Contexte
La backpropagation est une méthode courante pour former un réseau neuronal. Il ne manque pas d’articles en ligne qui tentent d’expliquer le fonctionnement de la rétropropagation, mais rares sont ceux qui incluent un exemple avec des chiffres réels. Ce post est ma tentative d’expliquer comment cela fonctionne avec un exemple concret auquel les gens peuvent comparer leurs propres calculs afin de s’assurer qu’ils comprennent correctement la rétropropagation.
Backpropagation en Python
Vous pouvez jouer avec un script Python que j’ai écrit et qui implémente l’algorithme de rétropropagation dans ce repo Github.
Visualisation de la rétropropagation
Pour une visualisation interactive montrant un réseau neuronal au fur et à mesure de son apprentissage, consultez ma visualisation de réseau neuronal.
Ressources supplémentaires
Si vous trouvez ce tutoriel utile et que vous voulez continuer à apprendre sur les réseaux neuronaux, l’apprentissage automatique et l’apprentissage profond, je vous recommande vivement de consulter le nouveau livre d’Adrian Rosebrock, Deep Learning for Computer Vision with Python. J’ai vraiment apprécié le livre et j’aurai bientôt une critique complète.
Overview
Pour ce tutoriel, nous allons utiliser un réseau neuronal avec deux entrées, deux neurones cachés, deux neurones de sortie. De plus, les neurones cachés et de sortie comprendront un biais.
Voici la structure de base :
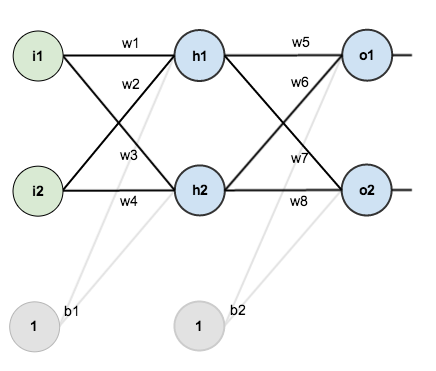
Afin d’avoir quelques chiffres sur lesquels travailler, voici les poids initiaux, les biais et les entrées/sorties d’entraînement :

Le but de la rétropropagation est d’optimiser les poids afin que le réseau neuronal puisse apprendre à mettre correctement en correspondance des entrées arbitraires et des sorties.
Pour le reste de ce tutoriel, nous allons travailler avec un seul ensemble d’apprentissage : étant donné les entrées 0,05 et 0,10, nous voulons que le réseau neuronal produise 0,01 et 0,99.
Le passage en avant
Pour commencer, voyons ce que le réseau neuronal prédit actuellement étant donné les poids et les biais ci-dessus et les entrées de 0,05 et 0,10. Pour ce faire, nous allons faire passer ces entrées dans le réseau.
Nous calculons l’entrée nette totale de chaque neurone de la couche cachée, nous écrasons l’entrée nette totale à l’aide d’une fonction d’activation (ici, nous utilisons la fonction logistique), puis nous répétons le processus avec les neurones de la couche de sortie.
Voici comment nous calculons l’entrée nette totale pour 
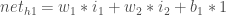

Nous l’écrasons ensuite à l’aide de la fonction logistique pour obtenir la sortie de

En effectuant le même processus pour 
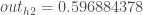
Nous répétons ce processus pour les neurones de la couche de sortie, en utilisant les sorties des neurones de la couche cachée comme entrées.
Voici la sortie pour 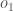



Et en effectuant le même processus pour 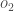
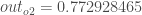
Calcul de l’erreur totale
Nous pouvons maintenant calculer l’erreur pour chaque neurone de sortie en utilisant la fonction d’erreur au carré et les additionner pour obtenir l’erreur totale :
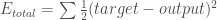
 est incluse afin que l’exposant soit annulé lorsque nous différencierons plus tard. Le résultat est finalement multiplié par un taux d’apprentissage de toute façon, donc cela n’a pas d’importance que nous introduisions une constante ici .
est incluse afin que l’exposant soit annulé lorsque nous différencierons plus tard. Le résultat est finalement multiplié par un taux d’apprentissage de toute façon, donc cela n’a pas d’importance que nous introduisions une constante ici .Par exemple, la sortie cible pour

Répéter ce processus pour

L’erreur totale pour le réseau neuronal est la somme de ces erreurs :

La rétropropagation
Notre objectif avec la rétropropagation est de mettre à jour chacun des poids du réseau afin qu’ils fassent en sorte que la sortie réelle soit plus proche de la sortie cible, minimisant ainsi l’erreur pour chaque neurone de sortie et le réseau dans son ensemble.
Couche de sortie
Considérons 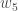
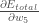
 se lit comme « la dérivée partielle de
se lit comme « la dérivée partielle de  par rapport à
par rapport à  « . On peut aussi dire « le gradient par rapport à « .
« . On peut aussi dire « le gradient par rapport à « .En appliquant la règle de la chaîne, nous savons que :
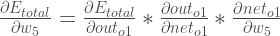
Visuellement, voici ce que nous faisons:

Nous devons déterminer chaque élément de cette équation.
Premièrement, de combien l’erreur totale change-t-elle par rapport à la sortie ?
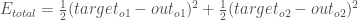
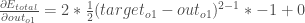

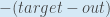 est parfois exprimé par
est parfois exprimé par 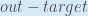
 , la quantité
, la quantité 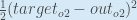 devient nulle car ne l’affecte pas ce qui signifie que nous prenons la dérivée d’une constante qui est nulle.
devient nulle car ne l’affecte pas ce qui signifie que nous prenons la dérivée d’une constante qui est nulle.Suite, de combien varie la sortie de
La dérivée partielle de la fonction logistique est la sortie multipliée par 1 moins la sortie :

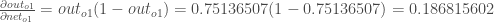
Enfin, de combien varie l’apport net total de 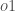
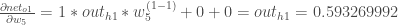
Mise en commun:


Vous verrez souvent ce calcul combiné sous la forme de la règle du delta :

Alternativement, nous avons 



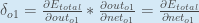
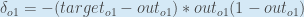
Ainsi :

Certaines sources extraient le signe négatif de 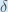
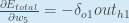
Pour diminuer l’erreur, nous soustrayons ensuite cette valeur du poids actuel (éventuellement multiplié par un certain taux d’apprentissage, eta, que nous fixerons à 0.5):

 (alpha) pour représenter le taux d’apprentissage, d’autres utilisent
(alpha) pour représenter le taux d’apprentissage, d’autres utilisent  (eta), et d’autres encore
(eta), et d’autres encore  (epsilon).
(epsilon).Nous pouvons répéter ce processus pour obtenir les nouveaux poids 
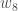
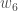
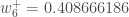


Nous effectuons les mises à jour réelles dans le réseau neuronal après avoir obtenu les nouveaux poids menant aux neurones de la couche cachée (c’est-à-dire que nous utilisons les poids originaux, et non les poids mis à jour, lorsque nous poursuivons l’algorithme de rétropropagation ci-dessous).
Couche cachée
Après, nous allons continuer la passe en arrière en calculant de nouvelles valeurs pour 

Voilà ce qu’il faut comprendre :

Visuellement :

Nous allons utiliser un processus similaire à celui de la couche de sortie, mais légèrement différent pour tenir compte du fait que la sortie de chaque neurone de la couche cachée contribue à la sortie (et donc à l’erreur) de plusieurs neurones de sortie. Nous savons que 




En commençant par 
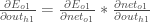
Nous pouvons calculer 

Et 

Les brancher :

En suivant le même processus pour 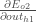

Donc:

Maintenant que nous avons 


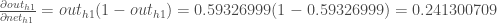
Nous calculons la dérivée partielle de l’entrée totale du réseau à 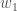


Mise en relation:
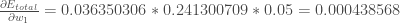
Vous pourriez aussi voir cela écrit comme:

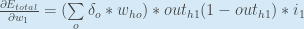

Nous pouvons maintenant mettre à jour

Répéter cela pour
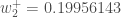

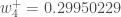
Enfin, nous avons mis à jour tous nos poids ! Lorsque nous avons fait avancer les entrées 0,05 et 0,1 à l’origine, l’erreur du réseau était de 0,298371109. Après ce premier tour de rétropropagation, l’erreur totale est maintenant réduite à 0,291027924. Cela peut sembler peu, mais après avoir répété ce processus 10 000 fois, par exemple, l’erreur tombe à 0,0000351085. À ce stade, lorsque nous alimentons 0,05 et 0,1, les deux neurones de sortie génèrent 0,015912196 (vs 0,01 cible) et 0,984065734 (vs 0,99 cible).
Si vous êtes arrivé jusqu’ici et que vous avez trouvé des erreurs dans l’un des éléments ci-dessus ou si vous pensez à des moyens de rendre les choses plus claires pour les futurs lecteurs, n’hésitez pas à me laisser un mot. Merci!