Hadoop/Spark ファイル形式の紹介をお読みになった方は、HDFS、S3、または Blob ストレージにデータを保存するには複数の方法があり、これらのファイル形式にはそれぞれ得意な(または苦手な)特性があることをご存知でしょう。
この記事は技術的に深く掘り下げるものではありませんが、なぜ(そしてどのように)ParquetをAvroという他のポピュラーなフォーマットよりも使うべきなのか、その概要を説明します。
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}実際には、ほとんどすべてのファイル形式でこのデータを保存することができますが、読者にとって使いやすい方法は、CSV または TSV ファイルです。
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, JSON フラット ファイルでは、各行を JSON オブジェクトとして保存します。
これに対して、Columnar CSV (CCSV) と呼んでいるColumnarファイルフォーマットのスクリーンショットは以下のとおりです。 先に進む前に、Columnarファイル形式の紹介をお読みください
全く違うでしょう? Parquet はさらに一歩進んで、テキスト ベースのフォーマットではなく、バイナリ ベースのフォーマットです。 ご心配なく。Parquet ファイルの検査や読み取り、さらには結果を古き良き JSON にエクスポートするために使用できるツールがたくさんあります。 例えば、Parquet Tools
Parquet Cares About Your Schema
CSV/TSV データの制限の 1 つは、正確なスキーマがどうなっているか、または各フィールドの望ましいタイプがわからないことです。
JSON は、各行が何らかのスキーマの兆候を提供するため、CSV よりも改善されていますが、特別なヘッダー行がないため、ファイル内のすべてのレコードのスキーマを導き出す方法はなく、「null」値がどのようなタイプとして解釈されるべきかは必ずしも明確ではありません。 一方、Avro や Parquet は、保存するデータのスキーマを理解しています。これらのフォーマットでファイルを書くときには、スキーマを指定する必要があります。 ファイルを読み返すと、その中に保存されているデータのスキーマを教えてくれます。
Let’s talk about Parquet vs Avro
AvroとParquetは表面的には似ていますが、どちらもファイルヘッダーに格納されたデータのスキーマを記述し、スキーマドリフト(カラムの追加/削除)にうまく対応しています。
2つのフォーマットの大きな違いは、Avroはデータを行ごとに保存し、Parquetは列ごとに保存することです。
- お待たせしました。
- おおっと!もっと詳しく知りたい方は、コラムナー ファイル フォーマットのガイドをお忘れなく!
Avro に対する Parquet の利点
コラムナー ファイル フォーマットのガイドを要約すると、Parquet (および一般的なコラムナー ファイル フォーマット) の利点は主に 2 つあります。
- ストレージ コストの削減 (通常) vs Avro
- 数列しか必要としない場合、データの読み取りが 10 ~ 100 倍向上する
レコードのスループットが 100 倍向上することのメリットは、いくら強調してもし過ぎることはありません。
2016年に行われたClouderaのケーススタディで、200GB未満の小さなデータセットを対象に、このメリットを説明します。
単純に行を数えた場合、Parquetが行グループのヘッダーに保存するメタデータのおかげで、ParquetはAvroを圧倒します。
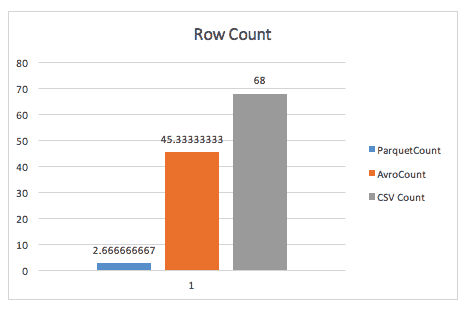
group-by クエリを実行しても、parquet はほぼ 2 倍速くなります (ただし、ここで使用された正確なクエリについては不明です)。
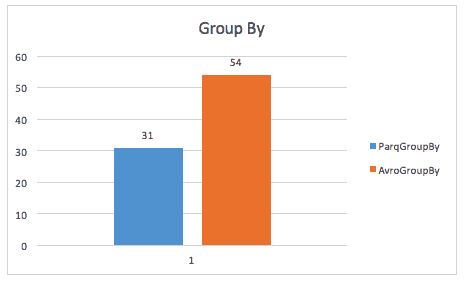
同じケーススタディでは、ストレージ スペースやテーブル全体のスキャンでも改善が見られましたが、これは Spark がより小さなデータ サイズをスキャンしなければならないためだと思われます。
- レコード全体を一度に読み取る場合、パフォーマンスでは Avro が勝っています。
- Parquet ファイルと Avro ファイルの書き込みでは、書き込み時間が大幅に増加します。
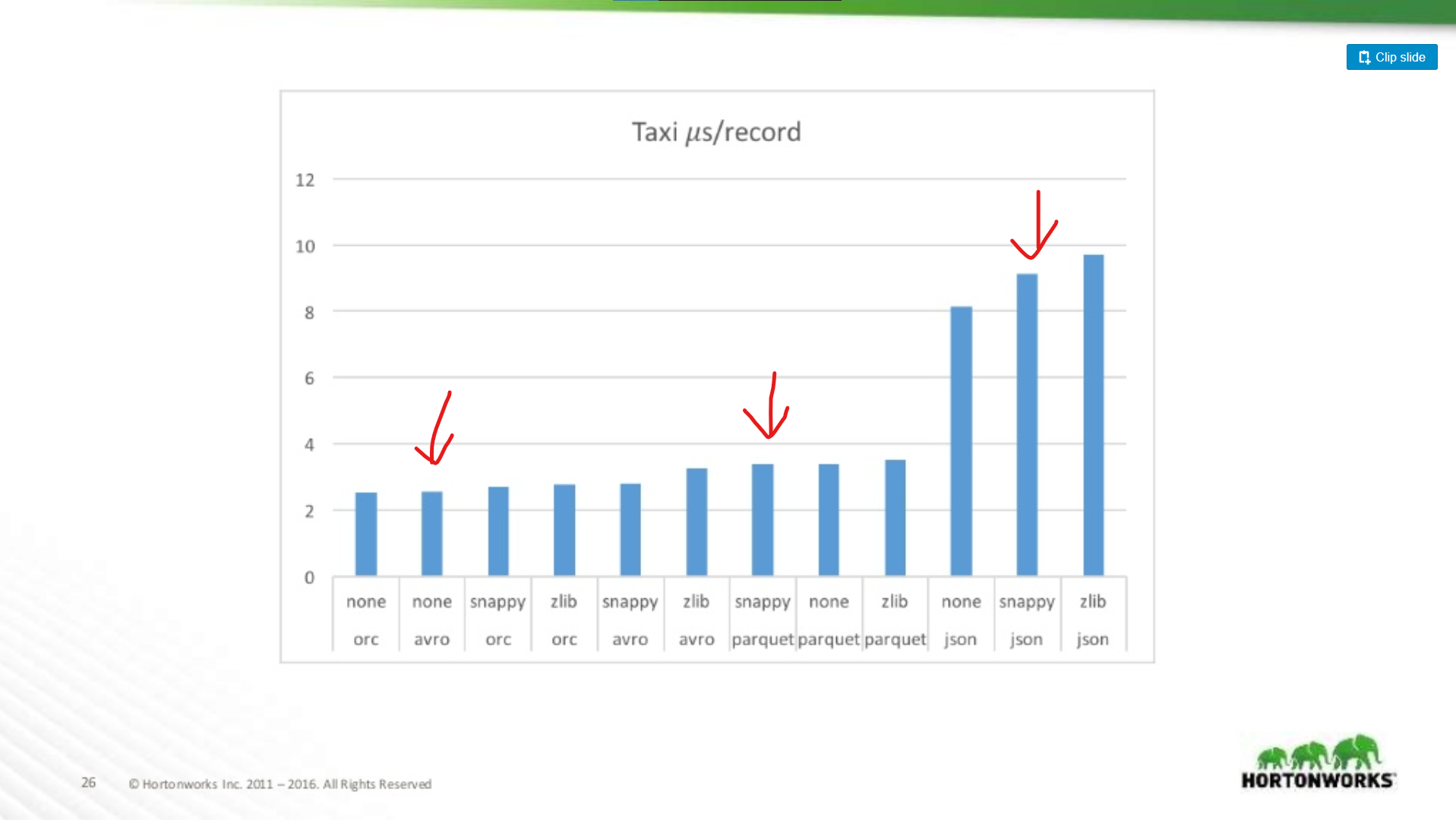
How much worse is Parquet for whole-record scans?
ここでは、約18列を含むTaxiデータセットで、Avro、JSON、Parquetのパフォーマンスを比較します。
もう一方では、レコードあたりのデータ数が極端に多い 704 カラムの Github データ ダンプに対して実行しました。
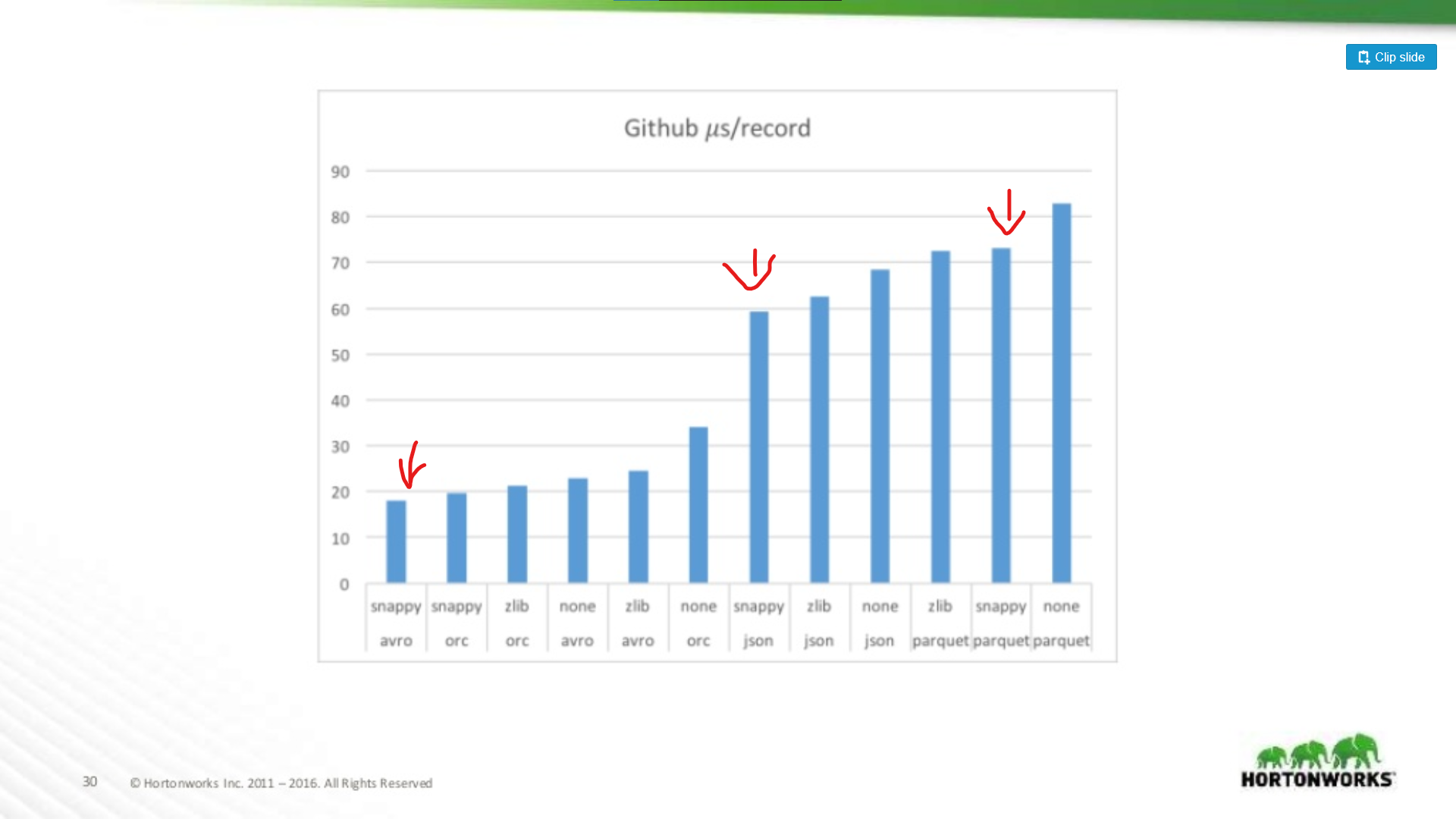
つまり、データセットが広くなればなるほど、Parquet はレコード全体をスキャンするのに不利になるということです (これは理にかなっています)。
Parquet への投資
とはいえ、Parquet のマイナス面を軽減するには、多大な投資が必要になります。
Avro ではフル レコードの読み取りが遅くなる場合でも、Parquet よりも Avro を主張する人をまだ見かけることがあります。 私の意見は、「ストレージは安い! CPU はそうではありません。 同じ記事によると、ファイルから1つの列だけを読み取る場合、200倍以上のパフォーマンス上の利点があります。
Parquet はどちらにしても正しい選択でしょう
では、データセットが MapReduce のためだけのものであれば、Avro にするべきでしょうか。 データセットの内部を「覗き見」して、その内容についての情報を素早く見つけることができるのは、非常に便利です。 Parquetはアナリティクスだけではありません!
プロダクションジョブのランタイムを無視しても、アナリティクスワークロード以外でParquetを使用する私のお気に入りの方法をいくつか紹介しましょう:
-
データ検証 – データが完全であることを確認するために大まかなカウントを行う必要がありますか?
-
デバッグ – パイプラインは正しいことをしましたか? 正しいレコードを追加/削除/変更しましたか?
-
クイック メトリクス抽出 – データセット内のレコードのサブセットのカウントを監視システムに記録したいと思いませんか?
-
Less redundancy – 2つの異なるパイプラインに同様のデータセットが必要ですか?
-
Analytics – Ok, I cheated and put it anyway. SQL クエリを実行している人は誰でも、クエリが最大 1000 倍速く実行されると、SQL プロンプトの前で 1 日に何時間も過ごす必要がなくなり、あなたに感謝するでしょう。
My Take: Just Use Parquet
Parquet よりも Avro の方が使用例があると思いますが、それらの使用例は減少しています。 例えば、Amazon Web Services を見てください。 彼らは使用状況のデータ ダンプを Parquet (または CSV) で提供し、彼らの EMR 製品は Parquet のための特別な書き込み最適化を提供しています。
-
- MapReduceのようなフレームワークは、Sparkのようなよりダイナミックなフレームワークに取って代わられています。これらのフレームワークは、必要なカラムだけを処理し、残りのカラムは無視するという「データフレーム」スタイルのプログラミングに適しています。
- Parquetはとにかく柔軟性が高い。 常にデータセットをスパース クエリにする必要はないかもしれませんが、スパース クエリができると、さまざまな状況で非常に便利です。 Avro、CSV、JSONではできないことです。