
About The Author
Krasimir Tsonev è un coder con oltre dieci anni di esperienza nello sviluppo web. Autore di due libri su Node.js. Lavora come senior front-end developer per …Altro suKrasimir↬
- 20 minuti di lettura
- UI,Apps,JavaScript
- Salvato per la lettura offline
- Condividi su Twitter, LinkedIn


È già il 2018, e innumerevoli sviluppatori front-end stanno ancora conducendo una battaglia contro la complessità e l’immobilità. Mese dopo mese, hanno cercato il santo graal: un’architettura applicativa senza bug che li aiuti a consegnare rapidamente e con alta qualità. Io sono uno di quegli sviluppatori, e ho trovato qualcosa di interessante che potrebbe aiutare.
Abbiamo fatto un buon passo avanti con strumenti come React e Redux. Tuttavia, non sono sufficienti da soli nelle applicazioni su larga scala. Questo articolo vi introdurrà il concetto di macchine a stati nel contesto dello sviluppo front-end. Probabilmente ne avete già costruite diverse senza rendervene conto.
Un’introduzione alle macchine a stati
Una macchina a stati è un modello matematico di calcolo. È un concetto astratto per cui la macchina può avere diversi stati, ma in un dato momento ne compie solo uno. Ci sono diversi tipi di macchine a stati. La più famosa, credo, è la macchina di Turing. È una macchina a stati infiniti, il che significa che può avere un numero infinito di stati. La macchina di Turing non si adatta bene allo sviluppo odierno delle UI perché nella maggior parte dei casi abbiamo un numero finito di stati. Questo è il motivo per cui le macchine a stati finiti, come Mealy e Moore, hanno più senso.
La differenza tra loro è che la macchina Moore cambia il suo stato basandosi solo sul suo stato precedente. Sfortunatamente, abbiamo molti fattori esterni, come le interazioni degli utenti e i processi di rete, il che significa che la macchina di Moore non è abbastanza buona per noi. Quello che stiamo cercando è la macchina di Mealy. Ha uno stato iniziale e poi passa a nuovi stati in base all’input e al suo stato attuale.
Uno dei modi più semplici per illustrare come funziona una macchina a stati è guardare un tornello. Ha un numero finito di stati: bloccato e sbloccato. Ecco un semplice grafico che ci mostra questi stati, con i loro possibili ingressi e transizioni.
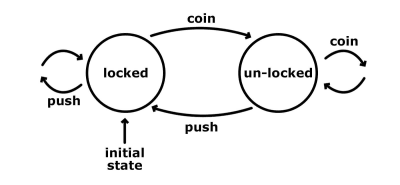
Lo stato iniziale del tornello è bloccato. Non importa quante volte lo spingiamo, rimane in quello stato bloccato. Tuttavia, se gli passiamo una moneta, allora passa allo stato sbloccato. Un’altra moneta a questo punto non farebbe nulla; sarebbe ancora nello stato sbloccato. Una spinta dall’altro lato funzionerebbe, e saremmo in grado di passare. Questa azione fa anche passare la macchina allo stato bloccato iniziale.
Se volessimo implementare una singola funzione che controlla il tornello, probabilmente finiremmo per avere due argomenti: lo stato corrente e un’azione. E se usate Redux, questo probabilmente vi suona familiare. È simile alla ben nota funzione reducer, dove riceviamo lo stato corrente, e in base al payload dell’azione, decidiamo quale sarà lo stato successivo. Il riduttore è la transizione nel contesto delle macchine a stati. In effetti, qualsiasi applicazione che ha uno stato che possiamo in qualche modo cambiare può essere chiamata una macchina a stati. È solo che stiamo implementando tutto manualmente più e più volte.
Come è meglio una macchina a stati?
Al lavoro, usiamo Redux, e ne sono abbastanza soddisfatto. Tuttavia, ho iniziato a vedere dei modelli che non mi piacciono. Con “non mi piace”, non voglio dire che non funzionano. È più che aggiungono complessità e mi costringono a scrivere più codice. Ho dovuto intraprendere un progetto secondario in cui avevo spazio per sperimentare, e ho deciso di ripensare le nostre pratiche di sviluppo React e Redux. Ho iniziato a prendere appunti sulle cose che mi preoccupavano, e mi sono reso conto che un’astrazione della macchina a stati avrebbe davvero risolto alcuni di questi problemi. Saltiamo dentro e vediamo come implementare una macchina a stati in JavaScript.
Attacchiamo un problema semplice. Vogliamo recuperare dati da un’API di back-end e mostrarli all’utente. Il primo passo è imparare a pensare in stati, piuttosto che in transizioni. Prima di addentrarci nelle macchine a stati, il mio flusso di lavoro per costruire una funzione del genere assomigliava a questo:
- Visualizziamo un pulsante fetch-data.
- L’utente clicca il pulsante fetch-data.
- Fa partire la richiesta al back-end.
- Recupera i dati e li analizza.
- Mostra all’utente.
- O, se c’è un errore, visualizza il messaggio di errore e mostra il pulsante fetch-data in modo da poter avviare nuovamente il processo.

Stiamo pensando linearmente e fondamentalmente cercando di coprire tutte le possibili direzioni verso il risultato finale. Un passo porta ad un altro, e rapidamente inizieremmo a ramificare il nostro codice. Che dire di problemi come l’utente che fa doppio clic sul pulsante, o l’utente che fa clic sul pulsante mentre aspettiamo la risposta del back end, o la richiesta che ha successo ma i dati sono corrotti. In questi casi, avremmo probabilmente vari flag che ci mostrano cosa è successo. Avere dei flag significa più if clausole e, nelle app più complesse, più conflitti.

Questo perché stiamo pensando in transizioni. Ci stiamo concentrando su come queste transizioni avvengono e in quale ordine. Concentrarsi invece sui vari stati dell’applicazione sarebbe molto più semplice. Quanti stati abbiamo, e quali sono i loro possibili ingressi? Usando lo stesso esempio:
- idle
In questo stato, visualizziamo il pulsante fetch-data, ci sediamo e aspettiamo. Le possibili azioni sono:- click
Quando l’utente clicca il pulsante, stiamo sparando la richiesta al back end e poi passiamo la macchina ad uno stato di “fetching”.
- click
- fetching
La richiesta è in volo, e ci sediamo e aspettiamo. Le azioni sono:- successo
I dati arrivano con successo e non sono corrotti. Usiamo i dati in qualche modo e torniamo allo stato “inattivo”. - fallimento
Se c’è un errore durante la richiesta o l’analisi dei dati, passiamo allo stato “errore”.
- successo
- errore
Mostriamo un messaggio di errore e mostriamo il pulsante fetch-data. Questo stato accetta un’azione:- retry
Quando l’utente clicca il pulsante retry, lanciamo nuovamente la richiesta e passiamo allo stato “fetching”.
- retry
Abbiamo descritto più o meno gli stessi processi, ma con stati e ingressi.
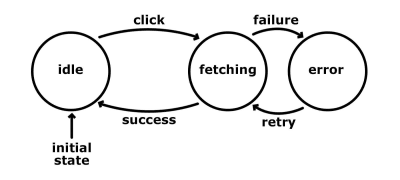
Questo semplifica la logica e la rende più prevedibile. Risolve anche alcuni dei problemi menzionati sopra. Notate che, mentre siamo in stato di “fetching”, non stiamo accettando alcun click. Quindi, anche se l’utente fa clic sul pulsante, non succederà nulla perché la macchina non è configurata per rispondere a quell’azione mentre è in quello stato. Questo approccio elimina automaticamente la ramificazione imprevedibile della nostra logica di codice. Questo significa che avremo meno codice da coprire durante i test. Inoltre, alcuni tipi di test, come i test di integrazione, possono essere automatizzati. Pensate a come avremmo un’idea molto chiara di cosa fa la nostra applicazione, e potremmo creare uno script che va oltre gli stati e le transizioni definite e che genera asserzioni. Queste asserzioni potrebbero provare che abbiamo raggiunto ogni possibile stato o coperto un particolare percorso.
In effetti, scrivere tutti i possibili stati è più facile che scrivere tutte le possibili transizioni perché sappiamo di quali stati abbiamo bisogno o abbiamo. A proposito, nella maggior parte dei casi, gli stati descriverebbero la logica di business della nostra applicazione, mentre le transizioni sono molto spesso sconosciute all’inizio. I bug nel nostro software sono il risultato di azioni inviate in uno stato sbagliato e/o al momento sbagliato. Lasciano la nostra applicazione in uno stato che non conosciamo, e questo rompe il nostro programma o lo fa comportare in modo sbagliato. Naturalmente, non vogliamo trovarci in una situazione del genere. Le macchine a stati sono dei buoni firewall. Ci proteggono dal raggiungere stati sconosciuti perché stabiliamo dei limiti per ciò che può accadere e quando, senza dire esplicitamente come. Il concetto di una macchina a stati si accoppia molto bene con un flusso di dati unidirezionale. Insieme, riducono la complessità del codice e chiariscono il mistero di dove uno stato abbia avuto origine.
Creare una macchina a stati in JavaScript
Basta parlare – vediamo un po’ di codice. Useremo lo stesso esempio. In base alla lista di cui sopra, inizieremo con quanto segue:
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } }}Abbiamo gli stati come oggetti e i loro possibili ingressi come funzioni. Manca però lo stato iniziale. Cambiamo il codice qui sopra in questo:
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } }}Una volta definiti tutti gli stati che hanno senso per noi, siamo pronti per inviare l’input e cambiare stato. Lo faremo usando i due metodi helper qui sotto:
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions; const action = this.transitions; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ...}La funzione dispatch controlla se esiste un’azione con il nome dato nelle transizioni dello stato corrente. In caso affermativo, la lancia con il carico utile dato. Chiamiamo anche il gestore action con il machine come contesto, in modo da poter inviare altre azioni con this.dispatch(<action>) o cambiare lo stato con this.changeStateTo(<new state>).
Seguendo il percorso utente del nostro esempio, la prima azione che dobbiamo inviare è click. Ecco come appare il gestore di questa azione:
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ...}machine.dispatch('click');Prima cambiamo lo stato della macchina a fetching. Poi, attiviamo la richiesta al back end. Supponiamo di avere un servizio con un metodo getData che restituisce una promessa. Una volta che è risolta e il parsing dei dati è OK, inviamo success, altrimenti failure.
Fin qui tutto bene. Ora dobbiamo implementare success e failure azioni e input sotto lo stato fetching:
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ...}Nota come abbiamo liberato il nostro cervello dal dover pensare al processo precedente. Non ci interessano i clic dell’utente o cosa sta succedendo con la richiesta HTTP. Sappiamo che l’applicazione è in uno stato fetching e ci aspettiamo solo queste due azioni. È un po’ come scrivere nuova logica in isolamento.
L’ultimo pezzo è lo stato error. Sarebbe bello se fornissimo quella logica di retry in modo che l’applicazione possa recuperare dal fallimento.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } }}Qui dobbiamo duplicare la logica che abbiamo scritto nel click handler. Per evitarlo, dovremmo o definire il gestore come una funzione accessibile ad entrambe le azioni, oppure passare prima allo stato idle e poi inviare manualmente l’azione click.
Un esempio completo della macchina a stati funzionante può essere trovato nel mio Codepen.
Gestire le macchine a stati con una libreria
Il pattern della macchina a stati finiti funziona indipendentemente dal fatto che si usi React, Vue o Angular. Come abbiamo visto nella sezione precedente, possiamo facilmente implementare una macchina a stati senza molti problemi. Tuttavia, a volte una libreria fornisce più flessibilità. Alcune di queste sono Machina.js e XState. In questo articolo, tuttavia, parleremo di Stent, la mia libreria simile a Redux che cuoce il concetto di macchine a stati finiti.
Stent è un’implementazione di un contenitore di macchine a stati. Segue alcune delle idee dei progetti Redux e Redux-Saga, ma fornisce, secondo me, processi più semplici e senza boilerplate. È sviluppato utilizzando lo sviluppo readme-driven, e ho letteralmente trascorso settimane solo sulla progettazione delle API. Poiché stavo scrivendo la libreria, ho avuto la possibilità di risolvere i problemi che ho incontrato mentre usavo le architetture Redux e Flux.
Creare macchine
Nella maggior parte dei casi, le nostre applicazioni coprono più domini. Non possiamo usare una sola macchina. Quindi, Stent permette la creazione di molte macchine:
import { Machine } from 'stent';const machineA = Machine.create('A', { state: ..., transitions: ...});const machineB = Machine.create('B', { state: ..., transitions: ...});In seguito, possiamo ottenere l’accesso a queste macchine usando il metodo Machine.get:
const machineA = Machine.get('A');const machineB = Machine.get('B');Collegare le macchine alla logica di rendering
Il rendering nel mio caso è fatto tramite React, ma possiamo usare qualsiasi altra libreria. Si riduce a sparare un callback in cui attiviamo il rendering. Una delle prime funzioni su cui ho lavorato è stata la funzione connect:
import { connect } from 'stent/lib/helpers';Machine.create('MachineA', ...);Machine.create('MachineB', ...);connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here });Diciamo quali macchine sono importanti per noi e diamo i loro nomi. Il callback che passiamo a map viene sparato una volta inizialmente e poi successivamente ogni volta che lo stato di alcune delle macchine cambia. È qui che attiviamo il rendering. A questo punto, abbiamo accesso diretto alle macchine collegate, quindi possiamo recuperare lo stato attuale e i metodi. Ci sono anche mapOnce, per ottenere il callback sparato solo una volta, e mapSilent, per saltare l’esecuzione iniziale. È molto simile al connect(mapStateToProps) di Redux.
import React from 'react';import { connect } from 'stent/lib/react';class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... }}// MachineA and MachineB are machines defined// using Machine.create functionexport default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos });Stent esegue il nostro mapping callback e si aspetta di ricevere un oggetto – un oggetto che viene inviato come props al nostro componente React.
Cos’è lo stato nel contesto di Stent?
Fino ad ora, il nostro stato era costituito da semplici stringhe. Sfortunatamente, nel mondo reale, dobbiamo tenere più di una stringa nello stato. Questo è il motivo per cui lo stato di Stent è in realtà un oggetto con proprietà all’interno. L’unica proprietà riservata è name. Tutto il resto sono dati specifici dell’applicazione. Per esempio:
{ name: 'idle' }{ name: 'fetching', todos: }{ name: 'forward', speed: 120, gear: 4 }La mia esperienza con Stent finora mi mostra che se l’oggetto stato diventa più grande, avremmo probabilmente bisogno di un’altra macchina che gestisca quelle proprietà aggiuntive. Identificare i vari stati richiede un po’ di tempo, ma credo che questo sia un grande passo avanti nella scrittura di applicazioni più gestibili. È un po’ come prevedere il futuro e disegnare i frame delle azioni possibili.
Lavorare con la macchina a stati
Similmente all’esempio dell’inizio, dobbiamo definire i possibili stati (finiti) della nostra macchina e descrivere i possibili ingressi:
import { Machine } from 'stent';const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } }});Abbiamo il nostro stato iniziale, idle, che accetta un’azione di run. Una volta che la macchina è in uno stato running, siamo in grado di lanciare l’azione stop, che ci riporta allo stato idle.
Probabilmente ricorderete gli helper dispatch e changeStateTo della nostra implementazione precedente. Questa libreria fornisce la stessa logica, ma è nascosta internamente, e non dobbiamo pensarci. Per comodità, sulla base della proprietà transitions, Stent genera quanto segue:
- metodi di aiuto per controllare se la macchina è in un particolare stato – lo stato
idleproduce il metodoisIdle(), mentre perrunningabbiamoisRunning(); - metodi di aiuto per l’invio di azioni:
runPlease()estopNow().
Quindi, nell’esempio sopra, possiamo usare questo:
machine.isIdle(); // booleanmachine.isRunning(); // booleanmachine.runPlease(); // fires actionmachine.stopNow(); // fires actionCombinando i metodi generati automaticamente con la funzione di utilità connect, siamo in grado di chiudere il cerchio. Un’interazione dell’utente attiva l’input e l’azione della macchina, che aggiorna lo stato. A causa di questo aggiornamento, la funzione di mappatura passata a connect viene licenziata, e siamo informati del cambiamento di stato. Poi, facciamo il rerender.
Gestori di input e azioni
Probabilmente la parte più importante sono i gestori di azioni. Questo è il posto dove scriviamo la maggior parte della logica dell’applicazione, perché stiamo rispondendo a input e stati cambiati. Qualcosa che mi piace molto in Redux è anche integrato qui: l’immutabilità e la semplicità della funzione reducer. L’essenza del gestore di azioni di Stent è la stessa. Riceve lo stato corrente e il payload dell’azione, e deve restituire il nuovo stato. Se il gestore non restituisce nulla (undefined), allora lo stato della macchina rimane lo stesso.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = ; return { name: 'idle', todos }; } }}Immaginiamo di dover recuperare dei dati da un server remoto. Lanciamo la richiesta e passiamo la macchina ad uno stato fetching. Una volta che i dati arrivano dal back-end, lanciamo un’azione success, così:
machine.success({ label: '...' });Poi, torniamo a uno stato idle e conserviamo alcuni dati sotto forma di array todos. Ci sono un paio di altri possibili valori da impostare come gestori di azioni. Il primo e più semplice caso è quando passiamo solo una stringa che diventa il nuovo stato.
transitions: { 'idle': { 'run': 'running' }}Questa è una transizione da { name: 'idle' } a { name: 'running' } usando l’azione run(). Questo approccio è utile quando abbiamo transizioni di stato sincrone e non abbiamo metadati. Quindi, se teniamo qualcos’altro in stato, questo tipo di transizione lo farà uscire. Allo stesso modo, possiamo passare un oggetto di stato direttamente:
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: } }}Stiamo passando da editing a idle usando l’azione deleteAllTodos.
Abbiamo già visto il gestore di funzioni, e l’ultima variante del gestore di azioni è una funzione generatrice. Si ispira al progetto Redux-Saga, e si presenta così:
import { call } from 'stent/lib/helpers';Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } }});Se non avete esperienza con i generatori, questo potrebbe sembrare un po’ criptico. Ma i generatori in JavaScript sono uno strumento potente. Ci permettono di mettere in pausa il nostro gestore di azioni, cambiare stato più volte e gestire la logica asincrona.
Divertirsi con i generatori
Quando sono stato introdotto per la prima volta a Redux-Saga, ho pensato che fosse un modo troppo complicato per gestire operazioni asincrone. In realtà, è un’implementazione piuttosto intelligente del pattern di progettazione dei comandi. Il vantaggio principale di questo pattern è che separa l’invocazione della logica e la sua effettiva implementazione.
In altre parole, diciamo ciò che vogliamo ma non come dovrebbe accadere. La serie di blog di Matt Hink mi ha aiutato a capire come vengono implementate le saghe, e ne consiglio vivamente la lettura. Ho portato le stesse idee in Stent, e per lo scopo di questo articolo, diremo che cedendo cose, stiamo dando istruzioni su ciò che vogliamo senza effettivamente farlo. Una volta che l’azione viene eseguita, riceviamo indietro il controllo.
Al momento, un paio di cose possono essere inviate (cedute):
- un oggetto stato (o una stringa) per cambiare lo stato della macchina;
- una chiamata dell’helper
call(accetta una funzione sincrona, che è una funzione che restituisce una promessa o un’altra funzione generatrice) – stiamo fondamentalmente dicendo, “Esegui questo per me, e se è asincrono, aspetta. Una volta che hai finito, dammi il risultato”; - una chiamata dell’helper
wait(accetta una stringa che rappresenta un’altra azione); se usiamo questa funzione di utilità, mettiamo in pausa il gestore e aspettiamo che un’altra azione venga spedita.
Ecco una funzione che illustra le varianti:
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... });}...transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } }}Come possiamo vedere, il codice sembra sincrono, ma in realtà non lo è. È solo Stent che fa la parte noiosa di aspettare la promessa risolta o iterare su un altro generatore.
Come Stent sta risolvendo le mie preoccupazioni su Redux
Troppo codice boilerplate
L’architettura Redux (e Flux) si basa su azioni che circolano nel nostro sistema. Quando l’applicazione cresce, di solito finiamo per avere un sacco di costanti e creatori di azioni. Queste due cose sono molto spesso in cartelle diverse, e tracciare l’esecuzione del codice a volte richiede tempo. Inoltre, quando si aggiunge una nuova funzione, dobbiamo sempre avere a che fare con un intero set di azioni, il che significa definire più nomi di azioni e creatori di azioni.
In Stent, non abbiamo nomi di azioni, e la libreria crea automaticamente i creatori di azioni per noi:
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } }});machine.addTodo({ title: 'Fix that bug' });Abbiamo il machine.addTodo creatore di azioni definito direttamente come un metodo della macchina. Questo approccio ha anche risolto un altro problema che ho affrontato: trovare il riduttore che risponde ad una particolare azione. Di solito, nei componenti React, vediamo nomi di creatori di azioni come addTodo; tuttavia, nei riduttori, lavoriamo con un tipo di azione che è costante. A volte devo saltare al codice del creatore di azioni solo per poter vedere il tipo esatto. Qui, non abbiamo nessun tipo.
Cambiamenti di stato imprevedibili
In generale, Redux fa un buon lavoro di gestione dello stato in modo immutabile. Il problema non è in Redux stesso, ma nel fatto che lo sviluppatore è autorizzato a dispensare qualsiasi azione in qualsiasi momento. Se diciamo che abbiamo un’azione che accende le luci, va bene sparare quell’azione due volte di seguito? Se no, allora come dovremmo risolvere questo problema con Redux? Beh, probabilmente metteremo del codice nel riduttore che protegge la logica e che controlla se le luci sono già accese – forse una clausola if che controlla lo stato attuale. Ora la domanda è: questo non va oltre lo scopo del riduttore? Il riduttore dovrebbe conoscere questi casi limite?
Quello che mi manca in Redux è un modo per fermare il dispacciamento di un’azione basata sullo stato corrente dell’applicazione senza inquinare il riduttore con la logica condizionale. E non voglio nemmeno portare questa decisione al livello della vista, dove il creatore dell’azione viene licenziato. Con Stent, questo avviene automaticamente perché la macchina non risponde alle azioni che non sono dichiarate nello stato corrente. Per esempio:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } }});// this is finemachine.run();// This will do nothing because at this point// the machine is in a 'running' state and there is// only 'stop' action there.machine.jump();Il fatto che la macchina accetti solo input specifici in un dato momento ci protegge da strani bug e rende le nostre applicazioni più prevedibili.
Stati, non transizioni
Redux, come Flux, ci fa pensare in termini di transizioni. Il modello mentale dello sviluppo con Redux è praticamente guidato dalle azioni e da come queste azioni trasformano lo stato nei nostri riduttori. Questo non è male, ma ho scoperto che invece ha più senso pensare in termini di stati – in quali stati l’app potrebbe trovarsi e come questi stati rappresentano i requisiti di business.
Conclusione
Il concetto di macchine a stati nella programmazione, specialmente nello sviluppo di UI, mi ha aperto gli occhi. Ho iniziato a vedere macchine a stati ovunque, e ho un certo desiderio di passare sempre a questo paradigma. Vedo sicuramente i benefici di avere stati più strettamente definiti e transizioni tra di essi. Sono sempre alla ricerca di modi per rendere le mie applicazioni semplici e leggibili. Credo che le macchine a stati siano un passo in questa direzione. Il concetto è semplice e allo stesso tempo potente. Ha il potenziale per eliminare molti bug.