Statistische Definities > Factoranalyse
Inhoud:
- Wat is Factoranalyse?
- Factor Ladingen
- Meervoudige Factor Analyse
- Bevestigende Factor Analyse
- Exploratieve Factor Analyse
- Wat is Gegeneraliseerde Procrustes Analyse (GPA)
- Wat zijn Latente Variabelen?
- Wat zijn Manifeste Variabelen?
Wat is Factoranalyse?
Factoranalyse is een manier om een massa gegevens te nemen en deze te verkleinen tot een kleinere gegevensverzameling die beter beheersbaar en begrijpelijker is. Het is een manier om verborgen patronen te vinden, te laten zien hoe die patronen elkaar overlappen en te laten zien welke kenmerken in meerdere patronen voorkomen. Het wordt ook gebruikt om een reeks variabelen te creëren voor soortgelijke items in de verzameling (deze reeksen variabelen worden dimensies genoemd). Het kan een zeer nuttig hulpmiddel zijn voor complexe gegevensreeksen waarbij psychologische studies, sociaal-economische status en andere betrokken begrippen een rol spelen. Een “factor” is een reeks waargenomen variabelen die gelijksoortige antwoordpatronen vertonen; zij worden geassocieerd met een verborgen variabele (een confounding variabele genoemd) die niet rechtstreeks wordt gemeten. Factoren worden gerangschikt volgens factorladingen, of hoeveel variatie in de gegevens ze kunnen verklaren.
De twee typen: exploratieve en confirmatieve.
- Exploratieve factoranalyse is als u geen idee hebt van de structuur van uw gegevens of hoeveel dimensies er in een verzameling variabelen zitten.
- Bevestigende factoranalyse wordt gebruikt voor verificatie als u een bepaald idee hebt over welke structuur uw gegevens hebben of hoeveel dimensies er in een reeks variabelen zitten.
Factorladingen
Image:USGS.gov
Niet alle factoren zijn gelijk geschapen; sommige factoren hebben meer gewicht dan andere. Een eenvoudig voorbeeld: stel dat uw bank een telefonisch onderzoek uitvoert naar de klanttevredenheid en dat de resultaten de volgende factorladingen laten zien:
| Variabele | Factor 1 | Factor 2 | Factor 3 | Vraag 1 | 0.885 | 0,121 | -0,033 |
|---|---|---|---|
| Vraag 2 | 0,829 | 0,078 | 0,157 |
| Vraag 3 | 0,777 | 0,190 | 0.540 |
De factoren die de vraag het meest beïnvloeden (en dus de hoogste factorladingen hebben) zijn vetgedrukt. Factorladingen zijn vergelijkbaar met correlatiecoëfficiënten in die zin dat ze kunnen variëren van -1 tot 1. Hoe dichter factoren bij -1 of 1 liggen, hoe meer ze de variabele beïnvloeden. Een factorlading van nul wijst op geen effect.
Terug naar boven
Meervoudige factoranalyse
Deze subset van factoranalyse wordt gebruikt wanneer uw variabelen zijn gestructureerd in variabele groepen. U kunt bijvoorbeeld een vragenlijst hebben over de gezondheid van studenten, met verschillende items zoals slaappatronen, verslavingen, psychische gezondheid, of leerstoornissen.
De twee stappen die worden uitgevoerd in Meervoudige Factoranalyse zijn:
- Principale Componenten Analyse wordt uitgevoerd op elke set gegevens. Dit levert een eigenwaarde op, die wordt gebruikt om de datasets te normaliseren.
- De nieuwe datasets worden samengevoegd tot een unieke matrix en een tweede, globale PCA wordt uitgevoerd.
Uitvoeren van Factoranalyse
Factoranalyse is een uiterst complexe wiskundige procedure en wordt uitgevoerd met software.
Instructies voor Stata zijn hier te vinden.
Minitab instructies zijn hier te vinden.
Voor SPSS, zie dit artikel.
De Kaiser-Meyer-Olkin test controleert of uw data geschikt zijn voor FA.
Terug naar Boven
Wat is Confirmatory Factor Analysis?
Confirmatory Factor Analysis stelt een onderzoeker in staat om uit te vinden of er een relatie bestaat tussen een set van waargenomen variabelen (ook bekend als manifeste variabelen) en hun onderliggende constructen. Het is gelijkaardig aan Onderliggende Factoranalyse. Het belangrijkste verschil tussen de twee is:
- Als u patronen wilt onderzoeken, gebruik dan EFA.
- Als u hypothese-onderzoek wilt doen, gebruik dan CFA.
EFA geeft informatie over het optimale aantal factoren dat nodig is om de gegevensverzameling weer te geven. Met Confirmatory Factor Analysis kunt u het aantal benodigde factoren specificeren. CFA kan bijvoorbeeld vragen beantwoorden als “Meet mijn enquête van tien vragen nauwkeurig één specifieke factor?”. Hoewel het technisch toepasbaar is op elk vakgebied, wordt het typisch gebruikt in de sociale wetenschappen.
Invoering van Confirmatory Factor Analysis
Diane Suhr, PhD, op de SAS-website, stelt de volgende stappen voor:
- Voer een literatuurstudie uit om u te helpen een geschikt model te kiezen. U zou bijvoorbeeld een diagram of vergelijkingen kunnen kiezen.
- Bepaal of unieke waarden mogelijk zijn voor de schatting van de populatieparameters.
- Verzamel uw gegevens.
- Voer een eerste gegevensanalyse uit om te controleren op problemen zoals ontbrekende gegevens, collineariteit of uitschieters.
- Bepaal de schatting van de populatieparameters.
- Bepaal of het model dat u hebt gekozen, werkt. Als het model onaanvaardbaar is, overweeg dan het uitvoeren van Verklarende Factoranalyse.
- Interpreteer uw resultaten.
Volgens IBM, heeft EFA CFA ingehaald als middel voor Factoranalyse. “De overheersende CFA-benadering is tegenwoordig CFA te beschouwen als een speciaal geval van structural equation modeling (SEM). Je specificeert factorladingen als een reeks regressieverklaringen van de factor naar de waargenomen variabelen.” Met EFA is het mogelijk om een paar factoren en een bepaalde rotatie te specificeren; je kunt dan je resultaten vergelijken om te zien of ze in je model passen.
Uitvoeren van CFA
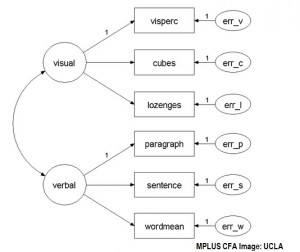
Er is meestal software nodig om een bevestigende factoranalyse uit te voeren. SAS kan worden gebruikt om CFA uit te voeren. Op het moment van schrijven is SPSS beperkt tot EFA.
- SAS CFA procedure.
- AMOS instructies (downloaddocument van East Carolina University).
- AMOS, LISREL, MPLUS procedures.
Back to Top
Wat is Onderliggende Factoranalyse?
Exploratieve Factoranalyse (EFA) wordt gebruikt om de onderliggende structuur van een grote verzameling variabelen te vinden. Het reduceert gegevens tot een veel kleinere set samenvattende variabelen.
EFA is bijna identiek aan Confirmatory Factor Analysis(CFA). Beide technieken kunnen (misschien verrassend) worden gebruikt om te bevestigen of te onderzoeken. Overeenkomsten zijn:
- Bepaal de interne betrouwbaarheid van een maat.
- Onderzoek factoren of theoretische constructen die door itemreeksen worden gerepresenteerd. Ze gaan ervan uit dat de factoren niet gecorreleerd zijn.
- Onderzoek de kwaliteit van individuele items.
Er zijn echter enkele verschillen, die vooral te maken hebben met de manier waarop factoren worden behandeld/gebruikt. EFA is in principe een datagestuurde benadering, waarbij alle items op alle factoren mogen laden, terwijl u bij CFA moet specificeren welke factoren moeten worden geladen. EFA is een goede keuze als u geen idee hebt van welke gemeenschappelijke factoren er zouden kunnen bestaan. EFA kan een groot aantal mogelijke modellen voor uw gegevens genereren, iets wat niet mogelijk is als een onderzoeker factoren moet specificeren. Als u wel een idee heeft over hoe de modellen eruit zien, en u wilt uw hypotheses over de datastructuur toetsen, dan is CFA een betere aanpak.
Wat is Generalized Procrustes Analysis (GPA)?
Procrustes-analyse is een manier om twee reeksen configuraties, of vormen, met elkaar te vergelijken. De techniek werd oorspronkelijk ontwikkeld om twee oplossingen uit Factoranalyse met elkaar te vergelijken, maar werd uitgebreid tot Generalized Procrustes Analysis, zodat meer dan twee vormen konden worden vergeleken. De vormen worden uitgelijnd met een doelvorm of met elkaar.
GPA gebruikt geometrische transformaties (d.w.z. isotrope herschaling, spiegeling, rotatie of translatie) van matrices om de reeksen gegevens te vergelijken. De volgende afbeelding toont een serie transformaties op een groene doeldriehoek.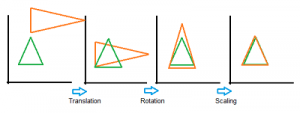
De consensus matrix is (zoals de naam al aangeeft), het resultaat van de gemiddelden van alle input matrices. De matrices die tijdens het proces van Generalized Procrustes Analysis worden gevormd, kunnen worden ingevoerd in Principal Components Analysis en worden geprojecteerd op een tweedimensionale ruimte voor gemakkelijk te begrijpen resultaten.
Gebruik in sensorische profilering
Generalized Procrustes Analysis is een manier om een onderliggende structuur te vinden in sensorische profilering, die in twee categorieën valt: conventionele profilering en vrije-keuze profilering.
Bij conventionele profilering wordt de beoordelaars een vaste set beschrijvende termen ter beschikking gesteld. De beoordelaars zijn gewoonlijk hoog opgeleide personen. U kunt bijvoorbeeld drie deskundigen vragen naar hun mening over de body, de geur en de smaak van vier wijnmerken. De vaste omschrijvingen zouden kunnen zijn: knapperig, hoekig en boterachtig. De resultaten kunnen worden gemiddeld, zodat het mogelijk is om Factoranalyse of Principal Component Analysis – evenals GPA – te gebruiken om de test te analyseren.
Vrije-keuze profilering geeft respondenten de vrijheid om vragen in hun eigen beschrijvende termen te beantwoorden. Aangezien er geen vaste termen zijn om het gemiddelde van te bepalen, is het niet mogelijk om factoranalyse of PCA te gebruiken. Bij dit soort free-choice profiling wordt gebruik gemaakt van K-sets methoden, zoals PCA.
De categorieën zijn de dimensies van de Generalized Procrustes Analysis. Idealiter is het aantal dimensies over de hele linie gelijk (in dit voorbeeld zou dat betekenen dat de deskundige op alle drie de gebieden een waardering heeft gegeven). Het is echter mogelijk om een gegeneraliseerde Procrustes-analyse uit te voeren met ongelijke dimensies.
Terug naar boven
Wat zijn latente variabelen?
 Een latente variabele of “verborgen” variabele wordt over het algemeen gezien als een variabele die niet direct meetbaar of waarneembaar is. Bijvoorbeeld het niveau van neurose, consciëntieusheid of openheid van een persoon zijn allemaal latente variabelen. Hoewel je deze onderliggende variabelen niet kunt zien (ze maken geen deel uit van de dataset van een experiment) kunnen ze wel effecten veroorzaken in je experimentele resultaten. Latente variabelen zijn ook bekend als:
Een latente variabele of “verborgen” variabele wordt over het algemeen gezien als een variabele die niet direct meetbaar of waarneembaar is. Bijvoorbeeld het niveau van neurose, consciëntieusheid of openheid van een persoon zijn allemaal latente variabelen. Hoewel je deze onderliggende variabelen niet kunt zien (ze maken geen deel uit van de dataset van een experiment) kunnen ze wel effecten veroorzaken in je experimentele resultaten. Latente variabelen zijn ook bekend als:
- Constructen of Hypothetische Constructen.
- Factoren.
- Verborgen Variabelen.
- Hypothetische Variabelen.
- Trouwe scores.
- Ongemeten variabelen.
- Onwaargenomen variabelen.
Een van de vroegste voorbeelden van een latente variabele werd gepubliceerd in 1904 toen Spearman intelligentie mat met behulp van factoranalyse. Soms wordt een nauwkeuriger definitie van latente variabelen gebruikt. Zo beschrijft MacCallum & Austin(2000) deze variabelen als “hypothetische constructen die niet direct kunnen worden gemeten.” Ze zijn hypothetisch omdat ze alleen bestaan in de gedachten van de onderzoeker.
De Latente Variabele in Statistische Modellering
Latente variabelen worden soms gebruikt in statistische modelleringstechnieken zoals Factoranalyse, waar ze kunnen worden afgeleid door middel van modelleringstechnieken. Latente variabelen zijn altijd aanwezig in bijna alle regressieanalyses, omdat alle additieve fouttermen niet meetbaar zijn (en dus latent zijn).
Statistische modelleringsmethoden die vaak worden gebruikt om latente variabelen te identificeren zijn onder andere:
- EM Algoritmen.
- Factoranalyse.
- Verborgen Markov Modellen.
- Latente Semantische Analyse.
- Principale Componenten Analyse.
- Structurele Vergelijkings Modellering.
Een latente variabele kan ook aanwezig zijn (en in een model worden opgenomen) wanneer er geen doel is om deze daadwerkelijk te meten. Melanie Wall van Columbia University geeft de volgende drie voorbeelden van latente variabelen die niet bedoeld zijn om gemeten te worden:
- Onverwachte heterogeniteit (bv. onvolkomenheden in overlevingsanalyses, willekeurige effecten in longitudinale gegevens of geclusterde gegevens)
- Missende gegevens
- Counterfactuals of ‘potentiële uitkomsten’
Back to Top
Wat zijn Manifest Variabelen?
Manifeste variabelen (ook wel waarneembare variabelen genoemd) kunnen direct worden gemeten of waargenomen. Zij zijn het tegenovergestelde van latente variabelen. Leeftijd en geslacht zijn bijvoorbeeld waarneembare variabelen. Het is echter zeldzaam dat je 100% zeker kan zijn over een variabele; zelfs “geslacht”, indien geobserveerd, is niet 100% zeker, omdat mensen kunnen liegen op hun formulier, hun echte geslacht kunnen verhullen, of een transgender persoon kunnen zijn. Daarom moet je waar mogelijk latente variabelen gebruiken.
Referentie:
MacCallum RC, Austin JT. 2000. Applications of structural equation modeling in psychological research. Annu. Rev. Psychol. 51:
201-26
Stephanie Glen. “Factoranalyse: Eenvoudige definitie” Van StatisticsHowTo.com: Elementaire Statistiek voor de rest van ons! https://www.statisticshowto.com/factor-analysis/
——————————————————————————
Heb je hulp nodig bij een huiswerk of toetsvraag? Met Chegg Study kunt u stap-voor-stap oplossingen voor uw vragen krijgen van een expert op dit gebied. Uw eerste 30 minuten met een Chegg-leraar zijn gratis!