Background
バックプロパゲーションは、ニューラル ネットワークをトレーニングするための一般的な方法です。 バックプロパゲーションがどのように機能するかを説明しようとする論文には事欠きませんが、実際の数値を示した例を含むものはほとんどありません。
Backpropagation in Python
バックプロパゲーション アルゴリズムを実装するために私が書いた Python スクリプトは、この Github レポで遊ぶことができます。
Backpropagation Visualization
学習中のニューラル ネットワークを示すインタラクティブなビジュアライゼーションについては、私の Neural Network visualization をご覧ください。
Overview
このチュートリアルでは、2つの入力、2つの隠れニューロン、2つの出力ニューロンを持つニューラルネットワークを使用します。 さらに、隠れニューロンと出力ニューロンにはバイアスが含まれています。
基本的な構造は以下のとおりです。
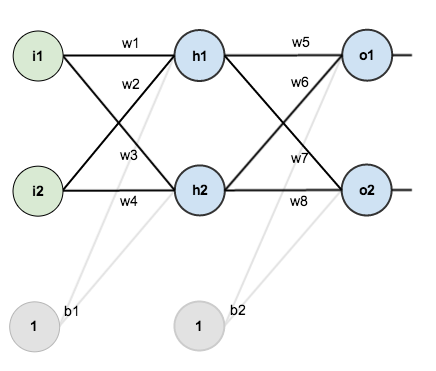
作業に必要な数を得るために、初期の重み、バイアス、トレーニング用の入力/出力を示します。

バックプロパゲーションの目的は、ニューラル ネットワークが任意の入力を出力に正しくマッピングする方法を学習できるように、重みを最適化することです。
このチュートリアルの残りの部分では、単一のトレーニング セットを使用します: 入力 0.05 および 0.10 が与えられた場合、ニューラル ネットワークに 0.01 および 0.99 を出力させます。
各隠れ層のニューロンへの純入力の合計を計算し、活性化関数 (ここではロジスティック関数を使用) を使用して純入力の合計を潰し、出力層のニューロンでこのプロセスを繰り返します。
ここでは、
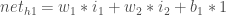

続いて、ロジスティック関数を用いて、


隠れ層のニューロンからの出力を入力として、出力層のニューロンにこのプロセスを繰り返します。
以下は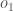


そして、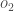
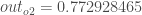
総合誤差の計算
ここで、二乗誤差関数を使って各出力ニューロンの誤差を計算し、それらを合計して総合誤差を得ることができます。
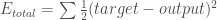
 が含まれているのは、後に微分する際に指数がキャンセルされるためです。
が含まれているのは、後に微分する際に指数がキャンセルされるためです。 例えば、

このプロセスを

ニューラルネットワークのトータルエラーは、これらのエラーの合計です。 + E_{o2} = 0.274811083 + 0.023560026 = 0.298371109
バックワードパス
バックプロパゲーションの目的は、実際の出力が目標出力に近づくようにネットワーク内の各重みを更新することで、各出力ニューロンおよびネットワーク全体の誤差を最小化することです。
出力層
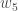
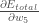


 を基準とした勾配」とも言えます。
を基準とした勾配」とも言えます。連鎖律を適用すると次のようになります。
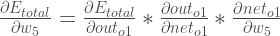

この式の各部分を把握する必要があります。
まず、トータルエラーは出力に対してどのくらい変化するのでしょうか?
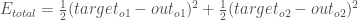
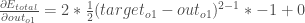
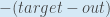
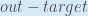

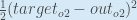 rac{1}{2}(target_{o2} – out_{o2})^{2}
rac{1}{2}(target_{o2} – out_{o2})^{2}はゼロとなり、ゼロである定数の微分を取っていることになります。
次に、
ロジスティック関数の偏微分は、出力に1をかけたものから出力を引いたものになります。

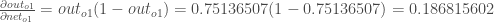
最後に、
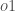

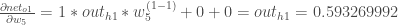
Putting it all:


この計算をデルタルールという形で組み合わせているのをよく見かけます。

別の方法としては。 となり、



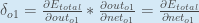
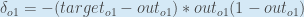
従って、以下のようになります。

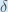
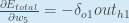
誤差を減らすために、現在の重みからこの値を差し引きます(任意で学習率 eta を掛けますが、ここでは 0.5):



 (イプシロン)を使う資料もあります。
(イプシロン)を使う資料もあります。この作業を繰り返して、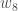
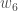

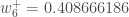


隠れ層のニューロンにつながる新しい重みを得た後、ニューラル ネットワークで実際の更新を実行します (つまり、以下のバックプロパゲーション アルゴリズムを続行する際には、更新された重みではなく、元の重みを使用します)。
隠れ層
次に、
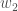

全体像を把握するには、次のようにします。

視覚的に。
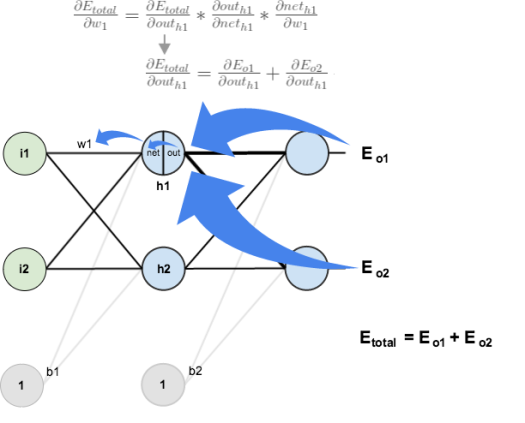
出力層で行ったのと同様のプロセスを使用しますが、各隠れ層ニューロンの出力が複数の出力ニューロンの出力 (したがって誤差) に寄与するという事実を考慮して、若干異なります。 




まず、

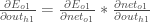
先ほど計算した値を使って、

そして、


プラグイン:

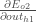
Therefore:

さて、


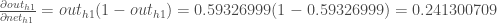
出力ニューロンで行ったのと同じように、


Putting all is it together:
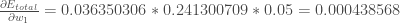
= 0.036350306 * 0.241300709 * 0.05 = 0.000438568
これを次のように書くこともできます。

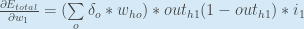
= (˶ˆ꒳ˆ˵ ) out_{h1}) * i_{1}

これで

これを
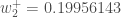

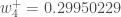
最終的に、すべてのウェイトを更新しました! 最初に 0.05 と 0.1 の入力をフィードフォワードしたとき、ネットワークのエラーは 0.298371109 でした。 今回のバックプロパゲーションの結果、誤差の合計は0.291027924となりました。 しかし、これを例えば1万回繰り返すと、誤差は0.0000351085にまで減少します。
ここまで来て、上記のいずれかに誤りを発見したり、将来の読者のためにもっとわかりやすくする方法を思いついたりしたら、遠慮なく私に連絡してください。 ありがとうございました!