Si has leído mi introducción a los formatos de archivo de Hadoop/Spark, serás consciente de que hay múltiples formas de almacenar datos en HDFS, S3 o el almacenamiento Blob, y cada uno de estos tipos de archivo tiene diferentes propiedades que los hacen buenos (o malos) en diferentes cosas.
Aunque este artículo no es una profundización técnica, voy a darte el resumen de por qué (y cómo) deberías usar Parquet sobre otro formato popular, Avro.
¿Qué es Parquet?
A un alto nivel, parquet es un formato de archivo para almacenar datos estructurados. Por ejemplo, puedes usar parquet para almacenar un montón de registros que se parecen a esto:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Podrías, de hecho, almacenar estos datos en casi cualquier formato de archivo, una forma amigable para el lector de almacenar estos datos es en un archivo CSV o TSV. A continuación se muestra el aspecto de algunos datos de este esquema en un formato CSV:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, En un archivo plano JSON, almacenaríamos cada fila como un objeto JSON:
En cambio, aquí hay una captura de pantalla de los mismos datos en un formato de archivo columnar ilustrativo que llamo Columnar CSV (CCSV):
¿Confundido sobre los formatos de archivo columnar? Lea mi introducción a los formatos de archivo columnar antes de seguir adelante
Totalmente diferente, ¿verdad? Parquet va un paso más allá: es un formato basado en binarios, no en texto. No te preocupes, hay un montón de herramientas que puedes utilizar para inspeccionar y leer los archivos de Parquet e incluso exportar los resultados a un buen y viejo JSON. Por ejemplo, Parquet Tools
Parquet se preocupa por su esquema
Una limitación de los datos CSV/TSV es que no se sabe cuál es el esquema exacto que se supone que es, o el tipo deseado de cada campo.
Usando nuestro ejemplo anterior, sin el esquema, ¿deberían los valores ‘True’ ser lanzados a booleano? ¿Cómo podemos estar seguros sin conocer el esquema de antemano?
JSON mejora a CSV ya que cada fila proporciona alguna indicación del esquema, pero sin una fila de cabecera especial, no hay manera de derivar un esquema para cada registro en el archivo, y no siempre está claro qué tipo un valor ‘null’ debe ser interpretado como.
Avro y Parquet por otro lado entienden el esquema de los datos que almacenan. Cuando se escribe un archivo en estos formatos, es necesario especificar su esquema. Cuando lees el archivo de vuelta, te dice el esquema de los datos almacenados dentro. Esto es muy útil para un marco de trabajo como Spark, que puede utilizar esta información para darle un marco de datos completamente formado con el mínimo esfuerzo.
Hablemos de Parquet vs Avro
En su cara, Avro y Parquet son similares, ambos escriben el esquema de sus datos adjuntos en una cabecera de archivo y manejan bien la deriva del esquema (añadiendo/quitando columnas). Son tan similares en este aspecto que Parquet incluso soporta de forma nativa los esquemas de Avro, por lo que puede migrar sus pipelines de Avro al almacenamiento de Parquet en un apuro.
La gran diferencia en los dos formatos es que Avro almacena los datos POR FILA, y Parquet almacena los datos POR COLUMNA..
- ¡Oh hai! No te olvides de mi guía de formatos de archivo columnar si quieres aprender más sobre ellos
Beneficios de Parquet sobre Avro
Para recapitular sobre mi guía de formatos de archivo columnar, la ventaja a Parquet (y los formatos de archivo columnar en general) son principalmente dos:
- Costes de almacenamiento reducidos (normalmente) frente a Avro
- Mejora de 10 a 100 veces en la lectura de datos cuando sólo se necesitan unas pocas columnas
- Cuando se leen registros enteros a la vez, Avro gana en rendimiento.
- El tiempo de escritura aumenta drásticamente al escribir archivos de Parquet frente a archivos de Avro
-
Depuración – ¿hizo su pipeline lo correcto? Añadió/eliminó/modificó los registros correctos? Con el parquet puede capturar información rápida y sencilla (como todos los valores únicos de una columna) en unos segundos sin necesidad de escanear todo el archivo.
-
Extracción rápida de métricas – ¿quiere registrar en su sistema de monitorización un recuento de un subconjunto de registros de su conjunto de datos? Anteriormente capturaba esta información ejecutando un pipeline de seguimiento, pero con Parquet es una consulta muy rápida a través de Hive o Spark SQL.
-
Menos redundancia – ¿Necesita un conjunto de datos similar para dos pipelines diferentes? En lugar de construir un conjunto de datos distinto para cada uno, Parquet le permite simplemente consultar dinámicamente un conjunto de datos más grande y completo sin las penalidades de escanear un archivo entero.
-
Analítica – Ok, hice trampa y lo puse de todos modos. Sí, Parquet es INCREÍBLE para la analítica, cualquiera que ejecute consultas SQL le agradecerá que le ahorre horas al día frente a un prompt de SQL cuando sus consultas se ejecuten hasta 1000 veces más rápido.
No puedo exagerar el beneficio de una mejora de 100 veces en el rendimiento de los registros. Proporciona una mejora realmente masiva y fundamental para los pipelines de procesamiento de datos que es muy difícil de pasar por alto.
Aquí hay una ilustración de este beneficio de un caso de estudio de Cloudera allá por 2016 en un pequeño conjunto de datos de menos de 200GB.
Cuando simplemente se cuentan filas, Parquet supera a Avro, gracias a los metadatos que Parquet almacena en la cabecera de los grupos de filas.
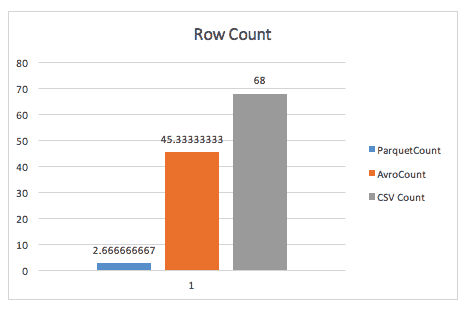
Cuando se ejecuta una consulta group-by, parquet sigue siendo casi 2 veces más rápido (aunque no estoy seguro de la consulta exacta utilizada aquí).
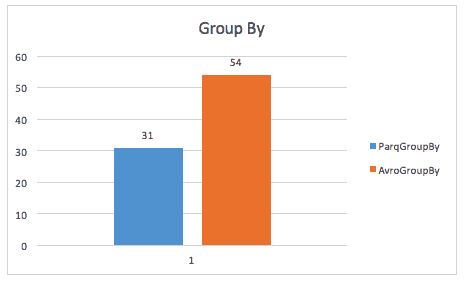
El mismo caso de estudio también encuentra mejoras en el espacio de almacenamiento, e incluso en los escaneos de tablas completas, probablemente debido a que Spark tiene que escanear un tamaño de datos más pequeño.
Beneficios de Avro sobre Parquet
He oído a algunas personas argumentar a favor de Avro frente a Parquet. Estos argumentos se basan normalmente en dos puntos:
Si bien estos dos puntos son válidos, son notas menores frente a las mejoras de rendimiento de Parquet en general. Hay muchos puntos de referencia disponibles en línea para Avro vs Parquet, pero permítanme dibujar un gráfico de una presentación de Hortonworks 2016 que compara el rendimiento del formato de archivo en varias situaciones.
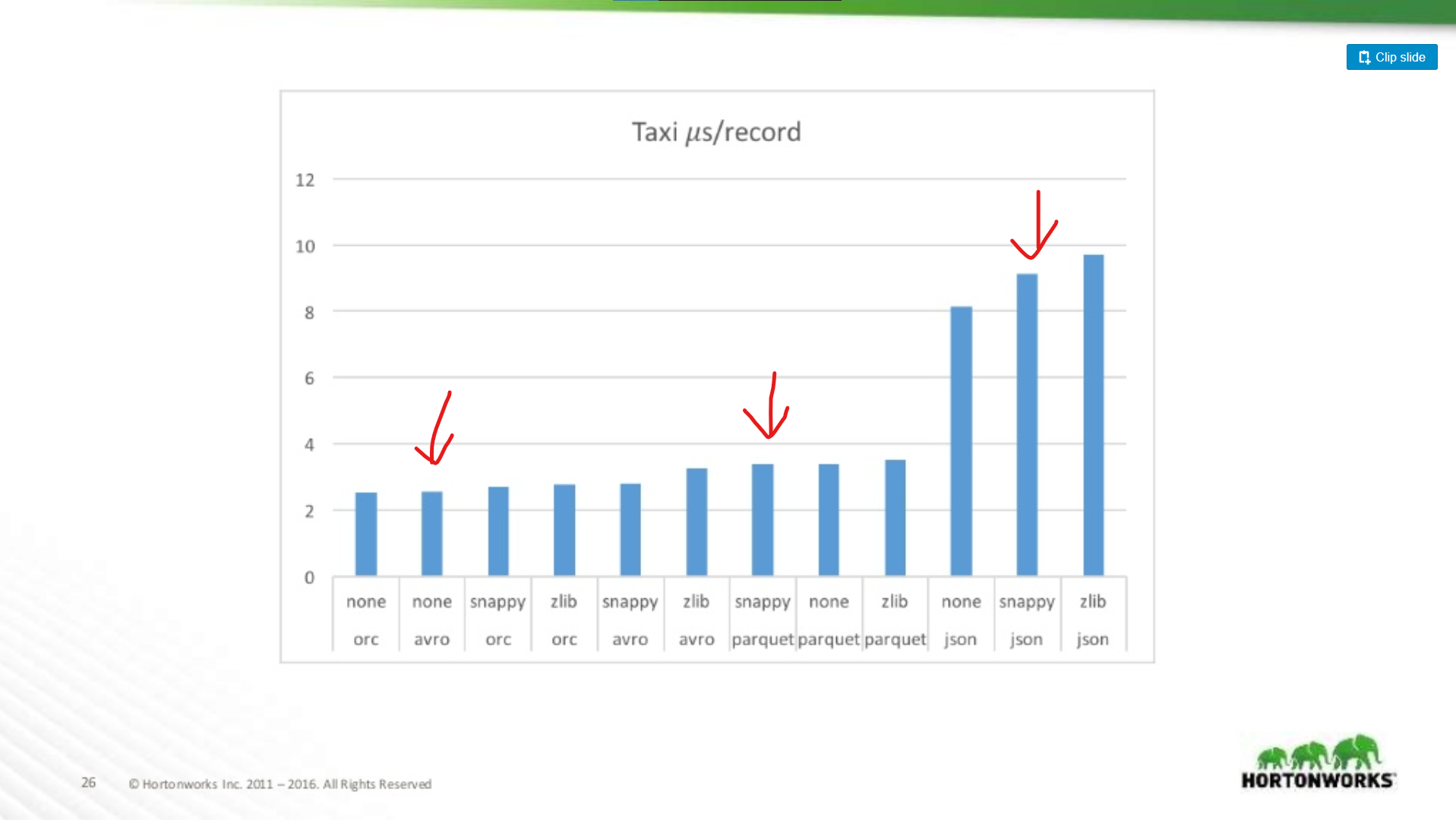
¿Cuánto peor es Parquet para las exploraciones de registros enteros?
Aquí comparamos el rendimiento de Avro, JSON y Parquet en un conjunto de datos de Taxi que contiene ~18 columnas. En esta prueba estaban leyendo registros enteros como parte de un trabajo MapReduce, este tipo de carga de trabajo es el peor caso de rendimiento de Parquet, y aquí casi coincide con el rendimiento de lectura de Avro.
En el otro extremo del espectro se ejecutaron contra un volcado de datos de Github que tenía un extremo de 704 columnas de datos por registro. Aquí vemos una ventaja más significativa para Avro:
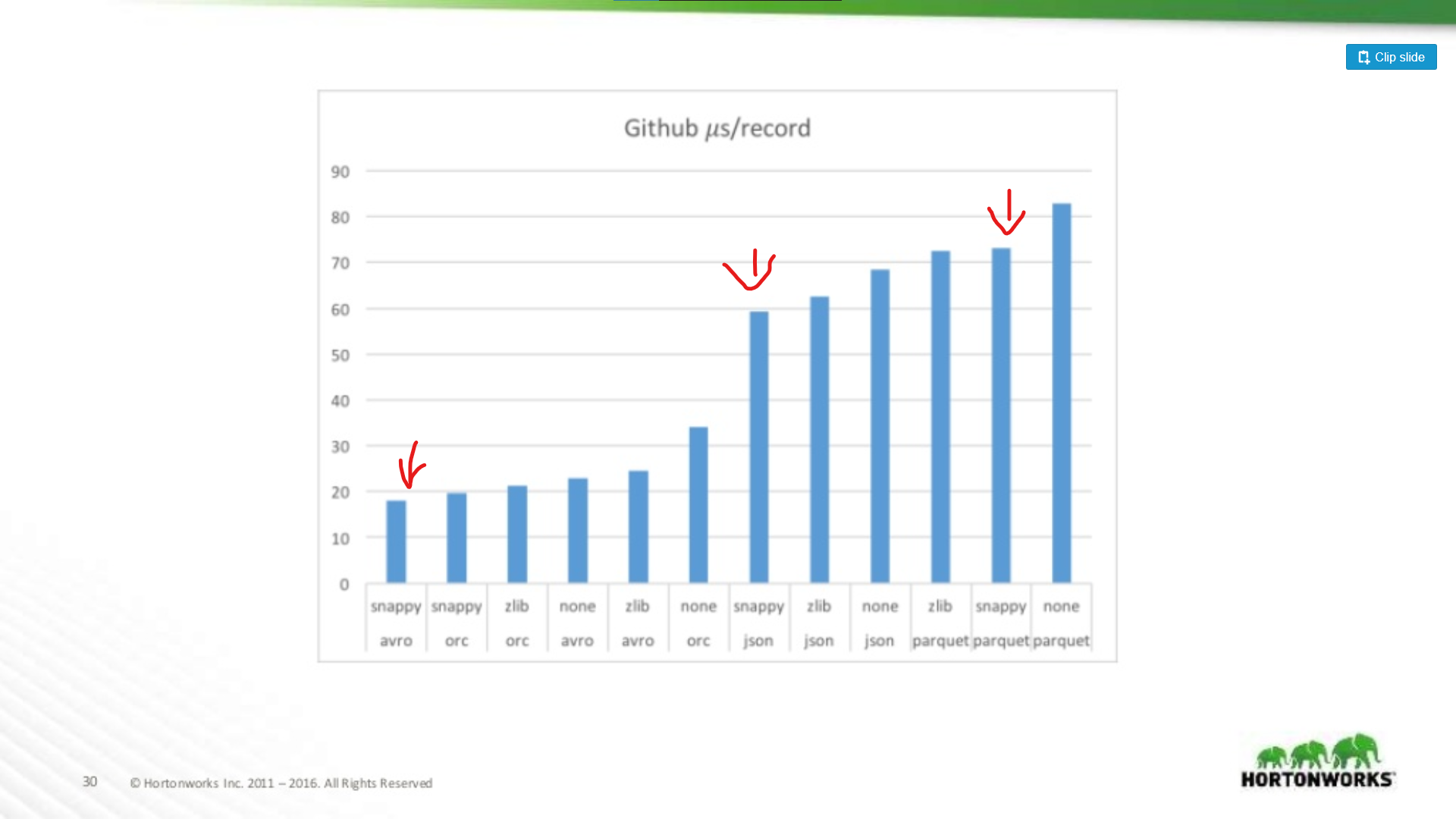
Así que cuanto más amplio sea tu conjunto de datos, peor será Parquet para escanear registros enteros (lo cual tiene sentido). Este es un ejemplo extremo, la mayoría de los conjuntos de datos no tienen 700 columnas de ancho, para cualquier cosa razonable (< 100) el rendimiento de lectura de Parquet se acerca lo suficiente a Avro como para no importar.
Inversiones en Parquet
Dicho esto, mitigar los aspectos negativos de Parquet es un foco de inversión importante. Por ejemplo, vea este artículo de Cloudera sobre el uso de la vectorización para limitar la sobrecarga de la CPU de Parquet.
Aún veo a algunas personas argumentar a favor de Avro sobre Parquet incluso cuando las lecturas de registros completos son más lentas en Avro. ¡Mi opinión es que el almacenamiento es barato! Las CPUs no lo son. Ese mismo artículo muestra un beneficio de rendimiento de más de 200 veces cuando se lee una sola columna del archivo. Eso es realmente significativo, y a medida que su conjunto de datos crezca ahorrará una cantidad significativa de recursos de computación.
Parquet es probablemente la opción correcta de cualquier manera
Entonces, si un conjunto de datos es sólo para MapReduce, ¿debe ir en Avro? No. Es tremendamente útil poder «mirar» dentro de un conjunto de datos y encontrar información rápida sobre su contenido, además, muchos frameworks de MapReduce están añadiendo predicate-pushdown a su soporte de parquet. Parquet no es sólo para Analytics!
Incluso ignorando el tiempo de ejecución de sus trabajos de producción, permítanme esbozar algunas de mis formas favoritas de utilizar Parquet fuera de las cargas de trabajo de análisis:
Validación de datos – ¿necesita hacer algunos recuentos aproximados para verificar que sus datos están completos? Estas comprobaciones pueden ejecutarse en unos segundos con Parquet, incluso con un conjunto de datos de 1TB.
Mi opinión: sólo usa Parquet
Aunque creo que hay casos de uso para Avro sobre Parquet, esos casos de uso se están desvaneciendo.
- Las herramientas de la industria se están uniendo alrededor de Parquet como un formato de almacenamiento de datos estándar. Ver para Amazon Web Services por ejemplo. Te darán un volcado de datos de uso en Parquet (o CSV), y su producto EMR proporciona optimizaciones de escritura especiales para Parquet. Lo mismo no es cierto de Avro.
- Frameworks como MapReduce están dando un paso a un lado en favor de frameworks más dinámicos, como Spark, estos frameworks favorecen un estilo de programación ‘dataframe’ donde sólo procesas las columnas que necesitas, e ignoras el resto. Esto es genial para Parquet.
- Parquet es simplemente más flexible. Aunque no siempre es necesario realizar una consulta dispersa de un conjunto de datos, poder hacerlo es muy útil en una serie de situaciones. Esto no se puede hacer con Avro, CSV o JSON.