Réaliser le test d’hypothèse
- Hypothèse nulle : H0 : ρ = 0
- Hypothèse alternative : Ha : ρ ≠ 0
- Hypothèse nulle H0 : Le coefficient de corrélation de population N’EST PAS significativement différent de zéro. Il N’Y A PAS de relation linéaire significative (corrélation) entre X1 et X2 dans la population.
- Hypothèse alternative Ha : Le coefficient de corrélation de la population est significativement différent de zéro. Il existe une relation linéaire significative (corrélation) entre X1 et X2 dans la population.
Tirer une conclusionIl existe deux méthodes pour prendre la décision concernant l’hypothèse. La statistique de test pour tester cette hypothèse est :
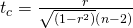
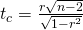
Où la deuxième formule est une forme équivalente de la statistique de test, n est la taille de l’échantillon et les degrés de liberté sont n-2. Il s’agit d’une statistique t et elle fonctionne de la même manière que les autres tests t. Calculez la valeur t et comparez-la à la valeur critique du tableau t pour les degrés de liberté appropriés et le niveau de confiance que vous souhaitez maintenir. Si la valeur calculée se situe dans la queue, vous ne pouvez pas accepter l’hypothèse nulle selon laquelle il n’existe pas de relation linéaire entre ces deux variables aléatoires indépendantes. Si la valeur t calculée n’est PAS dans la queue alors ne peut pas rejeter l’hypothèse nulle qu’il n’y a pas de relation linéaire entre ces deux variables.
Une façon abrégée rapide de tester les corrélations est la relation entre la taille de l’échantillon et la corrélation. Si:
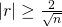
alors cela implique que la corrélation entre les deux variables démontre qu’il existe une relation linéaire et qu’elle est statistiquement significative à environ le niveau de signification de 0,05. Comme l’indique la formule, il existe une relation inverse entre la taille de l’échantillon et la corrélation requise pour la signification d’une relation linéaire. Avec seulement 10 observations, la corrélation requise pour la signification est de 0,6325, pour 30 observations, la corrélation requise pour la signification diminue à 0,3651 et à 100 observations, le niveau requis n’est que de 0,2000.
Les corrélations peuvent être utiles pour visualiser les données, mais ne sont pas utilisées de manière appropriée pour « expliquer » une relation entre deux variables. Aucune statistique n’est peut-être plus mal utilisée que le coefficient de corrélation. Citer des corrélations entre des conditions de santé et tout ce qui va du lieu de résidence à la couleur des yeux a pour effet d’impliquer une relation de cause à effet. Or, le coefficient de corrélation ne permet pas de le faire. Le coefficient de corrélation est, bien entendu, innocent de cette mauvaise interprétation. Il est du devoir de l’analyste d’utiliser une statistique conçue pour tester les relations de cause à effet et de rapporter uniquement ces résultats s’il a l’intention de faire une telle affirmation. Le problème est que passer ce test plus rigoureux est difficile, de sorte que les « chercheurs » paresseux et/ou peu scrupuleux se rabattent sur les corrélations lorsqu’ils ne peuvent pas faire valoir leurs arguments de manière légitime.
Définissez un test t d’un coefficient de régression, et donnez un exemple unique de son utilisation.
Définition :
Un test t est obtenu en divisant un coefficient de régression par son erreur standard, puis en comparant le résultat aux valeurs critiques du t de Students avec erreur df. Il permet de tester l’affirmation selon laquelle 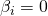 lorsque toutes les autres variables ont été incluses dans le modèle de régression pertinent.
lorsque toutes les autres variables ont été incluses dans le modèle de régression pertinent.
Exemple :
Supposons que l’on soupçonne 4 variables d’influencer une certaine réponse. Supposons que les résultats de l’ajustement  comprennent :
comprennent :
| Variable | Coefficient de régression | Erreur standard du coefficient régulier | .5 | 1 | -3 |
| .4 | 2 | +2 | |
| .02 | 3 | +1 | |
| .6 | 4 | -.5 |
t calculé pour les variables 1, 2 et 3 serait égal ou supérieur à 5 en valeur absolue tandis que celui de la variable 4 serait inférieur à 1. Pour la plupart des niveaux de signification, l’hypothèse 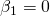 serait rejetée. Mais, remarquez que c’est pour le cas où
serait rejetée. Mais, remarquez que c’est pour le cas où 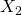
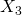 , et
, et 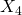 ont été inclus dans la régression. Pour la plupart des niveaux de signification, l’hypothèse
ont été inclus dans la régression. Pour la plupart des niveaux de signification, l’hypothèse 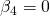 serait poursuivie (retenue) pour le cas où
serait poursuivie (retenue) pour le cas où 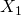 , et sont dans la régression. Souvent, ce modèle de résultats entraînera le calcul d’une autre régression impliquant uniquement , et l’examen des rapports t produits pour ce cas.
, et sont dans la régression. Souvent, ce modèle de résultats entraînera le calcul d’une autre régression impliquant uniquement , et l’examen des rapports t produits pour ce cas.
La corrélation entre les scores à un test de névrosisme et les scores à un test d’anxiété est élevée et positive ; par conséquent
- l’anxiété entraîne le névrosisme
- ceux qui obtiennent un score faible à un test ont tendance à obtenir un score élevé à l’autre.
- ceux qui obtiennent un score faible à un test ont tendance à obtenir un score faible à l’autre.
- aucune prédiction d’un test à l’autre ne peut être faite de manière significative.
c. ceux qui obtiennent un score faible à un test ont tendance à obtenir un score faible à l’autre.