Als u mijn inleiding tot Hadoop/Spark-bestandsindelingen hebt gelezen, weet u dat er meerdere manieren zijn om gegevens op te slaan in HDFS, S3 of Blob-opslag, en dat elk van deze bestandstypen verschillende eigenschappen heeft die ze goed (of slecht) maken voor verschillende dingen.
Hoewel dit artikel geen technisch diepgravend artikel is, geef ik je een overzicht van waarom (en hoe) je Parquet zou moeten gebruiken in plaats van een ander populair formaat, Avro.
Wat is Parquet?
Op een hoog niveau is parquet een bestandsformaat voor het opslaan van gestructureerde gegevens. U kunt parquet bijvoorbeeld gebruiken om een aantal records op te slaan die er als volgt uitzien:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}U kunt deze gegevens in feite in bijna elk bestandsformaat opslaan, een leesvriendelijke manier om deze gegevens op te slaan is in een CSV- of TSV-bestand. Hier ziet u hoe sommige gegevens in dit schema eruit zouden kunnen zien in een CSV-formaat:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, In een JSON flat file zouden we elke rij opslaan als een JSON-object:
Hier tegenover staat een screenshot van dezelfde gegevens in een illustratief kolomvormig bestandsformaat dat ik Columnar CSV (CCSV) noem:
Verbaasd over kolomvormige bestandsformaten? Lees eerst mijn inleiding over kolomvormige bestandsformaten voordat u verder gaat
Totally different right? Parquet gaat nog een stap verder – het is een binair formaat, niet een tekstgebaseerd formaat. Maak je geen zorgen, er zijn genoeg tools die je kunt gebruiken om Parquet-bestanden te inspecteren en lezen en zelfs de resultaten te exporteren naar het goede oude JSON. Bijvoorbeeld Parquet Tools
Parquet Cares About Your Schema
Eén beperking van CSV/TSV data is dat u niet weet wat het exacte schema zou moeten zijn, of het gewenste type van elk veld.
Gebruik makend van ons voorbeeld hierboven, zonder het schema, moeten de ‘True’ waarden dan worden omgezet in booleaans? Hoe kunnen we daar zeker van zijn zonder het schema van tevoren te kennen?
JSON is een verbetering ten opzichte van CSV, omdat elke rij een indicatie geeft van het schema, maar zonder een speciale header-rij is er geen manier om een schema af te leiden voor elk record in het bestand, en het is niet altijd duidelijk als welk type een ‘null’-waarde moet worden geïnterpreteerd.
Avro en Parquet daarentegen begrijpen het schema van de gegevens die ze opslaan. Wanneer je een bestand in deze formaten schrijft, moet je je schema specificeren. Als je het bestand terugleest, krijg je het schema van de gegevens die erin zijn opgeslagen. Dit is super handig voor een framework als Spark, die deze informatie kan gebruiken om je met minimale inspanning een volledig gevormd data-frame te geven.
Laten we het eens hebben over Parquet vs Avro
Op het eerste gezicht lijken Avro en Parquet op elkaar: ze schrijven allebei het schema van hun ingesloten data in een file header en gaan goed om met schema drift (toevoegen/verwijderen van kolommen). Ze zijn in dit opzicht zo vergelijkbaar dat Parquet zelfs Avro-schema’s ondersteunt, zodat je je Avro-pijplijnen in een handomdraai naar Parquet-opslag kunt migreren.
Het grote verschil tussen de twee formaten is dat Avro gegevens PER ROW opslaat, en Parquet gegevens PER COLUMN.
- Oh hai! Vergeet mijn gids over kolom-bestandsformaten niet als je er meer over wilt weten
Voordelen van Parquet boven Avro
Om terug te komen op mijn gids over kolom-bestandsformaten: de voordelen van Parquet (en kolom-bestandsformaten in het algemeen) zijn vooral tweeledig:
- Verlaagde opslagkosten (typisch) in vergelijking met Avro
- 10-100x verbetering bij het lezen van gegevens wanneer je maar een paar kolommen nodig hebt
Ik kan het voordeel van een 100x verbetering in recorddoorvoer niet overschatten. Het biedt echt een enorme en fundamentele verbetering voor dataverwerkingspijplijnen die heel moeilijk over het hoofd te zien is.
Hier is een illustratie van dit voordeel uit een Cloudera-casestudy uit 2016 op een kleine dataset van minder dan 200 GB.
Bij het simpelweg tellen van rijen blaast Parquet Avro weg, dankzij de metadata die Parquet opslaat in de header van rijgroepen.
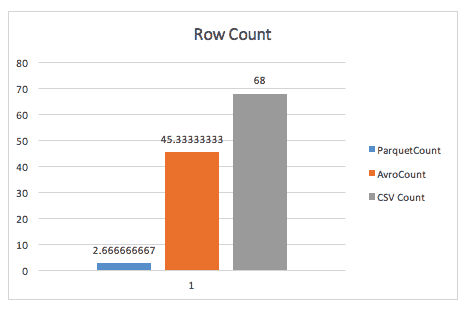
Bij het uitvoeren van een group-by query is Parket nog steeds bijna 2x sneller (hoewel ik niet zeker weet welke query hier precies is gebruikt).
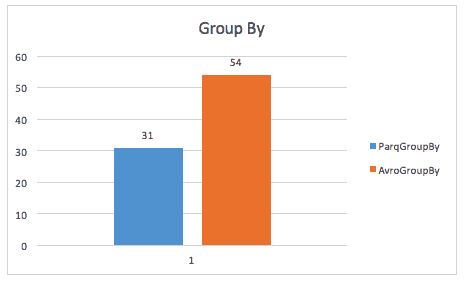
In dezelfde casestudy worden ook verbeteringen gevonden in de opslagruimte, en zelfs in het scannen van volledige tabellen, waarschijnlijk doordat Spark een kleinere datagrootte hoeft te scannen.
Voordelen van Avro boven Parquet
Ik heb sommige mensen horen pleiten voor Avro versus Parquet. Zulke argumenten zijn meestal gebaseerd op twee punten:
- Wanneer je hele records in één keer leest, wint Avro qua prestaties.
- De schrijftijd neemt drastisch toe bij het schrijven van Parquet-bestanden vs. Avro-bestanden
Hoewel deze twee punten geldig zijn, zijn het kleine voetnoten tegenover de prestatieverbeteringen van Parquet in het algemeen. Er zijn veel benchmarks online beschikbaar voor Avro vs Parquet, maar laat ik een grafiek tekenen uit een Hortonworks 2016 presentatie waarin de prestaties van het bestandsformaat in verschillende situaties worden vergeleken.
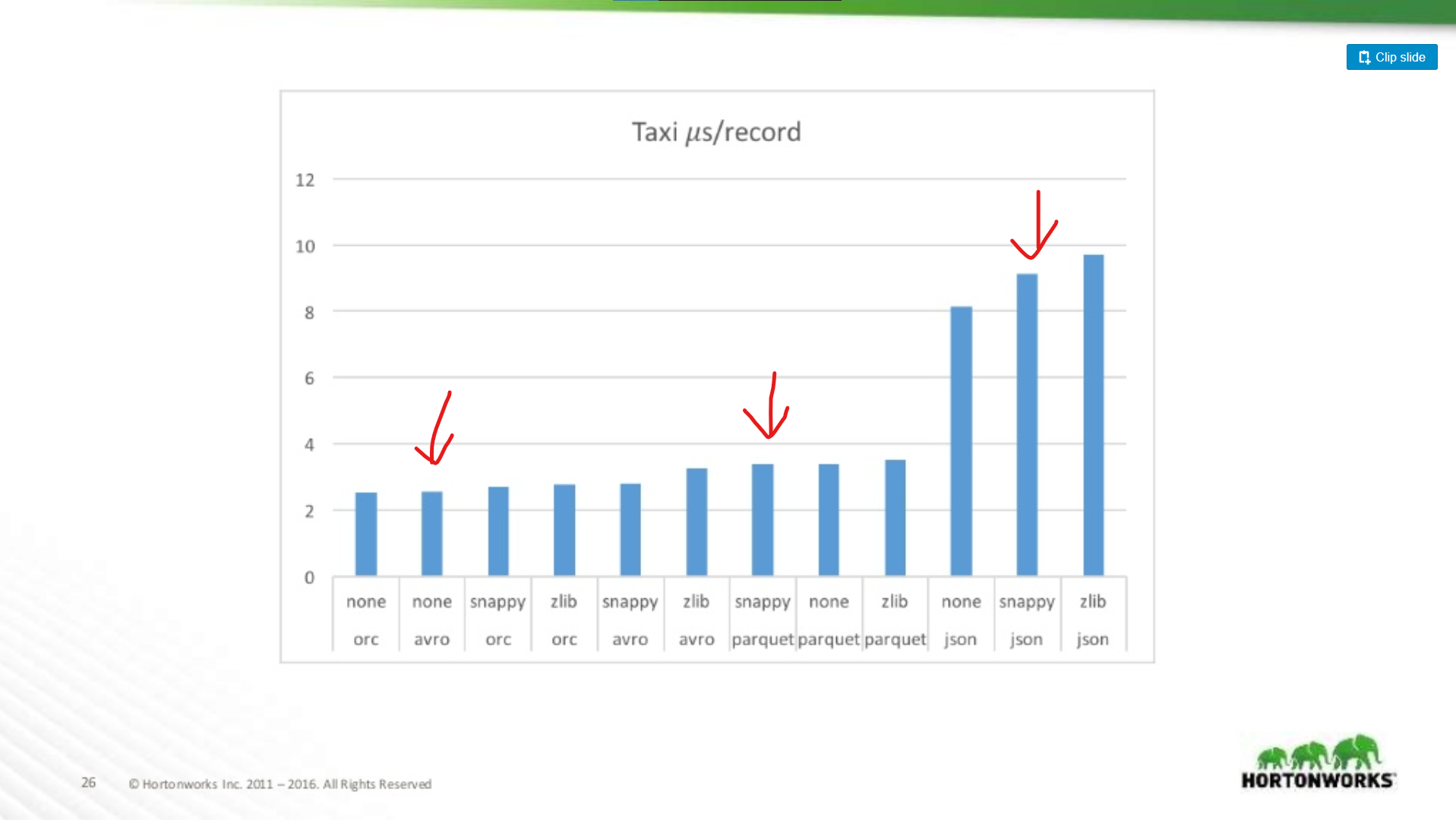
Hoeveel slechter is Parquet voor whole-record scans?
Hier vergelijken we de prestaties van Avro, JSON en Parquet op een Taxi-dataset met ~18 kolommen. In deze test werden hele records gelezen als onderdeel van een MapReduce-taak, dit type werkbelasting is de slechtst denkbare prestatie van Parquet, en hier komt het bijna overeen met de leesprestatie van Avro.
Aan de andere kant van het spectrum werd een Github-datadump gebruikt met een extreme hoeveelheid van 704 kolommen data per record. Hier zien we een significanter voordeel voor Avro:
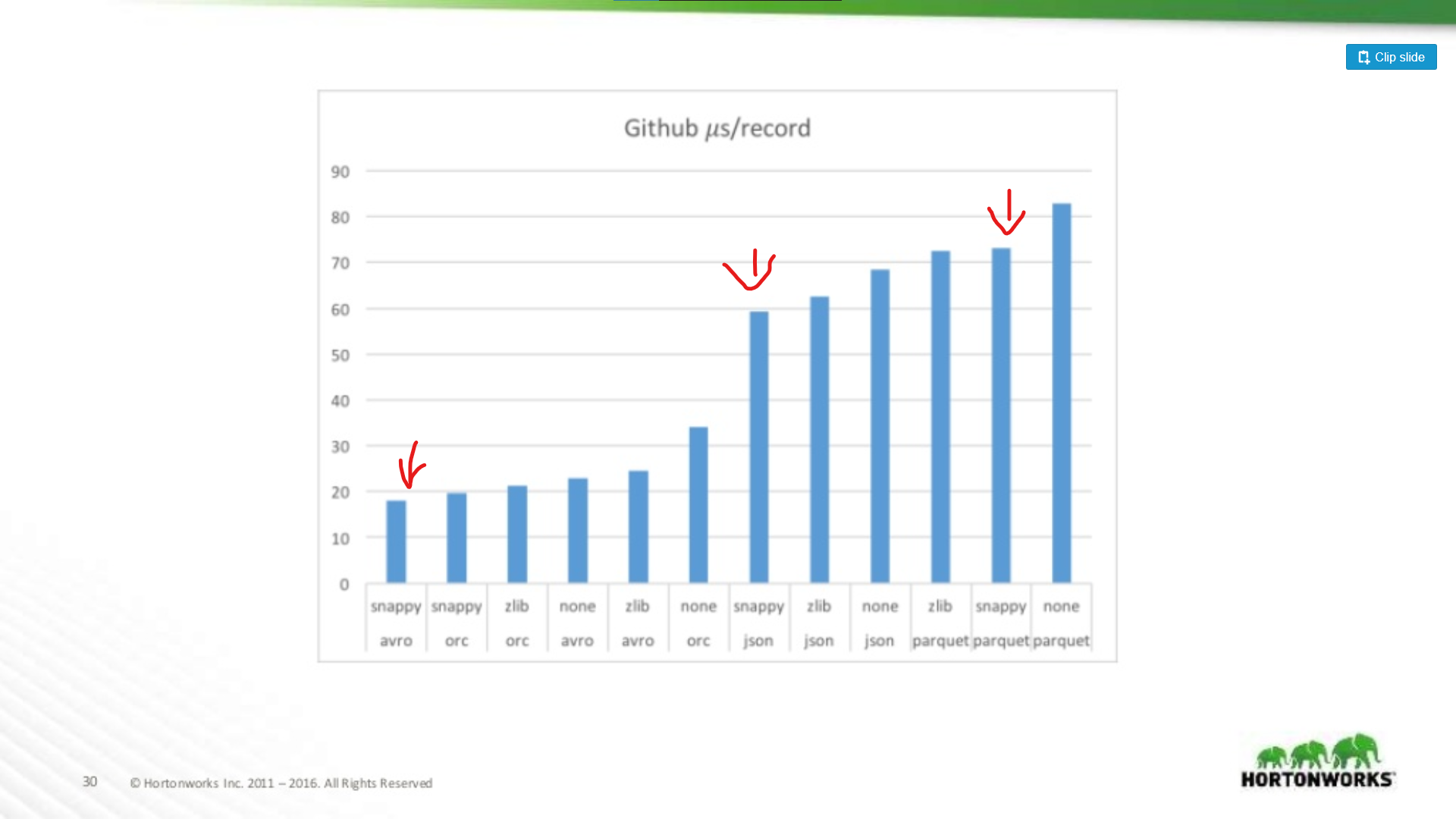
Dus hoe breder je dataset, hoe slechter Parquet wordt voor het scannen van volledige records (wat logisch is). Dit is een extreem voorbeeld, de meeste datasets zijn geen 700 kolommen breed, voor alles wat redelijk is (< 100) ligt de leesprestatie van Parquet dicht genoeg bij die van Avro om er niet toe te doen.
Parquet Investeringen
Dat gezegd hebbende, het verzachten van de negatieve aspecten van Parquet is een aandachtspunt van aanzienlijke investeringen. Zie bijvoorbeeld dit artikel van Cloudera over het gebruik van vectorisatie om de CPU-overhead van parquet te beperken.
Ik zie nog steeds mensen pleiten voor Avro boven Parquet, zelfs als full-record reads langzamer zijn in Avro. Mijn mening is dat opslag goedkoop is! CPU’s zijn dat niet. Datzelfde artikel laat een prestatievoordeel zien van meer dan 200x bij het lezen van slechts een enkele kolom uit het bestand. Dat is echt significant, en als je dataset groeit zal het een aanzienlijke hoeveelheid rekenkracht besparen.
Parquet is probably the right choice Either Way
Dus als een dataset alleen voor MapReduce is, moet hij dan in Avro? Nee. Het is enorm handig om in een dataset te kunnen ‘gluren’ en snel informatie te vinden over de inhoud, bovendien voegen veel MapReduce frameworks predicate-pushdown toe aan hun parquet ondersteuning. Parquet is niet alleen voor Analytics!
Even afgezien van de runtime van je productie jobs, laat me een paar van mijn favoriete manieren schetsen om Parquet te gebruiken buiten analytics workloads:
-
Data validatie – moet je een paar ruwe tellingen doen om te controleren of je data compleet is? Dergelijke controles kunnen in een paar seconden worden uitgevoerd met Parquet, zelfs met een dataset van 1 TB.
-
Debugging – heeft je pipeline het juiste gedaan? Heeft het de juiste records toegevoegd/verwijderd/gewijzigd? Met parquet kun je snel en eenvoudig informatie vastleggen (zoals alle unieke waarden van een kolom) in een paar seconden zonder het hele bestand te scannen.
- Snelle Metrics Extractie – wil je in je monitoring systeem een telling vastleggen van een subset van records in je dataset? Voorheen legde ik deze informatie vast door een vervolg pipeline uit te voeren, maar met Parquet is het een zeer snelle query via ofwel Hive of Spark SQL.
Minder redundantie – Heb je een vergelijkbare dataset nodig voor twee verschillende pipelines? In plaats van het bouwen van een aparte dataset voor elk, Parquet kunt u gewoon dynamisch query’s een grotere, uitgebreide dataset zonder de sancties van het scannen van een heel bestand.
Analytics – Ok, ik vals gespeeld en zet het er toch in. Ja, Parquet is AMAZING voor analytics, iedereen die SQL queries uitvoert zal je bedanken voor het besparen van uren per dag voor een SQL prompt wanneer hun queries tot 1000x sneller lopen.
Mijn mening: gebruik gewoon Parquet
Terwijl ik denk dat er use-cases zijn voor Avro boven Parquet, zijn die use-cases aan het vervagen.
- Industrie tooling is zich aan het samenballen rond Parquet als een standaard data opslag formaat. Kijk bijvoorbeeld naar Amazon Web Services. Zij geven je een gebruiksdatadump in Parquet (of CSV), en hun EMR-product biedt speciale schrijf-optimalisaties voor Parquet. Hetzelfde geldt niet voor Avro.
- Frameworks zoals MapReduce stappen opzij ten gunste van meer dynamische frameworks, zoals Spark, deze frameworks zijn voorstander van een ‘dataframe’ stijl van programmeren waarbij je alleen de kolommen verwerkt die je nodig hebt, en de rest negeert. Dit is geweldig voor Parquet.
- Parquet is gewoon flexibeler. Hoewel je misschien niet altijd een dataset hoeft te sparse-queryen, is de mogelijkheid daartoe verdomd nuttig in een reeks situaties. Dat kun je gewoon niet doen met Avro, CSV of JSON.