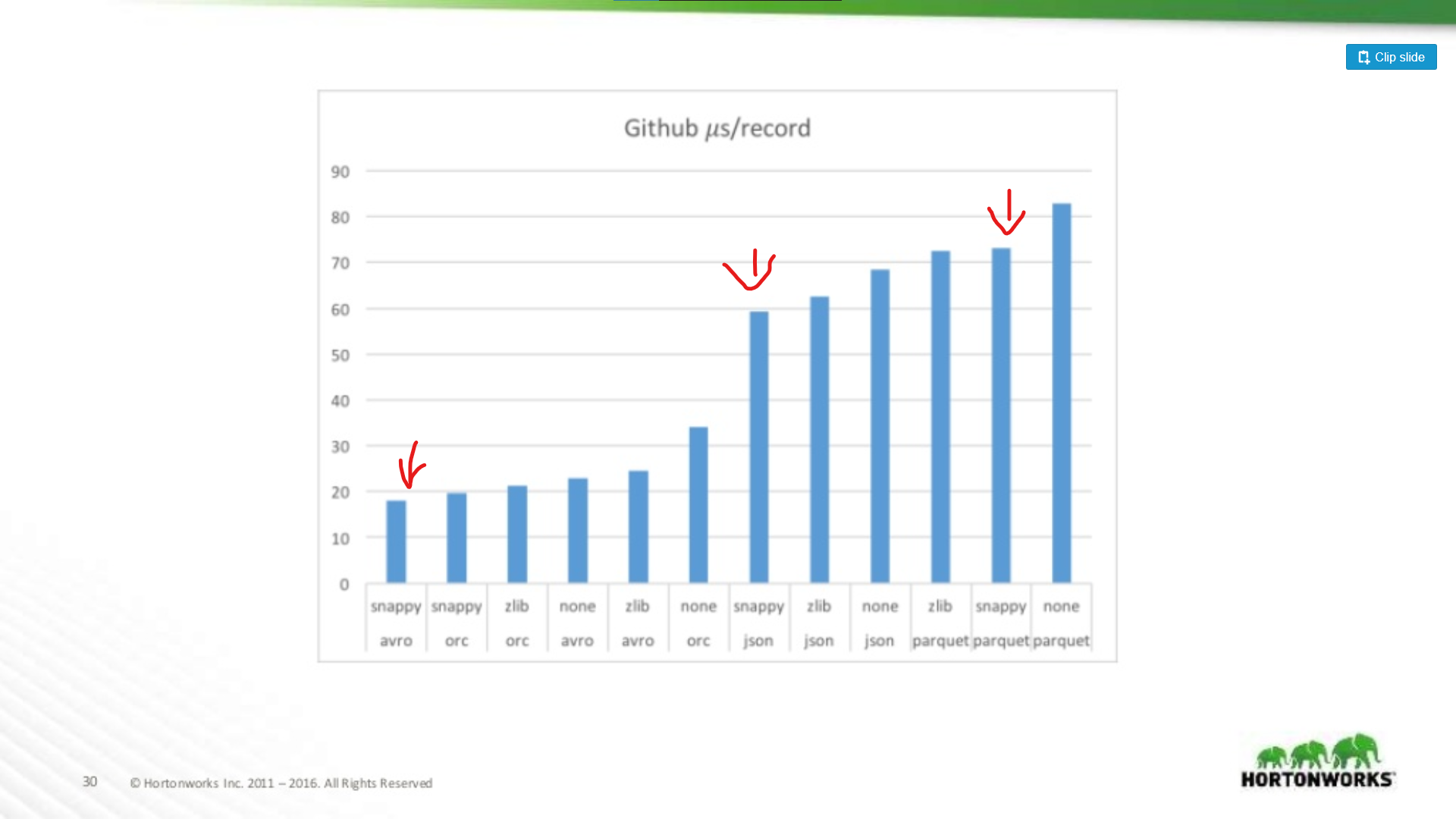
Donc, plus votre ensemble de données est large, plus Parquet devient mauvais pour analyser des enregistrements entiers (ce qui est logique). C’est un exemple extrême, la plupart des ensembles de données ne font pas 700 colonnes de large, pour tout ce qui est raisonnable (< 100), les performances de lecture de Parquet sont suffisamment proches d’Avro pour ne pas avoir d’importance.
Investissements de Parquet
Cela dit, l’atténuation des points négatifs de Parquet est l’objet d’investissements importants. Par exemple, voir cet article de Cloudera sur l’utilisation de la vectorisation pour limiter le surcoût CPU de Parquet.
Je vois encore certaines personnes plaider pour Avro plutôt que Parquet même lorsque les lectures d’enregistrements complets sont plus lentes dans Avro. Mon opinion est que le stockage est bon marché ! Les processeurs ne le sont pas. Ce même article montre un avantage de performance de plus de 200x lors de la lecture d’une seule colonne du fichier. C’est vraiment significatif, et au fur et à mesure que votre ensemble de données grandit, cela permettra d’économiser une quantité importante de ressources de calcul.
Parquet est probablement le bon choix dans les deux cas
Alors, si un ensemble de données est juste pour MapReduce, doit-il aller dans Avro ? Non. Il est extrêmement utile de pouvoir » jeter un coup d’œil » à l’intérieur d’un jeu de données et de trouver des informations rapides sur son contenu, d’ailleurs, de nombreux frameworks MapReduce ajoutent le predicate-pushdown à leur support parquet. Parquet n’est pas seulement pour l’analytique !
Même en ignorant le temps d’exécution de vos jobs de production, laissez-moi vous présenter quelques-unes de mes façons préférées d’utiliser Parquet en dehors des charges de travail analytiques :
-
Validation des données – vous avez besoin de faire quelques comptages approximatifs pour vérifier que vos données sont complètes ? De telles vérifications peuvent être exécutées en quelques secondes avec Parquet, même avec un jeu de données de 1 To.
Débogage – votre pipeline a-t-il fait la bonne chose ? A-t-il ajouté/supprimé/modifié les bons enregistrements ? Avec parquet, vous pouvez capturer des informations rapides et faciles (comme toutes les valeurs uniques d’une colonne) en quelques secondes sans scanner tout le fichier.
Extraction rapide de métriques – vous voulez enregistrer dans votre système de surveillance un compte d’un sous-ensemble d’enregistrements dans votre ensemble de données ? Auparavant, je capturais cette information en exécutant un pipeline de suivi, mais avec Parquet, c’est une requête très rapide via Hive ou Spark SQL.
Moins de redondance – Vous avez besoin d’un ensemble de données similaire pour deux pipelines différents ? Au lieu de construire un jeu de données distinct pour chacun, Parquet vous permet juste d’interroger dynamiquement un jeu de données plus grand et complet sans les pénalités liées à l’analyse d’un fichier entier.
Analytique – Ok, j’ai triché et je l’ai mis quand même. Oui, Parquet est AMAZING pour l’analytique, toute personne exécutant des requêtes SQL vous remerciera de leur avoir fait gagner des heures par jour devant une invite SQL lorsque leurs requêtes s’exécutent jusqu’à 1000x plus vite.
My Take : Just Use Parquet
Bien que je pense qu’il existe des cas d’utilisation pour Avro par rapport à Parquet, ces cas d’utilisation s’estompent.
- L’outillage de l’industrie se coalise autour de Parquet comme format de stockage de données standard. Voyez pour Amazon Web Services par exemple. Ils vous donneront une décharge de données d’utilisation en Parquet (ou CSV), et leur produit EMR fournit des optimisations d’écriture spéciales pour Parquet. Il n’en va pas de même pour Avro.
- Des frameworks comme MapReduce s’écartent au profit de frameworks plus dynamiques, comme Spark, ces frameworks favorisent un style de programmation ‘dataframe’ où vous ne traitez que les colonnes dont vous avez besoin, et ignorez le reste. C’est excellent pour Parquet.
- Parquet est tout simplement plus flexible. Bien que vous n’ayez pas toujours besoin de faire une requête éparse sur un ensemble de données, être capable de le faire est sacrément utile dans une série de situations. Vous ne pouvez pas le faire avec Avro, CSV ou JSON.