Durchführen des Hypothesentests
- Nullhypothese: H0: ρ = 0
- Alternative Hypothese: Ha: ρ ≠ 0
- Nullhypothese H0: Der Korrelationskoeffizient der Population IST NICHT signifikant von Null verschieden. Es gibt KEINE signifikante lineare Beziehung (Korrelation) zwischen X1 und X2 in der Population.
- Alternativhypothese Ha: Der Populationskorrelationskoeffizient ist signifikant verschieden von Null. Es besteht ein signifikanter linearer Zusammenhang (Korrelation) zwischen X1 und X2 in der Grundgesamtheit.
Eine Schlussfolgerung ziehenEs gibt zwei Methoden, um die Entscheidung bezüglich der Hypothese zu treffen. Die Teststatistik zum Testen der Hypothese ist:
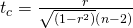
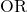
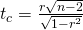
Die zweite Formel ist eine äquivalente Form der Teststatistik, n ist der Stichprobenumfang und die Freiheitsgrade sind n-2. Dies ist eine t-Statistik und funktioniert genauso wie andere t-Tests. Berechnen Sie den t-Wert und vergleichen Sie diesen mit dem kritischen Wert aus der t-Tabelle bei den entsprechenden Freiheitsgraden und dem gewünschten Vertrauensniveau. Wenn der berechnete Wert im Schwanzbereich liegt, dann kann die Nullhypothese, dass es keinen linearen Zusammenhang zwischen diesen beiden unabhängigen Zufallsvariablen gibt, nicht akzeptiert werden. Wenn der berechnete t-Wert NICHT im Tailing liegt, dann kann die Nullhypothese, dass es keinen linearen Zusammenhang zwischen den beiden Variablen gibt, nicht zurückgewiesen werden.
Eine schnelle Kurzform, um Korrelationen zu testen, ist die Beziehung zwischen der Stichprobengröße und der Korrelation. Wenn:
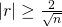
dann bedeutet dies, dass die Korrelation zwischen den beiden Variablen zeigt, dass ein linearer Zusammenhang besteht und statistisch signifikant ist, ungefähr auf dem Signifikanzniveau 0,05. Wie die Formel andeutet, gibt es eine umgekehrte Beziehung zwischen der Stichprobengröße und der erforderlichen Korrelation für die Signifikanz einer linearen Beziehung. Bei nur 10 Beobachtungen beträgt die erforderliche Korrelation für die Signifikanz 0,6325, bei 30 Beobachtungen sinkt die erforderliche Korrelation für die Signifikanz auf 0,3651 und bei 100 Beobachtungen beträgt das erforderliche Niveau nur noch 0,2000.
Korrelationen können bei der Visualisierung der Daten hilfreich sein, sind aber nicht geeignet, um eine Beziehung zwischen zwei Variablen zu „erklären“. Vielleicht wird keine einzelne Statistik mehr missbraucht als der Korrelationskoeffizient. Die Nennung von Korrelationen zwischen Gesundheitszuständen und allem, vom Wohnort bis zur Augenfarbe, hat den Effekt, dass eine Ursache-Wirkungs-Beziehung impliziert wird. Dies kann mit einem Korrelationskoeffizienten einfach nicht erreicht werden. Der Korrelationskoeffizient ist natürlich unschuldig an dieser Fehlinterpretation. Es ist die Pflicht des Analytikers, eine Statistik zu verwenden, die darauf ausgelegt ist, auf kausale Zusammenhänge zu testen, und nur diese Ergebnisse zu berichten, wenn er eine solche Behauptung aufstellen will. Das Problem ist, dass es schwierig ist, diesen strengeren Test zu bestehen, so dass faule und/oder skrupellose „Forscher“ auf Korrelationen zurückgreifen, wenn sie ihren Fall nicht legitimieren können.
Bestimmen Sie einen t-Test für einen Regressionskoeffizienten und geben Sie ein eindeutiges Beispiel für seine Anwendung.
Einen t-Test erhält man, indem man einen Regressionskoeffizienten durch seinen Standardfehler dividiert und dann das Ergebnis mit den kritischen Werten für Students‘ t mit Fehler df vergleicht. Er liefert einen Test der Behauptung, dass 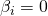 , wenn alle anderen Variablen in das betreffende Regressionsmodell aufgenommen wurden.
, wenn alle anderen Variablen in das betreffende Regressionsmodell aufgenommen wurden.
Beispiel:
Angenommen, es wird vermutet, dass 4 Variablen eine Antwort beeinflussen. Angenommen, die Ergebnisse der Anpassung  umfassen:
umfassen:
| Variable | Regressionskoeffizient | Standardfehler des regulären Koeffizienten |
| .5 | 1 | -3 |
| .4 | 2 | +2 |
| .02 | 3 | +1 |
| .6 | 4 | -.5 |
Der für die Variablen 1, 2 und 3 berechnete Wert würde im Absolutwert 5 oder größer sein, während der Wert für Variable 4 kleiner als 1 wäre. Für die meisten Signifikanzniveaus würde die Hypothese 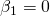 abgelehnt werden. Beachten Sie aber, dass dies für den Fall gilt, wenn
abgelehnt werden. Beachten Sie aber, dass dies für den Fall gilt, wenn 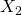
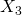 und
und 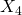 in die Regression aufgenommen wurden. Für die meisten Signifikanzniveaus würde die Hypothese
in die Regression aufgenommen wurden. Für die meisten Signifikanzniveaus würde die Hypothese 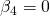 für den Fall, dass
für den Fall, dass 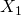 und in der Regression enthalten sind, fortgesetzt (beibehalten) werden. Oft wird dieses Ergebnismuster dazu führen, dass eine weitere Regression berechnet wird, die nur und enthält, und die t-Ratios untersucht werden, die für diesen Fall erzeugt wurden.
und in der Regression enthalten sind, fortgesetzt (beibehalten) werden. Oft wird dieses Ergebnismuster dazu führen, dass eine weitere Regression berechnet wird, die nur und enthält, und die t-Ratios untersucht werden, die für diesen Fall erzeugt wurden.
Die Korrelation zwischen den Ergebnissen eines Neurotizismus-Tests und den Ergebnissen eines Angst-Tests ist hoch und positiv; daher
- Angst verursacht Neurotizismus
- Diejenigen, die bei einem Test niedrig abschneiden, neigen dazu, bei dem anderen hoch abzuschneiden.
- Diejenigen, die bei einem Test niedrig abschneiden, neigen dazu, bei dem anderen niedrig abzuschneiden.
- Keine Vorhersage von einem Test zum anderen kann sinnvoll gemacht werden.
C. Diejenigen, die bei einem Test niedrig abschneiden, neigen dazu, bei dem anderen niedrig abzuschneiden.