Se avete letto la mia introduzione ai formati di file di Hadoop/Spark, sarete consapevoli che ci sono diversi modi per memorizzare i dati in HDFS, S3, o nello storage Blob, e ognuno di questi tipi di file ha diverse proprietà che li rendono buoni (o cattivi) per cose diverse.
Sebbene questo articolo non sia un approfondimento tecnico, vi darò il resoconto sul perché (e come) dovreste usare Parquet rispetto ad un altro formato popolare, Avro.
Che cos’è Parquet?
A un livello superiore, parquet è un formato di file per la memorizzazione di dati strutturati. Per esempio, puoi usare parquet per memorizzare un mucchio di record che assomigliano a questo:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Potresti, infatti, memorizzare questi dati in quasi tutti i formati di file, un modo facile da leggere per memorizzare questi dati è in un file CSV o TSV. Ecco come potrebbero apparire alcuni dati di questo schema in un formato CSV:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, In un file piatto JSON, memorizzeremmo ogni riga come un oggetto JSON:
Al contrario, ecco uno screenshot degli stessi dati in un formato di file colonnare illustrativo che chiamo Columnar CSV (CCSV):
Confuso sui formati di file colonnari? Leggi la mia introduzione ai formati di file colonnari prima di andare avanti
Totalmente diverso, giusto? Parquet fa un passo avanti – è un formato basato su binari, non su testo. Non preoccuparti, ci sono molti strumenti che puoi usare per ispezionare e leggere i file Parquet e persino esportare i risultati nel buon vecchio JSON. Per esempio Parquet Tools
Parquet Cares About Your Schema
Una limitazione dei dati CSV/TSV è che non si sa quale dovrebbe essere lo schema esatto, o il tipo desiderato di ogni campo.
Usando il nostro esempio sopra, senza lo schema, i valori ‘True’ dovrebbero essere convertiti in booleani? Come possiamo esserne sicuri senza conoscere lo schema in anticipo?
JSON migliora il CSV in quanto ogni riga fornisce qualche indicazione sullo schema, ma senza una speciale riga di intestazione, non c’è modo di ricavare uno schema per ogni record nel file, e non è sempre chiaro quale tipo di valore ‘null’ dovrebbe essere interpretato.
Avro e Parquet d’altra parte comprendono lo schema dei dati che memorizzano. Quando si scrive un file in questi formati, è necessario specificare il proprio schema. Quando rileggi il file, ti dice lo schema dei dati memorizzati all’interno. Questo è super utile per un framework come Spark, che può usare queste informazioni per darti un data-frame completamente formato con il minimo sforzo.
Parliamo di Parquet vs Avro
Sulla loro faccia, Avro e Parquet sono simili: entrambi scrivono lo schema dei dati contenuti nell’intestazione del file e trattano bene la deriva dello schema (aggiungere/rimuovere colonne). Sono così simili in questo senso che Parquet supporta anche nativamente gli schemi di Avro, così puoi migrare le tue pipeline Avro allo storage Parquet in un pizzico.
La grande differenza nei due formati è che Avro memorizza i dati PER RIGA, e Parquet memorizza i dati PER COLONNA..
- Oh hai! Non dimenticare la mia guida ai formati di file colonnari se vuoi saperne di più
Vantaggi di Parquet su Avro
Per ricapitolare la mia guida ai formati di file colonnari, i vantaggi di Parquet (e dei formati di file colonnari in generale) sono principalmente due:
- Costi di archiviazione ridotti (tipicamente) rispetto ad Avro
- 10-100x miglioramento nella lettura dei dati quando si ha bisogno solo di poche colonne
Non posso sopravvalutare il beneficio di un miglioramento di 100x nel throughput dei record. Fornisce un miglioramento davvero massiccio e fondamentale per le pipeline di elaborazione dei dati che è molto difficile da trascurare.
Ecco un’illustrazione di questo beneficio da un caso di studio di Cloudera nel 2016 su un piccolo set di dati di meno di 200GB.
Quando semplicemente si contano le righe, Parquet spazza via Avro, grazie ai metadati che parquet memorizza nell’intestazione dei gruppi di righe.
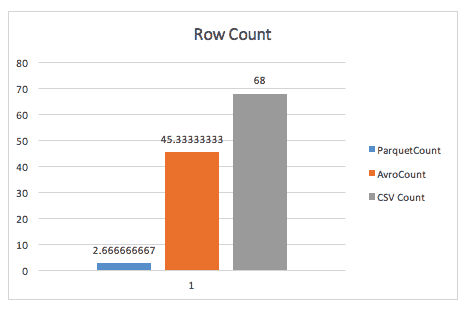
Quando si esegue una query group-by, parquet è ancora quasi 2x più veloce (anche se non sono sicuro della query esatta utilizzata in questo caso).
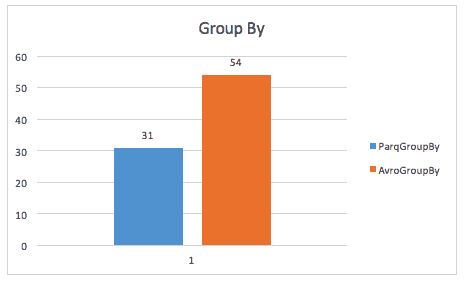
Lo stesso caso di studio trova anche miglioramenti nello spazio di archiviazione, e anche nelle scansioni a tabella intera, probabilmente a causa del fatto che Spark deve scansionare una dimensione di dati più piccola.
Benefici di Avro su Parquet
Ho sentito alcune persone argomentare a favore di Avro contro Parquet. Tali argomenti sono tipicamente basati su due punti:
- Quando si leggono interi record in una sola volta, Avro vince in termini di prestazioni.
- Il tempo di scrittura aumenta drasticamente per la scrittura di file Parquet rispetto ai file Avro
Mentre questi due punti sono validi, sono note minori rispetto ai miglioramenti complessivi delle prestazioni di Parquet. Ci sono molti benchmark disponibili online per Avro vs Parquet, ma permettetemi di disegnare un grafico da una presentazione di Hortonworks del 2016 che confronta le prestazioni del formato di file in varie situazioni.
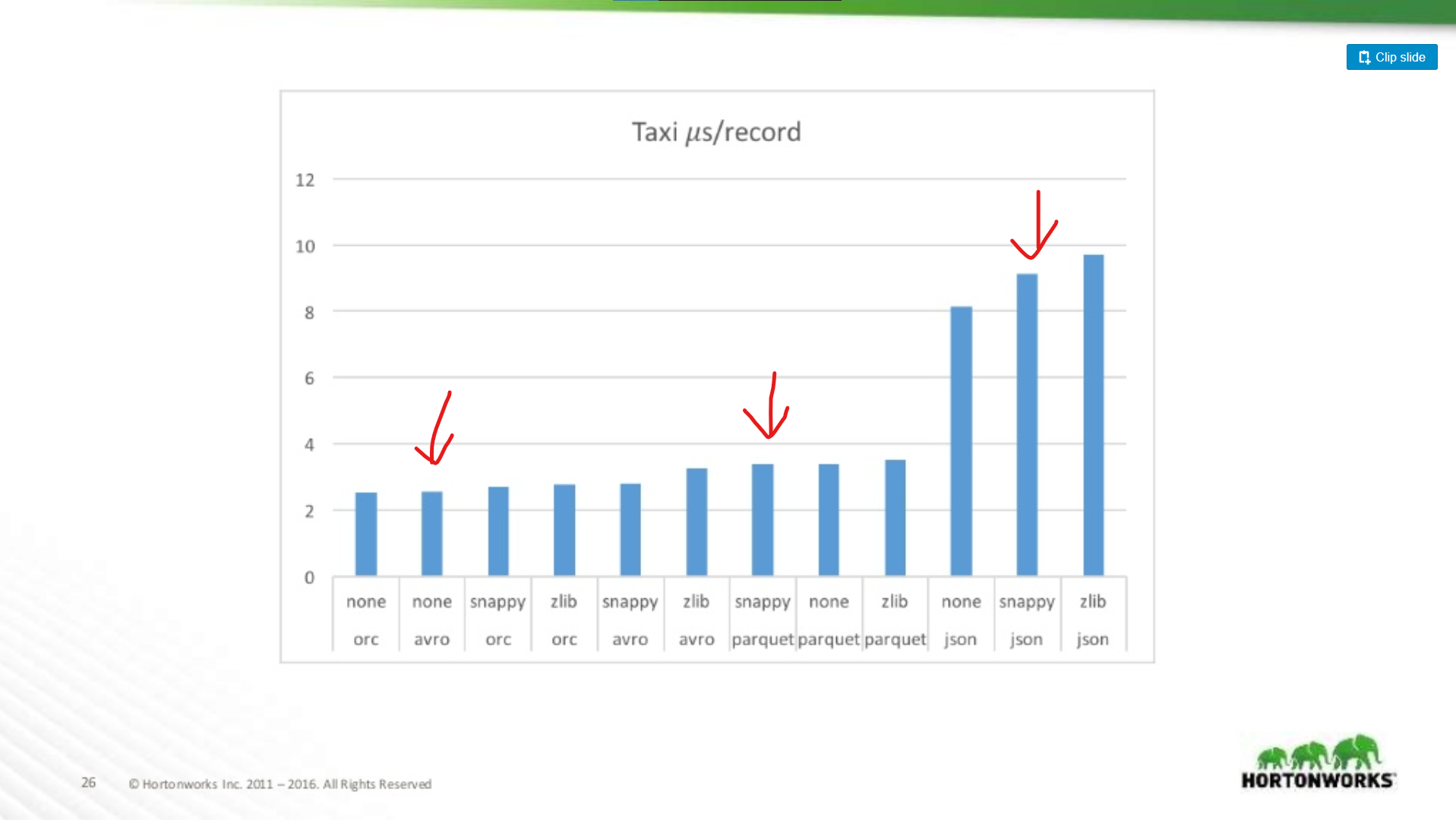
Quanto è peggiore Parquet per le scansioni di interi record?
Qui si confrontano le prestazioni di Avro, JSON, e Parquet su un dataset Taxi contenente ~18 colonne. In questo test stavano leggendo interi record come parte di un lavoro MapReduce, questo tipo di carico di lavoro è il caso peggiore per le prestazioni di Parquet, e qui corrisponde quasi alle prestazioni di lettura di Avro.
All’altra estremità dello spettro hanno eseguito contro un dump di dati Github che aveva un estremo 704 colonne di dati per record. Qui vediamo un vantaggio più significativo per Avro:
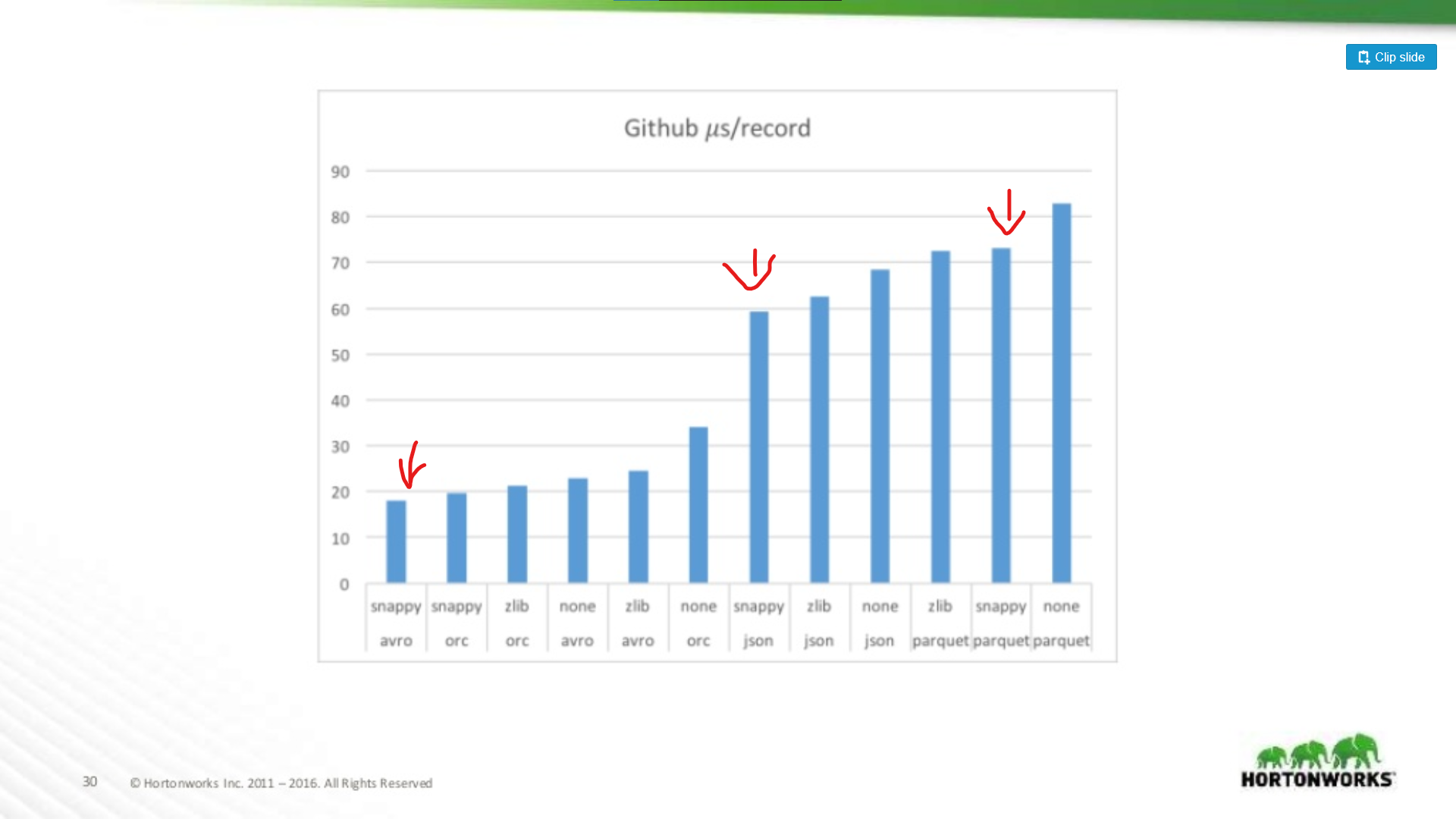
Quindi, più ampio è il vostro dataset, peggiore diventa Parquet per la scansione di interi record (il che ha senso). Questo è un esempio estremo, la maggior parte dei set di dati non sono larghi 700 colonne, per qualsiasi cosa ragionevole (< 100) le prestazioni di lettura di Parquet sono abbastanza vicine a quelle di Avro da non avere importanza.
Investimenti in Parquet
Detto questo, mitigare gli aspetti negativi di Parquet è un obiettivo di investimento significativo. Per esempio si veda questo articolo di Cloudera sull’uso della vettorizzazione per limitare l’overhead della CPU di Parquet.
Vedo ancora alcune persone sostenere Avro rispetto a Parquet anche quando le letture di interi record sono più lente in Avro. La mia opinione è che lo storage è economico! Le CPU non lo sono. Quello stesso articolo mostra un beneficio di performance di oltre 200x quando si legge solo una singola colonna dal file. Questo è veramente significativo, e man mano che il vostro dataset cresce, risparmierete una quantità significativa di risorse di calcolo.
Parquet è probabilmente la scelta giusta in entrambi i casi
Quindi se un dataset è solo per MapReduce, dovrebbe andare in Avro? No. E’ tremendamente utile essere in grado di ‘sbirciare’ all’interno di un dataset e trovare rapidamente informazioni sul suo contenuto, inoltre, molti framework MapReduce stanno aggiungendo il predicate-pushdown al loro supporto per il parquet. Parquet non è solo per Analytics!
Anche ignorando il runtime dei vostri lavori di produzione, lasciatemi delineare alcuni dei miei modi preferiti per usare Parquet al di fuori dei carichi di lavoro di analytics:
-
Convalida dei dati – avete bisogno di fare qualche conto approssimativo per verificare che i vostri dati siano completi? Questi controlli possono essere eseguiti in pochi secondi con Parquet, anche con un set di dati da 1 TB.
-
Debuging – la tua pipeline ha fatto la cosa giusta? Ha aggiunto/rimosso/modificato i record giusti? Con parquet puoi catturare informazioni facili e veloci (come tutti i valori unici di una colonna) in pochi secondi senza scansionare l’intero file.
-
Estrazione rapida di metriche – vuoi registrare nel tuo sistema di monitoraggio un conteggio di un sottoinsieme di record nel tuo dataset? In precedenza catturavo queste informazioni eseguendo una pipeline di follow-up, ma con Parquet è una query molto veloce attraverso Hive o Spark SQL.
-
Meno ridondanza – Hai bisogno di un dataset simile per due pipeline diverse? Invece di costruire un set di dati distinto per ciascuno, Parquet ti permette di interrogare dinamicamente un set di dati più grande e completo senza le penalità della scansione di un intero file.
-
Analytics – Ok, ho barato e l’ho messo comunque. Sì, Parquet è FANTASTICO per l’analitica, chiunque esegua query SQL ti ringrazierà per avergli fatto risparmiare ore al giorno davanti a un prompt SQL quando le loro query saranno fino a 1000 volte più veloci.
Il mio parere: Usa solo Parquet
Mentre penso che ci siano casi d’uso per Avro rispetto a Parquet, questi casi d’uso stanno svanendo.
- Gli strumenti dell’industria si stanno coalizzando intorno a Parquet come formato standard di archiviazione dati. Vedi per esempio Amazon Web Services. Vi daranno un dump dei dati di utilizzo in Parquet (o CSV), e il loro prodotto EMR fornisce speciali ottimizzazioni di scrittura per Parquet. Lo stesso non vale per Avro.
- Frameworks come MapReduce si stanno facendo da parte in favore di frameworks più dinamici, come Spark, questi frameworks favoriscono uno stile di programmazione ‘dataframe’ dove si elaborano solo le colonne che servono, e si ignora il resto. Questo è ottimo per Parquet.
- Parquet è semplicemente più flessibile. Anche se non è sempre necessario eseguire una sparse-query su un set di dati, essere in grado di farlo è dannatamente utile in una serie di situazioni. Non è possibile farlo con Avro, CSV o JSON.