TCP protocolbewerkingen kunnen in drie fasen worden verdeeld. Het tot stand brengen van een verbinding is een handshake-proces dat uit meerdere stappen bestaat en waarbij een verbinding tot stand wordt gebracht voordat wordt overgegaan tot de fase van gegevensoverdracht. Nadat de gegevensoverdracht is voltooid, wordt de verbinding gesloten en worden alle toegewezen bronnen vrijgegeven.
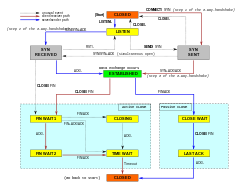
Een TCP-verbinding wordt door een besturingssysteem beheerd via een bron die het lokale eindpunt voor communicatie vertegenwoordigt, de Internet socket. Tijdens de levensduur van een TCP-verbinding ondergaat het lokale eindpunt een reeks toestandsveranderingen:
| State | Endpoint | Omschrijving |
|---|---|---|
| LISTEN | Server | Wachtend op een verbindingsverzoek van een willekeurig TCP-eindpunt op afstandpunt. |
| SYN-SENT | Client | Wacht op een overeenkomend verbindingsverzoek na een verbindingsverzoek te hebben verzonden. |
| SYN-RECEIVED | Server | Wacht op een bevestiging van een verbindingsverzoek na zowel een verbindingsverzoek te hebben ontvangen als verzonden. |
| ESTABLISHED | Server en client | Een open verbinding, de ontvangen gegevens kunnen aan de gebruiker worden geleverd. De normale toestand voor de fase van gegevensoverdracht van de verbinding. |
| FIN-WAIT-1 | Server en client | Wachtend op een verbindingsbeëindigingsverzoek van de TCP op afstand, of een bevestiging van het eerder verzonden verbindingsbeëindigingsverzoek. |
| FIN-WAIT-2 | Server en client | Wachten op een verbindingsbeëindigingsverzoek van de remote TCP. |
| CLOSE-WAIT | Server en client | Wachten op een verbindingsbeëindigingsverzoek van de lokale gebruiker. |
| CLOSING | Server en client | Wacht op een verbindingsbeëindigingsverzoek bevestiging van de remote TCP. |
| LAST-ACK | Server en client | Wachten op een bevestiging van het verbindingsbeëindigingsverzoek dat eerder naar de TCP op afstand is gestuurd (en dat een bevestiging bevat van zijn verbindingsbeëindigingsverzoek). |
| TIME-WAIT | Server of client | Wachten tot er genoeg tijd is verstreken om er zeker van te zijn dat de TCP op afstand de bevestiging van zijn verbindingsbeëindigingsverzoek heeft ontvangen. |
| CLOSED | Server en client | Geen enkele verbindingsstatus. |
Connection establishmentEdit
Voordat een client verbinding probeert te maken met een server, moet de server zich eerst binden aan en luisteren op een poort om deze open te stellen voor verbindingen: dit wordt een passive open genoemd. Zodra de passive open tot stand is gebracht, kan een client een verbinding tot stand brengen door een active open te initiëren met behulp van de three-way (of 3-step) handshake:
- SYN: De active open wordt uitgevoerd door de client die een SYN naar de server stuurt. De client stelt het volgnummer van het segment in op een willekeurige waarde A.
- SYN-ACK: Als antwoord antwoordt de server met een SYN-ACK. Het bevestigingsnummer is ingesteld op één meer dan het ontvangen volgnummer, d.w.z. A+1, en het volgnummer dat de server kiest voor het pakket is een ander willekeurig getal, B.
- ACK: Tenslotte stuurt de client een ACK terug naar de server. Het volgnummer wordt ingesteld op de ontvangen bevestigingswaarde, d.w.z. A+1, en het bevestigingsnummer wordt ingesteld op één meer dan het ontvangen volgnummer, d.w.z. B+1.
Stappen 1 en 2 stellen het volgnummer voor één richting vast en bevestigen dit. In stap 2 en 3 wordt het volgnummer voor de andere richting vastgelegd en bevestigd. Na voltooiing van deze stappen hebben zowel de client als de server bevestigingen ontvangen en is een full-duplex communicatie tot stand gebracht.
Beëindiging van de verbinding

De fase voor het beëindigen van de verbinding maakt gebruik van een vier-weg handshake, waarbij elke zijde van de verbinding onafhankelijk wordt beëindigd. Wanneer een eindpunt zijn helft van de verbinding wil beëindigen, zendt het een FIN-pakket, dat door het andere eindpunt wordt bevestigd met een ACK. Daarom vereist een typische tear-down een paar FIN- en ACK-segmenten van elk TCP-eindpunt. Nadat de kant die de eerste FIN stuurde, heeft geantwoord met de laatste ACK, wacht hij op een timeout voordat hij uiteindelijk de verbinding sluit, gedurende welke tijd de lokale poort niet beschikbaar is voor nieuwe verbindingen; dit voorkomt verwarring als gevolg van vertraagde pakketten die worden afgeleverd tijdens volgende verbindingen.
Een verbinding kan “half-open” zijn, in welk geval de ene kant zijn einde heeft afgesloten, maar de andere kant niet. De partij die de verbinding heeft verbroken, kan geen gegevens meer naar de verbinding sturen, maar de andere partij wel. De kant die de verbinding verbreekt, moet doorgaan met het lezen van de gegevens totdat de andere kant ook de verbinding verbreekt.
Het is ook mogelijk om de verbinding te verbreken door een 3-weg handshake, waarbij host A een FIN stuurt en host B antwoordt met een FIN & ACK (combineert slechts 2 stappen in een) en host A antwoordt met een ACK.
Sommige besturingssystemen, zoals Linux en H-UX, implementeren een half-duplex close sequence in de TCP stack. Als de host actief een verbinding sluit, terwijl er nog ongelezen inkomende gegevens beschikbaar zijn, zendt de host het signaal RST (waarbij alle ontvangen gegevens verloren gaan) in plaats van FIN. Dit verzekert een TCP-applicatie ervan dat het remote proces alle verzonden data heeft gelezen door te wachten op het signaal FIN, voordat het actief de verbinding sluit. Het remote proces kan geen onderscheid maken tussen een RST signaal voor verbindingsafbreking en gegevensverlies. Beide veroorzaken dat de remote stack alle ontvangen gegevens verliest.
Sommige applicaties die het TCP open/close handshaking protocol gebruiken, kunnen het RST probleem bij actief sluiten tegenkomen. Als voorbeeld:
s = connect(remote);send(s, data);close(s);
Voor een programmastroom zoals hierboven beschreven, garandeert een TCP/IP-stack niet dat alle gegevens bij de andere toepassing aankomen als aan deze kant ongelezen gegevens zijn aangekomen.
BronnengebruikEdit
De meeste implementaties wijzen een entry toe in een tabel die een sessie aan een lopend besturingssysteemproces koppelt. Omdat TCP-pakketten geen sessie-identifier bevatten, identificeren beide eindpunten de sessie aan de hand van het adres en de poort van de client. Telkens wanneer een pakket wordt ontvangen, moet de TCP implementatie deze tabel doorzoeken om het bestemmingsproces te vinden. Elk gegeven in de tabel staat bekend als een Transmission Control Block of TCB. Het bevat informatie over de eindpunten (IP en poort), de status van de verbinding, lopende gegevens over de pakketten die worden uitgewisseld en buffers voor het zenden en ontvangen van gegevens.
Het aantal sessies aan de server-zijde is alleen beperkt door het geheugen en kan groeien naarmate er nieuwe verbindingen bijkomen, maar de client moet een willekeurige poort toewijzen voordat hij de eerste SYN naar de server stuurt. Deze poort blijft toegewezen gedurende de hele conversatie, en beperkt effectief het aantal uitgaande verbindingen van elk IP-adres van de client. Als een toepassing er niet in slaagt ongevraagde verbindingen op de juiste wijze te sluiten, kan een client zonder bronnen komen te zitten en niet meer in staat zijn nieuwe TCP-verbindingen tot stand te brengen, zelfs niet van andere toepassingen.
Beide eindpunten moeten ook ruimte toewijzen voor niet-geaccepteerde pakketten en ontvangen (maar ongelezen) gegevens.
Gegevensoverdracht
Het Transmission Control Protocol verschilt in een aantal belangrijke kenmerken van het User Datagram Protocol:
- Geordende gegevensoverdracht: de bestemmingshost herschikt segmenten volgens een volgnummer
- Hertransmissie van verloren pakketten: elke cumulatieve stroom die niet wordt bevestigd, wordt opnieuw verzonden
- Foutloze gegevensoverdracht
- Flow control: beperkt de snelheid waarmee een verzender gegevens overdraagt om een betrouwbare levering te garanderen. De ontvanger geeft de verzender voortdurend aanwijzingen over de hoeveelheid gegevens die kan worden ontvangen (geregeld door het schuifvenster). Wanneer de buffer van de ontvangende host vol raakt, bevat de volgende bevestiging een 0 in de venstergrootte, om de overdracht te stoppen en de gegevens in de buffer te laten verwerken.
- Congestiecontrole
Betrouwbare transmissieEdit
TCP gebruikt een volgnummer om elke byte data te identificeren. Het volgnummer identificeert de volgorde van de bytes die door elke computer worden verzonden, zodat de gegevens in volgorde kunnen worden gereconstrueerd, ongeacht een eventuele herschikking van pakketten of pakketverlies dat tijdens de transmissie kan optreden. Het volgnummer van de eerste byte wordt door de zender gekozen voor het eerste pakket, dat als SYN wordt gemarkeerd. Dit nummer kan willekeurig zijn, en zou in feite onvoorspelbaar moeten zijn ter verdediging tegen TCP sequence prediction attacks.
Acknowledgements (ACK’s) worden met een volgnummer door de ontvanger van data verstuurd om de zender te vertellen dat data is ontvangen tot de gespecificeerde byte. ACK’s houden niet in dat de gegevens bij de toepassing zijn afgeleverd. Ze geven alleen aan dat het nu de verantwoordelijkheid van de ontvanger is om de gegevens af te leveren.
Betrouwbaarheid wordt bereikt door de verzender die verloren gegevens detecteert en opnieuw uitzendt. TCP gebruikt twee primaire technieken om verlies vast te stellen. Retransmission timeout (afgekort als RTO) en duplicate cumulative acknowledgements (DupAcks).
Dupack-based retransmissionEdit
Als een enkel segment (zeg segment 100) in een stream verloren gaat, dan kan de ontvanger pakketten boven nr. 100 omdat het cumulatieve ACK’s gebruikt. Daarom bevestigt de ontvanger pakket 99 nogmaals bij ontvangst van een ander datapakket. Deze dubbele bevestiging wordt gebruikt als een signaal voor pakketverlies. Dat wil zeggen, als de verzender drie dubbele bevestigingen ontvangt, zendt hij het laatste niet bevestigde pakket opnieuw uit. Een drempel van drie wordt gebruikt omdat het netwerk segmenten kan herschikken waardoor dubbele bevestigingen ontstaan. Het is aangetoond dat deze drempel valse heruitzendingen ten gevolge van herschikking voorkomt. Soms worden selectieve ontvangstbevestigingen (SACK’s) gebruikt om expliciete feedback te geven over de segmenten die zijn ontvangen. Dit verbetert TCP’s vermogen om de juiste segmenten opnieuw uit te zenden aanzienlijk.
Timeout-based retransmissionEdit
Wanneer een verzender een segment uitzendt, initialiseert hij een timer met een conservatieve schatting van de aankomsttijd van de ontvangstbevestiging. Het segment wordt opnieuw verzonden als de timer afloopt, met een nieuwe timeout drempel van tweemaal de vorige waarde, resulterend in exponentieel backoff gedrag. Typisch is de initiële timerwaarde afgevlakte RTT + max ( G , 4 × RTT variatie ) {\displaystyle {{afgevlakte RTT}}+max(G,4 keer {{RTT variatie}})}

, waarbij G {{afgevlakte RTT}}+max(G,4 keer {{RTT-variatie}})} , waarbij G {{afgevlakte RTT}}

de klokkorrelgrootte is. Dit beschermt tegen excessief transmissieverkeer als gevolg van defecte of kwaadwillende actoren, zoals man-in-the-middle denial of service-aanvallers.
FoutdetectieEdit
Volgnummers stellen ontvangers in staat dubbele pakketten te verwijderen en de juiste volgorde van opnieuw geordende pakketten te bepalen. Acknowledgments stellen afzenders in staat te bepalen wanneer verloren pakketten opnieuw moeten worden verzonden.
Om correctheid te verzekeren is een checksum veld opgenomen; zie checksum computation sectie voor details over checksumming. De TCP checksum is naar moderne maatstaven een zwakke controle. Data Link Lagen met hoge bit error rates kunnen extra link error correctie/detectie mogelijkheden nodig hebben. De zwakke controlesom wordt gedeeltelijk gecompenseerd door het gebruikelijke gebruik van een CRC of betere integriteitscontrole op laag 2, onder zowel TCP als IP, zoals wordt gebruikt in PPP of het Ethernet-frame. Dit betekent echter niet dat de 16-bit TCP-controlesom overbodig is: opmerkelijk genoeg komt het vaak voor dat fouten worden geïntroduceerd in pakketten tussen CRC-beveiligde hops, maar de end-to-end 16-bit TCP-controlesom vangt de meeste van deze eenvoudige fouten op. Dit is het end-to-end principe aan het werk.
Flow controlEdit
TCP gebruikt een end-to-end flow control protocol om te voorkomen dat de verzender data te snel verstuurt voor de TCP ontvanger om deze betrouwbaar te ontvangen en te verwerken. Een mechanisme voor flow control is essentieel in een omgeving waar machines met verschillende netwerksnelheden met elkaar communiceren. Als een PC bijvoorbeeld gegevens naar een smartphone stuurt die de ontvangen gegevens langzaam verwerkt, moet de smartphone de gegevensstroom reguleren om niet te worden overweldigd.
TCP maakt gebruik van een sliding window flow control protocol. In elk TCP segment specificeert de ontvanger in het “receive window” veld de hoeveelheid additioneel ontvangen data (in bytes) die hij bereid is te bufferen voor de verbinding. De verzendende host kan slechts tot die hoeveelheid gegevens verzenden voordat hij op een bevestiging en een update van het venster van de ontvangende host moet wachten.

Als een ontvanger een venster met een grootte van 0 aankondigt, stopt de verzender met het verzenden van gegevens en start de persist-timer. De persist-timer wordt gebruikt om TCP te beschermen tegen een impasse die zou kunnen ontstaan als een volgende update van de venstergrootte door de ontvanger verloren gaat, en de verzender geen gegevens meer kan verzenden totdat hij een nieuwe update van de venstergrootte van de ontvanger heeft ontvangen. Als de persist timer afloopt, probeert de TCP-afzender herstel te bereiken door een klein pakket te verzenden, zodat de ontvanger reageert door een nieuwe bevestiging te verzenden met de nieuwe venstergrootte.
Als een ontvanger binnenkomende gegevens in kleine stappen verwerkt, kan hij herhaaldelijk een klein ontvangstvenster aankondigen. Dit wordt het silly window syndrome genoemd, omdat het inefficient is om slechts een paar bytes data in een TCP segment te versturen, gezien de relatief grote overhead van de TCP header.
Congestie controleEdit
Het laatste hoofdaspect van TCP is congestion control. TCP gebruikt een aantal mechanismen om hoge prestaties te bereiken en congestie collaps te voorkomen, waarbij de netwerkprestaties met enkele orden van grootte kunnen dalen. Deze mechanismen controleren de snelheid van de gegevens die het netwerk binnenkomen, en houden de gegevensstroom onder een snelheid die een collaps zou veroorzaken. Ze zorgen ook voor een ongeveer max-min eerlijke verdeling tussen stromen.
Erkeningen voor verzonden data, of het gebrek aan erkenningen, worden door verzenders gebruikt om de netwerk condities tussen de TCP verzender en ontvanger af te leiden. In combinatie met timers kunnen TCP-afzenders en -ontvangers het gedrag van de gegevensstroom wijzigen. Dit wordt meer algemeen aangeduid als congestie controle en/of netwerk congestie vermijding.
Moderne implementaties van TCP bevatten vier met elkaar verweven algoritmen: slow-start, congestie vermijding, fast retransmit, en fast recovery (RFC 5681).
Daarnaast gebruiken verzenders een retransmission timeout (RTO) die is gebaseerd op de geschatte round-trip tijd (of RTT) tussen de verzender en ontvanger, alsmede de variatie in deze round trip tijd. Het gedrag van deze timer wordt gespecificeerd in RFC 6298. Er zijn subtiliteiten in de schatting van RTT. Verzenders moeten bijvoorbeeld voorzichtig zijn met het berekenen van RTT-monsters voor heruitgezonden pakketten; gewoonlijk gebruiken ze het algoritme van Karn of TCP-timestamps (zie RFC 1323). Deze individuele RTT-monsters worden dan gemiddeld over de tijd om een Smoothed Round Trip Time (SRTT) te creëren met behulp van Jacobson’s algoritme. Deze SRTT-waarde wordt uiteindelijk gebruikt als schatting van de rondreistijd.
Het verbeteren van TCP om op betrouwbare wijze om te gaan met verlies, fouten te minimaliseren, congestie te beheersen en snel te zijn in omgevingen met zeer hoge snelheden is een doorlopend onderwerp van onderzoek en ontwikkeling van standaarden. Als gevolg hiervan zijn er een aantal TCP congestie vermijdingsalgoritme variaties.
Maximum segment sizeEdit
De maximum segment size (MSS) is de grootste hoeveelheid data, gespecificeerd in bytes, die TCP bereid is te ontvangen in een enkel segment. Voor de beste prestaties moet de MSS klein genoeg worden ingesteld om IP-fragmentatie te voorkomen, wat kan leiden tot pakketverlies en overmatige heruitzendingen. Om dit te bereiken wordt de MSS gewoonlijk door elke partij aangekondigd met de MSS-optie wanneer de TCP-verbinding tot stand wordt gebracht, waarbij deze wordt afgeleid van de maximale transmissie-eenheid (MTU)-grootte van de datalinklaag van de netwerken waarmee de verzender en de ontvanger rechtstreeks verbonden zijn. Bovendien kunnen TCP-afzenders path MTU discovery gebruiken om de minimale MTU langs het netwerkpad tussen de afzender en de ontvanger af te leiden, en deze gebruiken om de MSS dynamisch aan te passen om IP-fragmentatie binnen het netwerk te voorkomen.
MSS aankondiging wordt ook vaak “MSS onderhandeling” genoemd. Strikt genomen wordt over de MSS niet “onderhandeld” tussen de originator en de ontvanger, omdat dat zou impliceren dat zowel de originator als de ontvanger onderhandelen over en instemmen met één enkele, uniforme MSS die van toepassing is op alle communicatie in beide richtingen van de verbinding. In feite zijn twee volledig onafhankelijke waarden van MSS toegestaan voor de twee datastromen in een TCP-verbinding. Deze situatie kan zich bijvoorbeeld voordoen als een van de apparaten die deelnemen aan een verbinding een extreem beperkte hoeveelheid geheugen heeft gereserveerd (misschien zelfs kleiner dan de totale ontdekte Path MTU) voor het verwerken van inkomende TCP segmenten.
Selectieve bevestigingenEdit
Alleen vertrouwen op het cumulatieve bevestigingsschema dat door het oorspronkelijke TCP-protocol wordt gebruikt, kan leiden tot inefficiënties wanneer pakketten verloren gaan. Bijvoorbeeld, stel dat bytes met volgnummers 1.000 tot 10.999 worden verzonden in 10 verschillende TCP segmenten van gelijke grootte, en het tweede segment (volgnummers 2.000 tot 2.999) gaat verloren tijdens de transmissie. In een zuiver cumulatief bevestigingsprotocol kan de ontvanger alleen een cumulatieve ACK-waarde van 2.000 zenden (het volgnummer dat onmiddellijk volgt op het laatste volgnummer van de ontvangen gegevens) en kan hij niet zeggen dat hij bytes 3.000 tot 10.999 met succes heeft ontvangen. De verzender moet dan mogelijk alle data vanaf volgnummer 2.000 opnieuw versturen.
Om dit probleem op te lossen gebruikt TCP de selectieve bevestigingsoptie (SACK), gedefinieerd in 1996 in RFC 2018, die de ontvanger in staat stelt om discontinue blokken pakketten die correct zijn ontvangen te bevestigen, naast het volgnummer dat direct volgt op het laatste volgnummer van de laatste opeenvolgende ontvangen contigue byte, zoals in de basis TCP bevestiging. De bevestiging kan een aantal SACK blokken specificeren, waarbij elk SACK blok wordt overgebracht door de Left Edge of Block (het eerste volgnummer van het blok) en de Right Edge of Block (het volgnummer dat onmiddellijk volgt op het laatste volgnummer van het blok), waarbij een Blok een aaneengesloten bereik is dat de ontvanger correct heeft ontvangen. In het bovenstaande voorbeeld zou de ontvanger een ACK segment zenden met een cumulatieve ACK waarde van 2.000 en een SACK optie header met volgnummers 3.000 en 11.000. De verzender zou dienovereenkomstig alleen het tweede segment met de volgnummers 2.000 tot 2.999 opnieuw verzenden.
Een TCP verzender kan een aflevering van een segment buiten de volgorde interpreteren als een verloren segment. Als hij dat doet, zendt de TCP-afzender het segment dat voorafgaat aan het pakket dat niet in de juiste volgorde is afgeleverd, opnieuw uit en vertraagt hij de gegevensoverdrachtsnelheid voor die verbinding. De duplicate-SACK optie, een uitbreiding op de SACK optie die in mei 2000 werd gedefinieerd in RFC 2883, lost dit probleem op. De TCP ontvanger stuurt een D-ACK om aan te geven dat er geen segmenten verloren zijn gegaan, en de TCP verzender kan dan de hogere transmissiesnelheid herstellen.
De SACK optie is niet verplicht, en treedt alleen in werking als beide partijen deze ondersteunen. Hierover wordt onderhandeld wanneer een verbinding tot stand wordt gebracht. SACK maakt gebruik van een TCP header optie (zie TCP segment structuur voor details). Het gebruik van SACK is wijdverbreid geworden-alle populaire TCP stacks ondersteunen het. Selective acknowledgment wordt ook gebruikt in Stream Control Transmission Protocol (SCTP).
VensterschaalEdit
Voor een efficiënter gebruik van netwerken met een hoge bandbreedte kan een grotere TCP window size worden gebruikt. Het TCP window size veld regelt de datastroom en de waarde is gelimiteerd tussen 2 en 65.535 bytes.
Omdat het size veld niet kan worden uitgebreid, wordt een schaalfactor gebruikt. De TCP window scale optie, zoals gedefinieerd in RFC 1323, is een optie die wordt gebruikt om de maximale window grootte te vergroten van 65.535 bytes tot 1 gigabyte. Het opschalen naar grotere window groottes is een onderdeel van wat nodig is voor TCP tuning.
De window scale optie wordt alleen gebruikt tijdens de TCP 3-way handshake. De window scale waarde vertegenwoordigt het aantal bits om het 16-bit window size veld naar links te verschuiven. De window scale waarde kan worden ingesteld van 0 (geen verschuiving) tot 14 voor elke richting afzonderlijk. Beide kanten moeten de optie in hun SYN segmenten sturen om window scaling in beide richtingen mogelijk te maken.
Sommige routers en pakket firewalls herschrijven de window scaling factor tijdens een transmissie. Dit zorgt ervoor dat zendende en ontvangende partijen verschillende TCP window groottes aannemen. Het resultaat is niet-stabiel verkeer dat erg traag kan zijn. Het probleem is zichtbaar op sommige sites achter een defecte router.
TCP timestampsEdit
TCP timestamps, gedefinieerd in RFC 1323 in 1992, kunnen TCP helpen te bepalen in welke volgorde pakketten zijn verzonden.TCP timestamps zijn normaal gesproken niet uitgelijnd met de systeemklok en beginnen bij een willekeurige waarde. Veel besturingssystemen verhogen de timestamp voor elke verstreken milliseconde; de RFC stelt echter alleen dat de ticks proportioneel moeten zijn.
Er zijn twee timestamp-velden:
een 4-byte timestamp-waarde van de zender (mijn timestamp) een 4-byte echo reply timestamp-waarde (de meest recente timestamp die van jou is ontvangen).
TCP timestamps worden gebruikt in een algoritme dat bekend staat als Protection Against Wrapped Sequence numbers, of PAWS (zie RFC 1323 voor details). PAWS wordt gebruikt wanneer het ontvangstvenster de grens van de sequentienummer wraparound overschrijdt. In het geval dat een pakket mogelijk opnieuw verzonden werd, beantwoordt het de vraag: “Is dit sequentienummer in de eerste 4 GB of de tweede?” En het tijdstempel wordt gebruikt om de gelijkstand te doorbreken.
Ook, het Eifel detectie algoritme (RFC 3522) gebruikt TCP tijdstempels om te bepalen of heruitzendingen plaatsvinden omdat pakketten verloren zijn gegaan of gewoon uit volgorde.
Recente statistieken laten zien dat het niveau van Timestamp adoptie is gestagneerd, op ~40%, als gevolg van Windows server het laten vallen van ondersteuning sinds Windows Server 2008.
TCP tijdstempels zijn standaard ingeschakeld In Linux kernel.., en standaard uitgeschakeld in Windows Server 2008, 2012 en 2016.
Out-of-band dataEdit
Het is mogelijk om de stream in de wachtrij te onderbreken of af te breken in plaats van te wachten tot de stream is afgelopen. Dit wordt gedaan door de data als urgent te specificeren. Dit vertelt het ontvangende programma om het onmiddellijk te verwerken, samen met de rest van de urgente gegevens. Als het klaar is, informeert TCP de applicatie en gaat terug naar de stream-wachtrij. Een voorbeeld is wanneer TCP wordt gebruikt voor een remote login sessie, de gebruiker kan een toetsenbord sequentie sturen die het programma aan de andere kant onderbreekt of afbreekt. Deze signalen zijn meestal nodig wanneer een programma op de machine op afstand niet correct werkt. De signalen moeten worden verzonden zonder te wachten tot het programma klaar is met zijn huidige overdracht.
TCP out-of-band data is niet ontworpen voor het moderne Internet. De urgente pointer verandert alleen de verwerking op de remote host en versnelt geen verwerking op het netwerk zelf. Wanneer het bij de remote host aankomt zijn er twee licht verschillende interpretaties van het protocol, wat betekent dat alleen enkele bytes van OOB gegevens betrouwbaar zijn. Dit is ervan uitgaande dat het überhaupt betrouwbaar is, omdat het een van de minst gebruikte protocol-elementen is en meestal slecht is geïmplementeerd.
Gegevensaflevering forcerenEdit
Normaal wacht TCP 200 ms op het verzenden van een volledig pakket gegevens (Nagle’s Algoritme probeert kleine berichten te groeperen in een enkel pakket). Dit wachten creëert kleine, maar potentieel ernstige vertragingen als het constant herhaald wordt tijdens een bestandsoverdracht. Bijvoorbeeld, een typisch send blok zou 4 KB zijn, een typische MSS is 1460, dus 2 pakketten gaan uit op een 10 Mbit/s ethernet die elk ~1.2 ms duren, gevolgd door een derde die de resterende 1176 draagt na een pauze van 197 ms omdat TCP wacht op een volle buffer.
In het geval van telnet, wordt elke toetsaanslag van de gebruiker teruggeëchood door de server voordat de gebruiker het op het scherm kan zien. Deze vertraging zou erg vervelend worden.
Het instellen van de socket optie TCP_NODELAY heft de standaard 200 ms zendvertraging op. Applicatieprogramma’s gebruiken deze socket-optie om te forceren dat uitvoer wordt verzonden na het schrijven van een karakter of een regel karakters.
De RFC definieert de PSH push bit als “een bericht aan de ontvangende TCP stack om deze gegevens onmiddellijk door te sturen naar de ontvangende applicatie”. Er is geen manier om dit aan te geven of te controleren in gebruikersruimte met Berkeley sockets en het wordt alleen gecontroleerd door de protocol stack.