
Krasimir Tsonev es un codificador con más de diez años de experiencia en desarrollo web. Autor de dos libros sobre Node.js. Trabaja como desarrollador front-end senior para …More aboutKrasimir↬
- 20 min read
- UI,Apps,JavaScript
- Saved for offline reading
- Share on Twitter, LinkedIn


Ya estamos en 2018, y un sinfín de desarrolladores front-end siguen protagonizando una batalla contra la complejidad y el inmovilismo. Mes tras mes, han buscado el santo grial: una arquitectura de aplicación libre de errores que les ayude a entregar rápidamente y con alta calidad. Yo soy uno de esos desarrolladores, y he encontrado algo interesante que puede ayudar.
Hemos dado un buen paso adelante con herramientas como React y Redux. Sin embargo, no son suficientes por sí solas en aplicaciones a gran escala. Este artículo te introducirá el concepto de máquinas de estado en el contexto del desarrollo front-end. Probablemente ya hayas construido varias de ellas sin darte cuenta.
Una introducción a las máquinas de estado
Una máquina de estado es un modelo matemático de computación. Es un concepto abstracto por el que la máquina puede tener diferentes estados, pero en un momento dado sólo cumple uno de ellos. Hay diferentes tipos de máquinas de estado. La más famosa, creo, es la máquina de Turing. Es una máquina de estados infinitos, lo que significa que puede tener un número incontable de estados. La máquina de Turing no encaja bien en el desarrollo actual de la interfaz de usuario porque en la mayoría de los casos tenemos un número finito de estados. Por eso tienen más sentido las máquinas de estado finito, como la de Mealy y la de Moore.
La diferencia entre ellas es que la máquina de Moore cambia su estado basándose sólo en su estado anterior. Por desgracia, tenemos muchos factores externos, como las interacciones de los usuarios y los procesos de red, lo que significa que la máquina de Moore tampoco nos sirve. Lo que buscamos es la máquina de Mealy. Tiene un estado inicial y luego transita a nuevos estados en función de la entrada y de su estado actual.
Una de las formas más sencillas de ilustrar cómo funciona una máquina de estados es observar un torniquete. Tiene un número finito de estados: bloqueado y desbloqueado. Aquí tenemos un sencillo gráfico que nos muestra estos estados, con sus posibles entradas y transiciones.

El estado inicial del torniquete es bloqueado. No importa cuántas veces lo empujemos, se mantiene en ese estado de bloqueo. Sin embargo, si le pasamos una moneda, entonces pasa al estado de desbloqueo. Otra moneda en este punto no haría nada; seguiría en el estado de desbloqueo. Un empujón desde el otro lado funcionaría, y podríamos pasar. Esta acción también transiciona la máquina al estado inicial bloqueado.
Si quisiéramos implementar una única función que controlara el torniquete, probablemente acabaríamos con dos argumentos: el estado actual y una acción. Y si usas Redux, esto probablemente te suene. Es similar a la conocida función reducer, en la que recibimos el estado actual, y basándonos en el payload de la acción, decidimos cuál será el siguiente estado. El reductor es la transición en el contexto de las máquinas de estado. De hecho, cualquier aplicación que tenga un estado que podamos cambiar de alguna manera puede llamarse máquina de estado. Es sólo que estamos implementando todo manualmente una y otra vez.
¿Cómo es mejor una máquina de estado?
En el trabajo, usamos Redux, y estoy bastante contento con él. Sin embargo, he empezado a ver patrones que no me gustan. Con «no me gustan» no quiero decir que no funcionen. Es más bien que añaden complejidad y me obligan a escribir más código. Tuve que emprender un proyecto paralelo en el que tenía espacio para experimentar, y decidí repensar nuestras prácticas de desarrollo de React y Redux. Empecé a tomar notas sobre las cosas que me preocupaban, y me di cuenta de que una abstracción de máquina de estado realmente resolvería algunos de estos problemas. Vamos a lanzarnos a ver cómo implementar una máquina de estados en JavaScript.
Atacaremos un problema sencillo. Queremos obtener datos de una API de back-end y mostrarlos al usuario. El primer paso es aprender a pensar en estados, en lugar de transiciones. Antes de entrar en las máquinas de estado, mi flujo de trabajo para la construcción de una función de este tipo solía ser algo como esto:
- Mostramos un botón de obtención de datos.
- El usuario hace clic en el botón de obtención de datos.
- Descarga la solicitud al back-end.
- Recupera los datos y los analiza.
- Muéstraselos al usuario.
- O, si hay un error, mostrar el mensaje de error y mostrar el botón fetch-data para que podamos lanzar el proceso de nuevo.

Estamos pensando de forma lineal y, básicamente, tratando de cubrir todas las direcciones posibles hacia el resultado final. Un paso lleva a otro, y rápidamente empezaríamos a ramificar nuestro código. Qué pasa con problemas como que el usuario haga doble clic en el botón, o que el usuario haga clic en el botón mientras esperamos la respuesta del back-end, o que la petición tenga éxito pero los datos estén corruptos. En estos casos, probablemente tendríamos varias banderas que nos muestran lo que ha pasado. Tener banderas significa más cláusulas if y, en aplicaciones más complejas, más conflictos.

Esto es porque estamos pensando en transiciones. Nos centramos en cómo se producen estas transiciones y en qué orden. En cambio, centrarse en los distintos estados de la aplicación sería mucho más sencillo. ¿Cuántos estados tenemos y cuáles son sus posibles entradas? Usando el mismo ejemplo:
- idle
En este estado, mostramos el botón fetch-data, nos sentamos y esperamos. La acción posible es:- clic
Cuando el usuario hace clic en el botón, estamos disparando la solicitud al back end y luego la transición de la máquina a un estado «fetching».
- clic
- fetching
La solicitud está en vuelo, y nos sentamos y esperamos. Las acciones son:- éxito
Los datos llegan con éxito y no se corrompen. Usamos los datos de alguna manera y hacemos una transición de vuelta al estado «inactivo». - Fallo
Si hay un error mientras se hace la solicitud o se analizan los datos, hacemos una transición a un estado «error».
- éxito
- Error
Mostramos un mensaje de error y mostramos el botón de obtención de datos. Este estado acepta una acción:- reintentar
Cuando el usuario hace clic en el botón de reintentar, disparamos la solicitud de nuevo y hacemos la transición de la máquina al estado «fetch».
- reintentar
Hemos descrito más o menos los mismos procesos, pero con estados y entradas.
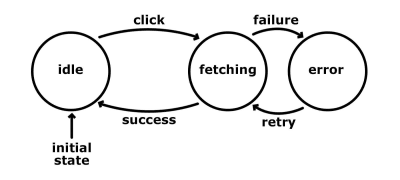
Esto simplifica la lógica y la hace más predecible. También resuelve algunos de los problemas mencionados anteriormente. Observe que, mientras estamos en el estado de «búsqueda», no estamos aceptando ningún clic. Por lo tanto, incluso si el usuario hace clic en el botón, no pasará nada porque la máquina no está configurada para responder a esa acción mientras está en ese estado. Este enfoque elimina automáticamente la ramificación impredecible de nuestra lógica de código. Esto significa que tendremos menos código que cubrir durante las pruebas. Además, algunos tipos de pruebas, como las de integración, pueden automatizarse. Piensa que si tuviéramos una idea muy clara de lo que hace nuestra aplicación, podríamos crear un script que repasara los estados y transiciones definidos y que generara aserciones. Estas aserciones podrían demostrar que hemos llegado a todos los estados posibles o que hemos cubierto un determinado trayecto.
De hecho, escribir todos los estados posibles es más fácil que escribir todas las transiciones posibles porque sabemos qué estados necesitamos o tenemos. Por cierto, en la mayoría de los casos, los estados describirían la lógica de negocio de nuestra aplicación, mientras que las transiciones son muy a menudo desconocidas al principio. Los errores en nuestro software son el resultado de acciones despachadas en un estado erróneo y/o en el momento equivocado. Dejan nuestra aplicación en un estado que desconocemos, y esto rompe nuestro programa o hace que se comporte incorrectamente. Por supuesto, no queremos estar en esa situación. Las máquinas de estado son buenos cortafuegos. Nos protegen de llegar a estados desconocidos porque establecemos los límites de lo que puede ocurrir y cuándo, sin decir explícitamente cómo. El concepto de una máquina de estado se combina muy bien con un flujo de datos unidireccional. Juntos, reducen la complejidad del código y despejan el misterio de dónde se ha originado un estado.
Creando una máquina de estados en JavaScript
Basta de hablar – veamos algo de código. Utilizaremos el mismo ejemplo. Basándonos en la lista anterior, empezaremos con lo siguiente:
const machine = { 'idle': { click: function () { ... } }, 'fetching': { success: function () { ... }, failure: function () { ... } }, 'error': { 'retry': function () { ... } }}Tenemos los estados como objetos y sus posibles entradas como funciones. Sin embargo, falta el estado inicial. Cambiemos el código anterior por este:
const machine = { state: 'idle', transitions: { 'idle': { click: function() { ... } }, 'fetching': { success: function() { ... }, failure: function() { ... } }, 'error': { 'retry': function() { ... } } }}Una vez que definimos todos los estados que tienen sentido para nosotros, estamos listos para enviar la entrada y cambiar de estado. Para ello utilizaremos los dos métodos de ayuda que aparecen a continuación:
const machine = { dispatch(actionName, ...payload) { const actions = this.transitions; const action = this.transitions; if (action) { action.apply(machine, ...payload); } }, changeStateTo(newState) { this.state = newState; }, ...}La función dispatch comprueba si existe una acción con el nombre dado en las transiciones del estado actual. Si es así, la dispara con el payload dado. También estamos llamando al manejador action con el machine como contexto, para poder despachar otras acciones con this.dispatch(<action>) o cambiar el estado con this.changeStateTo(<new state>).
Siguiendo el recorrido del usuario de nuestro ejemplo, la primera acción que tenemos que despachar es click. Este es el aspecto del handler de esa acción:
transitions: { 'idle': { click: function () { this.changeStateTo('fetching'); service.getData().then( data => { try { this.dispatch('success', JSON.parse(data)); } catch (error) { this.dispatch('failure', error) } }, error => this.dispatch('failure', error) ); } }, ...}machine.dispatch('click');Primero cambiamos el estado de la máquina a fetching. Luego, lanzamos la petición al back end. Supongamos que tenemos un servicio con un método getData que devuelve una promesa. Una vez que se resuelve y el parseo de datos es correcto, despachamos success, si no failure.
Hasta aquí, todo bien. A continuación, tenemos que implementar las acciones y entradas success y failure bajo el estado fetching:
transitions: { 'idle': { ... }, 'fetching': { success: function (data) { // render the data this.changeStateTo('idle'); }, failure: function (error) { this.changeStateTo('error'); } }, ...}Nota cómo hemos liberado a nuestro cerebro de tener que pensar en el proceso anterior. No nos importan los clics del usuario ni lo que está ocurriendo con la petición HTTP. Sabemos que la aplicación está en un estado fetching, y estamos esperando sólo estas dos acciones. Es un poco como escribir una nueva lógica de forma aislada.
La última parte es el estado error. Estaría bien que proporcionáramos esa lógica de reintento para que la aplicación pueda recuperarse del fallo.
transitions: { 'error': { retry: function () { this.changeStateTo('idle'); this.dispatch('click'); } }}Aquí tenemos que duplicar la lógica que escribimos en el click handler. Para evitarlo, deberíamos definir el manejador como una función accesible a ambas acciones, o bien pasamos primero al estado idle y luego despachamos la acción click manualmente.
Un ejemplo completo de la máquina de estados que funciona se puede encontrar en mi Codepen.
Gestionando máquinas de estados con una librería
El patrón de máquina de estados finitos funciona independientemente de si usamos React, Vue o Angular. Como vimos en la sección anterior, podemos implementar fácilmente una máquina de estados sin mucho problema. Sin embargo, a veces una librería proporciona más flexibilidad. Algunas de las buenas son Machina.js y XState. En este artículo, sin embargo, hablaremos de Stent, mi librería similar a Redux que hornea el concepto de máquinas de estado finitas.
Stent es una implementación de un contenedor de máquinas de estado. Sigue algunas de las ideas de los proyectos Redux y Redux-Saga, pero proporciona, en mi opinión, procesos más simples y libres de boilerplate. Se desarrolla utilizando el desarrollo dirigido por el lector, y literalmente pasé semanas sólo en el diseño de la API. Como estaba escribiendo la librería, tuve la oportunidad de arreglar los problemas que encontré al usar las arquitecturas Redux y Flux.
Creando Máquinas
En la mayoría de los casos, nuestras aplicaciones cubren múltiples dominios. No podemos ir con una sola máquina. Por ello, Stent permite la creación de muchas máquinas:
import { Machine } from 'stent';const machineA = Machine.create('A', { state: ..., transitions: ...});const machineB = Machine.create('B', { state: ..., transitions: ...});Después, podemos acceder a estas máquinas mediante el método Machine.get:
const machineA = Machine.get('A');const machineB = Machine.get('B');Conectando las máquinas a la lógica de renderizado
El renderizado en mi caso se realiza mediante React, pero podemos utilizar cualquier otra librería. Se reduce a disparar un callback en el que desencadenamos el renderizado. Una de las primeras funciones en las que trabajé fue la función connect:
import { connect } from 'stent/lib/helpers';Machine.create('MachineA', ...);Machine.create('MachineB', ...);connect() .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { ... rendering here });Decimos qué máquinas son importantes para nosotros y damos sus nombres. El callback que pasamos a map se dispara una vez inicialmente y después cada vez que cambia el estado de alguna de las máquinas. Aquí es donde disparamos el renderizado. En este punto, tenemos acceso directo a las máquinas conectadas, por lo que podemos recuperar el estado actual y los métodos. También hay mapOnce, para conseguir que el callback se dispare una sola vez, y mapSilent, para saltarse esa ejecución inicial.
Para mayor comodidad, se exporta un helper específico para la integración con React. Es realmente similar al connect(mapStateToProps) de Redux.
import React from 'react';import { connect } from 'stent/lib/react';class TodoList extends React.Component { render() { const { isIdle, todos } = this.props; ... }}// MachineA and MachineB are machines defined// using Machine.create functionexport default connect(TodoList) .with('MachineA', 'MachineB') .map((MachineA, MachineB) => { isIdle: MachineA.isIdle, todos: MachineB.state.todos });Stent ejecuta nuestro callback de mapeo y espera recibir un objeto – un objeto que se envía como props a nuestro componente React.
¿Qué es el estado en el contexto de Stent?
Hasta ahora, nuestro estado ha sido simples cadenas. Desafortunadamente, en el mundo real, tenemos que mantener más que una cadena en el estado. Por eso el estado de Stent es en realidad un objeto con propiedades en su interior. La única propiedad reservada es name. Todo lo demás son datos específicos de la app. Por ejemplo:
{ name: 'idle' }{ name: 'fetching', todos: }{ name: 'forward', speed: 120, gear: 4 }Mi experiencia con Stent hasta ahora me muestra que si el objeto estado se hace más grande, probablemente necesitaríamos otra máquina que maneje esas propiedades adicionales. Identificar los distintos estados lleva algo de tiempo, pero creo que es un gran paso adelante para escribir aplicaciones más manejables. Es un poco como predecir el futuro y dibujar cuadros de las posibles acciones.
Trabajando con la máquina de estados
De forma similar al ejemplo del principio, tenemos que definir los posibles estados (finitos) de nuestra máquina y describir las posibles entradas:
import { Machine } from 'stent';const machine = Machine.create('sprinter', { state: { name: 'idle' }, // initial state transitions: { 'idle': { 'run please': function () { return { name: 'running' }; } }, 'running': { 'stop now': function () { return { name: 'idle' }; } } }});Tenemos nuestro estado inicial, idle, que acepta una acción de run. Una vez que la máquina está en un estado running, podemos disparar la acción stop, que nos devuelve al estado idle.
Probablemente recordarás los ayudantes dispatch y changeStateTo de nuestra implementación anterior. Esta biblioteca proporciona la misma lógica, pero está oculta internamente, y no tenemos que pensar en ella. Por comodidad, basándonos en la propiedad transitions, Stent genera lo siguiente:
- métodos de ayuda para comprobar si la máquina está en un estado concreto -el estado
idleproduce el métodoisIdle(), mientras que pararunningtenemosisRunning(); - Métodos de ayuda para el envío de acciones:
runPlease()ystopNow().
Así, en el ejemplo anterior, podemos utilizar esto:
machine.isIdle(); // booleanmachine.isRunning(); // booleanmachine.runPlease(); // fires actionmachine.stopNow(); // fires actionCombinando los métodos generados automáticamente con la función de utilidad connect, somos capaces de cerrar el círculo. Una interacción del usuario desencadena la entrada y la acción de la máquina, que actualiza el estado. Debido a esa actualización, la función de mapeo pasada a connect se dispara, y se nos informa del cambio de estado. A continuación, se vuelve a renderizar.
Controladores de entrada y acción
Probablemente la parte más importante son los controladores de acción. Este es el lugar donde escribimos la mayor parte de la lógica de la aplicación porque estamos respondiendo a la entrada y a los estados cambiados. Algo que me gusta mucho en Redux también está integrado aquí: la inmutabilidad y la simplicidad de la función reductora. La esencia del action handler de Stent es la misma. Recibe el estado actual y el payload de la acción, y debe devolver el nuevo estado. Si el manejador no devuelve nada (undefined), entonces el estado de la máquina permanece igual.
transitions: { 'fetching': { 'success': function (state, payload) { const todos = ; return { name: 'idle', todos }; } }}Supongamos que necesitamos obtener datos de un servidor remoto. Disparamos la petición y transicionamos la máquina a un estado fetching. Una vez que los datos llegan desde el back-end, disparamos una acción success, así:
machine.success({ label: '...' });Entonces, volvemos a un estado idle y guardamos algunos datos en forma de la matriz todos. Hay un par de otros valores posibles para establecer como manejadores de acción. El primer caso, y el más sencillo, es cuando pasamos sólo una cadena que se convierte en el nuevo estado.
transitions: { 'idle': { 'run': 'running' }}Esta es una transición de { name: 'idle' } a { name: 'running' } utilizando la acción run(). Este enfoque es útil cuando tenemos transiciones de estado sincrónicas y no tenemos metadatos. Así, si mantenemos algo más en el estado, ese tipo de transición lo expulsará. Del mismo modo, podemos pasar un objeto de estado directamente:
transitions: { 'editing': { 'delete all todos': { name: 'idle', todos: } }}Estamos haciendo una transición de editing a idle utilizando la acción deleteAllTodos.
Ya vimos el manejador de funciones, y la última variante del manejador de acciones es una función generadora. Está inspirada en el proyecto Redux-Saga, y tiene este aspecto:
import { call } from 'stent/lib/helpers';Machine.create('app', { 'idle': { 'fetch data': function * (state, payload) { yield { name: 'fetching' } try { const data = yield call(requestToBackend, '/api/todos/', 'POST'); return { name: 'idle', data }; } catch (error) { return { name: 'error', error }; } } }});Si no tienes experiencia con generadores, esto puede parecer un poco críptico. Pero los generadores en JavaScript son una poderosa herramienta. Nos permiten pausar nuestro manejador de acciones, cambiar de estado múltiples veces y manejar la lógica asíncrona.
Diversión con los generadores
Cuando me presentaron por primera vez Redux-Saga, pensé que era una forma demasiado complicada de manejar las operaciones asíncronas. En realidad, es una implementación bastante inteligente del patrón de diseño de comandos. El principal beneficio de este patrón es que separa la invocación de la lógica y su implementación real.
En otras palabras, decimos lo que queremos pero no cómo debe suceder. La serie de blogs de Matt Hink me ayudó a entender cómo se implementan las sagas, y recomiendo encarecidamente su lectura. He traído las mismas ideas a Stent, y para el propósito de este artículo, diremos que al ceder cosas, estamos dando instrucciones sobre lo que queremos sin hacerlo realmente. Una vez realizada la acción, recibimos el control de vuelta.
De momento, se pueden enviar (ceder) un par de cosas:
- un objeto de estado (o una cadena) para cambiar el estado de la máquina;
- una llamada del helper
call(acepta una función síncrona, que es una función que devuelve una promesa u otra función generadora) – básicamente estamos diciendo: «Ejecuta esto por mí, y si es asíncrono, espera. Una vez que haya terminado, dame el resultado»; - una llamada del helper
wait(acepta una cadena que representa otra acción); si usamos esta función de utilidad, pausamos el handler y esperamos a que se despache otra acción.
Aquí tenemos una función que ilustra las variantes:
const fireHTTPRequest = function () { return new Promise((resolve, reject) => { // ... });}...transitions: { 'idle': { 'fetch data': function * () { yield 'fetching'; // sets the state to { name: 'fetching' } yield { name: 'fetching' }; // same as above // wait for getTheData and checkForErrors actions // to be dispatched const = yield wait('get the data', 'check for errors'); // wait for the promise returned by fireHTTPRequest // to be resolved const result = yield call(fireHTTPRequest, '/api/data/users'); return { name: 'finish', users: result }; } }}Como podemos ver, el código parece sincrónico, pero en realidad no lo es. Es simplemente Stent haciendo la parte aburrida de esperar la promesa resuelta o iterar sobre otro generador.
Cómo Stent está resolviendo mis preocupaciones sobre Redux
Demasiado código boilerplate
La arquitectura Redux (y Flux) se basa en acciones que circulan por nuestro sistema. Cuando la aplicación crece, solemos acabar teniendo muchas constantes y creadores de acciones. Estas dos cosas están muy a menudo en diferentes carpetas, y el seguimiento de la ejecución del código a veces lleva tiempo. Además, al añadir una nueva función, siempre tenemos que lidiar con todo un conjunto de acciones, lo que significa definir más nombres de acciones y creadores de acciones.
En Stent, no tenemos nombres de acciones, y la librería crea los creadores de acciones automáticamente por nosotros:
const machine = Machine.create('todo-app', { state: { name: 'idle', todos: }, transitions: { 'idle': { 'add todo': function (state, todo) { ... } } }});machine.addTodo({ title: 'Fix that bug' });Tenemos el machine.addTodo creador de acciones definido directamente como un método de la máquina. Este enfoque también resolvió otro problema al que me enfrenté: encontrar el reductor que responde a una acción concreta. Normalmente, en los componentes de React, vemos nombres de creadores de acciones como addTodo; sin embargo, en los reductores, trabajamos con un tipo de acción que es constante. A veces tengo que saltar al código del creador de la acción para poder ver el tipo exacto. Aquí, no tenemos ningún tipo.
Cambios de estado impredecibles
En general, Redux hace un buen trabajo gestionando el estado de forma inmutable. El problema no está en Redux en sí, sino en que se permite al desarrollador despachar cualquier acción en cualquier momento. Si decimos que tenemos una acción que enciende las luces, ¿está bien disparar esa acción dos veces seguidas? Si no es así, ¿cómo se supone que vamos a resolver este problema con Redux? Bueno, probablemente pondríamos algún código en el reductor que proteja la lógica y que compruebe si las luces ya están encendidas – quizás una cláusula if que compruebe el estado actual. Ahora la pregunta es, ¿no está esto más allá del alcance del reductor? ¿Debería el reductor conocer estos casos extremos?
Lo que me falta en Redux es una forma de detener el envío de una acción basada en el estado actual de la aplicación sin contaminar el reductor con lógica condicional. Y tampoco quiero llevar esta decisión a la capa de vista, donde se dispara el creador de la acción. Con Stent, esto sucede automáticamente porque la máquina no responde a las acciones que no están declaradas en el estado actual. Por ejemplo:
const machine = Machine.create('app', { state: { name: 'idle' }, transitions: { 'idle': { 'run': 'running', 'jump': 'jumping' }, 'running': { 'stop': 'idle' } }});// this is finemachine.run();// This will do nothing because at this point// the machine is in a 'running' state and there is// only 'stop' action there.machine.jump();El hecho de que la máquina sólo acepte entradas específicas en un momento dado nos protege de bugs extraños y hace que nuestras aplicaciones sean más predecibles.
Estados, no transiciones
Redux, como Flux, nos hace pensar en términos de transiciones. El modelo mental de desarrollar con Redux está bastante dirigido por acciones y cómo estas acciones transforman el estado en nuestros reductores. Eso no es malo, pero he encontrado que tiene más sentido pensar en términos de estados en su lugar – qué estados la aplicación podría estar en y cómo estos estados representan los requisitos de negocio.
Conclusión
El concepto de máquinas de estado en la programación, especialmente en el desarrollo de la interfaz de usuario, fue revelador para mí. Empecé a ver máquinas de estado en todas partes, y tengo cierto deseo de cambiar siempre a ese paradigma. Definitivamente veo los beneficios de tener estados más estrictamente definidos y transiciones entre ellos. Siempre estoy buscando formas de hacer que mis aplicaciones sean sencillas y legibles. Creo que las máquinas de estado son un paso en esta dirección. El concepto es simple y al mismo tiempo poderoso. Tiene el potencial de eliminar un montón de bugs.