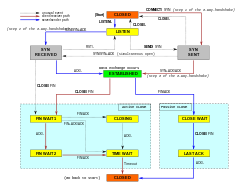
Una conexión TCP es gestionada por un sistema operativo a través de un recurso que representa el punto final local para las comunicaciones, el socket de Internet. Durante la vida de una conexión TCP, el punto final local sufre una serie de cambios de estado:
| Estado | Punto final | Descripción |
|---|---|---|
| LISTEN | Servidor | Esperando una solicitud de conexión desde cualquier punto final TCP remoto.remoto. |
| SYN-SENT | Cliente | En espera de una solicitud de conexión coincidente después de haber enviado una solicitud de conexión. |
| SYN-RECEIVED | Server | Waiting for a confirming connection request acknowledgment after having both received and sent a connection request. |
| ESTABLISHED | Server and client | Una conexión abierta, los datos recibidos pueden ser entregados al usuario. El estado normal para la fase de transferencia de datos de la conexión. |
| FIN-WAIT-1 | Servidor y cliente | Esperando una solicitud de terminación de la conexión desde el TCP remoto, o un acuse de recibo de la solicitud de terminación de la conexión enviada previamente. |
| FIN-WAIT-2 | Servidor y cliente | En espera de una solicitud de finalización de conexión del TCP remoto. |
| CLOSE-WAIT | Servidor y cliente | En espera de una solicitud de finalización de conexión del usuario local. |
| CERRAR | Servidor y cliente | Esperando un acuse de recibo de solicitud de finalización de conexión desde el TCP remoto. |
| LAST-ACK | Servidor y cliente | Esperando un acuse de recibo de la solicitud de terminación de conexión enviada previamente al TCP remoto (que incluye un acuse de recibo de su solicitud de terminación de conexión). |
| TIME-WAIT | Servidor o cliente | Esperando a que pase el tiempo suficiente para estar seguros de que el TCP remoto ha recibido el acuse de recibo de su solicitud de terminación de conexión. |
| Cerrado | Servidor y cliente | Sin estado de conexión. |
Establecimiento de la conexiónEditar
Antes de que un cliente intente conectarse con un servidor, éste debe primero enlazar y escuchar en un puerto para abrirlo a las conexiones: esto se llama apertura pasiva. Una vez establecida la apertura pasiva, un cliente puede establecer una conexión iniciando una apertura activa utilizando el handshake de tres vías (o 3 pasos):
- SYN: La apertura activa se realiza enviando el cliente un SYN al servidor. El cliente establece el número de secuencia del segmento a un valor aleatorio A.
- SYN-ACK: En respuesta, el servidor responde con un SYN-ACK. El número de acuse de recibo se establece en uno más que el número de secuencia recibido, es decir, A+1, y el número de secuencia que el servidor elige para el paquete es otro número aleatorio, B.
- ACK: Finalmente, el cliente envía un ACK de vuelta al servidor. El número de secuencia se establece en el valor de acuse de recibo, es decir, A+1, y el número de acuse de recibo se establece en uno más que el número de secuencia recibido, es decir, B+1.
- Transferencia de datos ordenada: el host de destino reordena los segmentos según un número de secuencia
- Retransmisión de paquetes perdidos: cualquier flujo acumulado no reconocido se retransmite
- Transferencia de datos sin errores
- Control de flujo: limita la velocidad a la que un emisor transfiere datos para garantizar una entrega fiable. El receptor indica continuamente al emisor la cantidad de datos que puede recibir (controlado por la ventana deslizante). Cuando el búfer del host receptor se llena, el siguiente acuse de recibo contiene un 0 en el tamaño de la ventana, para detener la transferencia y permitir que se procesen los datos del búfer.
- Control de congestión
Los pasos 1 y 2 establecen y reconocen el número de secuencia para una dirección. Los pasos 2 y 3 establecen y reconocen el número de secuencia para la otra dirección. Tras la realización de estos pasos, tanto el cliente como el servidor han recibido acuses de recibo y se establece una comunicación full-duplex.
Terminación de la conexiónEditar

La fase de terminación de la conexión utiliza un handshake de cuatro vías, con cada lado de la conexión terminando independientemente. Cuando un punto final desea detener su mitad de la conexión, transmite un paquete FIN, que el otro extremo reconoce con un ACK. Por lo tanto, una interrupción típica requiere un par de segmentos FIN y ACK de cada extremo TCP. Después de que el lado que envió el primer FIN haya respondido con el ACK final, espera un tiempo de espera antes de cerrar finalmente la conexión, durante el cual el puerto local no está disponible para nuevas conexiones; esto evita la confusión debida a los paquetes retrasados que se entregan durante las conexiones posteriores.
Una conexión puede estar «medio abierta», en cuyo caso un lado ha terminado su extremo, pero el otro no. El lado que ha terminado ya no puede enviar ningún dato a la conexión, pero el otro lado sí. El lado que termina debe continuar leyendo los datos hasta que el otro lado también termine.
También es posible terminar la conexión mediante un handshake de 3 vías, cuando el host A envía un FIN y el host B responde con un FIN & ACK (simplemente combina 2 pasos en uno) y el host A responde con un ACK.
Algunos sistemas operativos, como Linux y H-UX, implementan una secuencia de cierre semidúplex en la pila TCP. Si el host cierra activamente una conexión, mientras que todavía tiene datos entrantes no leídos disponibles, el host envía la señal RST (perdiendo cualquier dato recibido) en lugar de FIN. Esto asegura a una aplicación TCP que el proceso remoto ha leído todos los datos transmitidos esperando la señal FIN, antes de cerrar activamente la conexión. El proceso remoto no puede distinguir entre una señal RST para abortar la conexión y la pérdida de datos. Ambas cosas hacen que la pila remota pierda todos los datos recibidos.
Algunas aplicaciones que utilizan el protocolo de handshaking TCP de apertura/cierre pueden encontrar el problema del RST en el cierre activo. Como ejemplo:
s = connect(remote);send(s, data);close(s);
Para un flujo de programa como el anterior, una pila TCP/IP como la descrita anteriormente no garantiza que todos los datos lleguen a la otra aplicación si han llegado datos no leídos a este extremo.
Uso de recursosEditar
La mayoría de las implementaciones asignan una entrada en una tabla que asigna una sesión a un proceso del sistema operativo en ejecución. Como los paquetes TCP no incluyen un identificador de sesión, ambos extremos identifican la sesión utilizando la dirección y el puerto del cliente. Cada vez que se recibe un paquete, la implementación de TCP debe realizar una búsqueda en esta tabla para encontrar el proceso de destino. Cada entrada de la tabla se conoce como Bloque de Control de Transmisión o TCB. Contiene información sobre los puntos finales (IP y puerto), el estado de la conexión, datos de ejecución sobre los paquetes que se están intercambiando y búferes para el envío y la recepción de datos.
El número de sesiones en el lado del servidor está limitado sólo por la memoria y puede crecer a medida que llegan nuevas conexiones, pero el cliente debe asignar un puerto aleatorio antes de enviar el primer SYN al servidor. Este puerto permanece asignado durante toda la conversación, y limita efectivamente el número de conexiones salientes desde cada una de las direcciones IP del cliente. Si una aplicación no cierra correctamente las conexiones no solicitadas, un cliente puede quedarse sin recursos y ser incapaz de establecer nuevas conexiones TCP, incluso desde otras aplicaciones.
Ambos puntos finales también deben asignar espacio para los paquetes no reconocidos y los datos recibidos (pero no leídos).
Transferencia de datosEditar
El Protocolo de Control de Transmisión difiere en varias características clave del Protocolo de Datagramas de Usuario:
Transmisión fiable
TCP utiliza un número de secuencia para identificar cada byte de datos. El número de secuencia identifica el orden de los bytes enviados desde cada equipo para que los datos puedan ser reconstruidos en orden, independientemente de cualquier reordenación de paquetes, o pérdida de paquetes que pueda ocurrir durante la transmisión. El número de secuencia del primer byte es elegido por el transmisor para el primer paquete, que se marca como SYN. Este número puede ser arbitrario, y debería, de hecho, ser impredecible para defenderse de los ataques de predicción de secuencia TCP.
Los ACKs son enviados con un número de secuencia por el receptor de los datos para indicar al emisor que los datos han sido recibidos hasta el byte especificado. Los ACKs no implican que los datos hayan sido entregados a la aplicación. Simplemente significan que ahora es responsabilidad del receptor entregar los datos.
La fiabilidad se consigue gracias a que el emisor detecta los datos perdidos y los retransmite. TCP utiliza dos técnicas principales para identificar la pérdida. El tiempo de espera de retransmisión (abreviado como RTO) y los acuses de recibo acumulativos duplicados (DupAcks).
Retransmisión basada en DupackEditar
Si se pierde un solo segmento (digamos el segmento 100) en un flujo, entonces el receptor no puede acusar recibo de los paquetes por encima del nº. 100 porque utiliza ACKs acumulativos. Por lo tanto, el receptor reconoce el paquete 99 de nuevo al recibir otro paquete de datos. Este acuse de recibo duplicado se utiliza como señal de pérdida de paquetes. Es decir, si el emisor recibe tres acuses de recibo duplicados, retransmite el último paquete no reconocido. Se utiliza un umbral de tres porque la red puede reordenar los segmentos causando acuses de recibo duplicados. Se ha demostrado que este umbral evita las retransmisiones falsas debidas a la reordenación. A veces se utilizan acuses de recibo selectivos (SACK) para proporcionar información explícita sobre los segmentos que se han recibido. Esto mejora en gran medida la capacidad de TCP para retransmitir los segmentos correctos.
Retransmisión basada en el tiempo de esperaEditar
Cuando un emisor transmite un segmento, inicializa un temporizador con una estimación conservadora de la hora de llegada del acuse de recibo. El segmento se retransmite si el temporizador expira, con un nuevo umbral de tiempo de espera del doble del valor anterior, lo que resulta en un comportamiento de backoff exponencial. Típicamente, el valor inicial del temporizador es RTT suavizado + max ( G , 4 × variación de RTT ) {\displaystyle {\text{smoothed RTT}}+\max(G,4\times {\text{variación de RTT}})}.

, donde G {{desde el estilo de visualización G}

es la granularidad del reloj. Esto protege contra el tráfico de transmisión excesivo debido a actores defectuosos o maliciosos, como los atacantes de denegación de servicio man-in-the-middle.
Detección de erroresEditar
Los números de secuencia permiten a los receptores descartar los paquetes duplicados y secuenciar adecuadamente los paquetes reordenados. Los acuses de recibo permiten a los remitentes determinar cuándo deben retransmitir los paquetes perdidos.
Para asegurar la corrección se incluye un campo de suma de comprobación; véase la sección de cálculo de la suma de comprobación para conocer los detalles de la misma. La suma de comprobación TCP es una comprobación débil según los estándares modernos. Las capas de enlace de datos con altas tasas de error de bits pueden requerir capacidades adicionales de corrección/detección de errores de enlace. La débil suma de comprobación se compensa parcialmente con el uso común de un CRC o una mejor comprobación de integridad en la capa 2, por debajo de TCP e IP, como se utiliza en PPP o en la trama Ethernet. Sin embargo, esto no significa que la suma de comprobación de 16 bits de TCP sea redundante: notablemente, la introducción de errores en paquetes entre saltos protegidos por CRC es común, pero la suma de comprobación de 16 bits de TCP de extremo a extremo atrapa la mayoría de estos simples errores. Este es el principio de extremo a extremo en el trabajo.
Control de flujoEditar
TCP utiliza un protocolo de control de flujo de extremo a extremo para evitar que el remitente envíe datos demasiado rápido para que el receptor TCP los reciba y procese de forma fiable. Disponer de un mecanismo de control de flujo es esencial en un entorno en el que se comunican máquinas de diversas velocidades de red. Por ejemplo, si un PC envía datos a un smartphone que procesa lentamente los datos recibidos, el smartphone debe regular el flujo de datos para no verse desbordado.
TCP utiliza un protocolo de control de flujo de ventana deslizante. En cada segmento TCP, el receptor especifica en el campo de ventana de recepción la cantidad de datos recibidos adicionalmente (en bytes) que está dispuesto a almacenar en el búfer para la conexión. El host emisor sólo puede enviar esa cantidad de datos antes de tener que esperar un acuse de recibo y una actualización de la ventana por parte del host receptor.

Cuando un receptor anuncia un tamaño de ventana de 0, el emisor deja de enviar datos y pone en marcha el temporizador de persistencia. El temporizador de persistencia se utiliza para proteger a TCP de una situación de bloqueo que podría surgir si se pierde una actualización posterior del tamaño de la ventana del receptor, y el emisor no puede enviar más datos hasta recibir una nueva actualización del tamaño de la ventana del receptor. Cuando el temporizador de persistencia expira, el emisor TCP intenta recuperarse enviando un pequeño paquete para que el receptor responda enviando otro acuse de recibo que contenga el nuevo tamaño de ventana.
Si un receptor está procesando los datos entrantes en pequeños incrementos, puede anunciar repetidamente una pequeña ventana de recepción. Esto se conoce como el síndrome de la ventana tonta, ya que es ineficiente enviar sólo unos pocos bytes de datos en un segmento TCP, dada la sobrecarga relativamente grande de la cabecera TCP.
Control de congestiónEditar
El último aspecto principal de TCP es el control de congestión. TCP utiliza una serie de mecanismos para lograr un alto rendimiento y evitar el colapso de la congestión, donde el rendimiento de la red puede caer en varios órdenes de magnitud. Estos mecanismos controlan la tasa de datos que entran en la red, manteniendo el flujo de datos por debajo de una tasa que provocaría el colapso. También producen una asignación justa aproximadamente máxima entre los flujos.
Los remitentes utilizan los acuses de recibo de los datos enviados, o la falta de ellos, para inferir las condiciones de la red entre el emisor y el receptor TCP. Junto con los temporizadores, los emisores y receptores TCP pueden alterar el comportamiento del flujo de datos. Esto se conoce más generalmente como control de la congestión y/o evitación de la congestión de la red.
Las implementaciones modernas de TCP contienen cuatro algoritmos entrelazados: inicio lento, evitación de la congestión, retransmisión rápida y recuperación rápida (RFC 5681).
Además, los remitentes emplean un tiempo de espera de retransmisión (RTO) que se basa en el tiempo estimado de ida y vuelta (o RTT) entre el remitente y el receptor, así como en la variación de este tiempo de ida y vuelta. El comportamiento de este temporizador se especifica en el RFC 6298. Hay sutilezas en la estimación del RTT. Por ejemplo, los remitentes deben tener cuidado al calcular las muestras de RTT para los paquetes retransmitidos; normalmente utilizan el Algoritmo de Karn o las marcas de tiempo TCP (ver RFC 1323). Estas muestras individuales de RTT se promedian en el tiempo para crear un tiempo de ida y vuelta suavizado (SRTT) utilizando el algoritmo de Jacobson. Este valor de SRTT es el que se utiliza finalmente como estimación del tiempo de ida y vuelta.
La mejora de TCP para manejar de forma fiable las pérdidas, minimizar los errores, gestionar la congestión e ir rápido en entornos de muy alta velocidad son áreas de investigación y desarrollo de estándares en curso. Como resultado, hay una serie de variaciones del algoritmo de evitación de la congestión TCP.
Tamaño máximo del segmentoEditar
El tamaño máximo del segmento (MSS) es la mayor cantidad de datos, especificada en bytes, que TCP está dispuesto a recibir en un solo segmento. Para obtener el mejor rendimiento, el MSS debe establecerse lo suficientemente pequeño como para evitar la fragmentación de IP, que puede conducir a la pérdida de paquetes y retransmisiones excesivas. Para intentar conseguirlo, normalmente el MSS es anunciado por cada lado utilizando la opción MSS cuando se establece la conexión TCP, en cuyo caso se deriva del tamaño de la unidad máxima de transmisión (MTU) de la capa de enlace de datos de las redes a las que están conectados directamente el emisor y el receptor. Además, los remitentes TCP pueden utilizar el descubrimiento de la MTU de la ruta para inferir la MTU mínima a lo largo de la ruta de red entre el remitente y el receptor, y utilizarla para ajustar dinámicamente la MSS para evitar la fragmentación de IP dentro de la red.
El anuncio de la MSS también se suele llamar «negociación de la MSS». En sentido estricto, el MSS no se «negocia» entre el emisor y el receptor, porque eso implicaría que tanto el emisor como el receptor negociarán y acordarán un único MSS unificado que se aplique a toda la comunicación en ambas direcciones de la conexión. De hecho, se permiten dos valores completamente independientes de MSS para las dos direcciones del flujo de datos en una conexión TCP. Esta situación puede producirse, por ejemplo, si uno de los dispositivos que participan en una conexión tiene una cantidad de memoria reservada extremadamente limitada (quizás incluso menor que la MTU global de la ruta descubierta) para procesar los segmentos TCP entrantes.
Reconocimientos selectivosEditar
Confiar puramente en el esquema de acuse de recibo acumulativo empleado por el protocolo TCP original puede llevar a ineficiencias cuando se pierden paquetes. Por ejemplo, supongamos que los bytes con número de secuencia 1.000 a 10.999 se envían en 10 segmentos TCP diferentes de igual tamaño, y el segundo segmento (números de secuencia 2.000 a 2.999) se pierde durante la transmisión. En un protocolo de acuse de recibo acumulativo puro, el receptor sólo puede enviar un valor ACK acumulativo de 2.000 (el número de secuencia inmediatamente posterior al último número de secuencia de los datos recibidos) y no puede decir que ha recibido correctamente los bytes 3.000 a 10.999. Por lo tanto, el emisor puede tener que volver a enviar todos los datos a partir del número de secuencia 2.000.
Para paliar este problema, TCP emplea la opción de acuse de recibo selectivo (SACK), definida en 1996 en el RFC 2018, que permite al receptor acusar recibo de bloques discontinuos de paquetes que se han recibido correctamente, además del número de secuencia inmediatamente posterior al último número de secuencia del último byte contiguo recibido sucesivamente, como en el acuse de recibo TCP básico. El acuse de recibo puede especificar un número de bloques SACK, donde cada bloque SACK se transmite por el borde izquierdo del bloque (el primer número de secuencia del bloque) y el borde derecho del bloque (el número de secuencia inmediatamente posterior al último número de secuencia del bloque), siendo un bloque un rango contiguo que el receptor recibió correctamente. En el ejemplo anterior, el receptor enviaría un segmento ACK con un valor ACK acumulado de 2.000 y una cabecera de opción SACK con los números de secuencia 3.000 y 11.000. En consecuencia, el emisor retransmitiría sólo el segundo segmento con los números de secuencia 2.000 a 2.999.
Un emisor TCP puede interpretar una entrega de segmento fuera de orden como un segmento perdido. Si lo hace, el emisor TCP retransmitirá el segmento anterior al paquete fuera de orden y reducirá su tasa de entrega de datos para esa conexión. La opción duplicate-SACK, una extensión de la opción SACK que se definió en mayo de 2000 en el RFC 2883, resuelve este problema. El receptor TCP envía un D-ACK para indicar que no se ha perdido ningún segmento, y el emisor TCP puede entonces restablecer la tasa de transmisión más alta.
La opción SACK no es obligatoria, y entra en funcionamiento sólo si ambas partes la soportan. Se negocia cuando se establece una conexión. SACK utiliza una opción de la cabecera TCP (véase la estructura del segmento TCP para más detalles). El uso de SACK se ha generalizado: todas las pilas TCP populares lo soportan. El acuse de recibo selectivo también se utiliza en el Protocolo de Transmisión de Control de Flujo (SCTP).
Escala de ventanaEditar
Para un uso más eficiente de las redes de gran ancho de banda, se puede utilizar un tamaño de ventana TCP mayor. El campo de tamaño de la ventana TCP controla el flujo de datos y su valor está limitado a entre 2 y 65.535 bytes.
Como el campo de tamaño no se puede ampliar, se utiliza un factor de escala. La opción de escala de ventana TCP, definida en el RFC 1323, es una opción que se utiliza para aumentar el tamaño máximo de la ventana de 65.535 bytes a 1 gigabyte. El escalado a tamaños de ventana más grandes es una parte de lo que es necesario para el ajuste de TCP.
La opción de escala de ventana se utiliza sólo durante el handshake de 3 vías de TCP. El valor de la escala de la ventana representa el número de bits para desplazar a la izquierda el campo de tamaño de ventana de 16 bits. El valor de la escala de la ventana puede establecerse de 0 (sin desplazamiento) a 14 para cada dirección independientemente. Ambos lados deben enviar la opción en sus segmentos SYN para habilitar la escala de ventana en cualquier dirección.
Algunos routers y cortafuegos de paquetes reescriben el factor de escala de ventana durante una transmisión. Esto hace que los lados emisor y receptor asuman diferentes tamaños de ventana TCP. El resultado es un tráfico no estable que puede ser muy lento. El problema es visible en algunos sitios detrás de un enrutador defectuoso.
Etiquetas de tiempo TCPEditar
Las etiquetas de tiempo TCP, definidas en RFC 1323 en 1992, pueden ayudar a TCP a determinar en qué orden se enviaron los paquetes.Las etiquetas de tiempo TCP normalmente no están alineadas con el reloj del sistema y comienzan en algún valor aleatorio. Muchos sistemas operativos incrementarán la marca de tiempo por cada milisegundo transcurrido; sin embargo, el RFC sólo establece que los ticks deben ser proporcionales.
Hay dos campos de marca de tiempo:
un valor de marca de tiempo del remitente de 4 bytes (mi marca de tiempo) un valor de marca de tiempo de respuesta del eco de 4 bytes (la marca de tiempo más reciente recibida de usted).
Las marcas de tiempo TCP se utilizan en un algoritmo conocido como Protección Contra Números de Secuencia Envueltos, o PAWS (ver RFC 1323 para más detalles). PAWS se utiliza cuando la ventana de recepción cruza el límite del número de secuencia envuelto. En el caso de que un paquete sea potencialmente retransmitido, responde a la pregunta «¿Este número de secuencia está en los primeros 4 GB o en los segundos?» Y la marca de tiempo se utiliza para romper el empate.
Además, el algoritmo de detección Eifel (RFC 3522) utiliza las marcas de tiempo TCP para determinar si las retransmisiones se producen porque los paquetes se pierden o simplemente están fuera de orden.
Las estadísticas recientes muestran que el nivel de adopción de las marcas de tiempo se ha estancado, en un ~40%, debido a que el servidor de Windows abandonó el soporte desde Windows Server 2008.
Las marcas de tiempo TCP están habilitadas por defecto en el núcleo de Linux., y deshabilitadas por defecto en Windows Server 2008, 2012 y 2016.
Datos fuera de bandaEditar
Es posible interrumpir o abortar el flujo en cola en lugar de esperar a que el flujo termine. Esto se hace especificando los datos como urgentes. Esto le dice al programa receptor que lo procese inmediatamente, junto con el resto de los datos urgentes. Cuando termina, TCP informa a la aplicación y vuelve a la cola del flujo. Un ejemplo es cuando se utiliza TCP para una sesión de inicio de sesión remota, el usuario puede enviar una secuencia de teclado que interrumpe o aborta el programa en el otro extremo. Estas señales suelen ser necesarias cuando un programa en la máquina remota no funciona correctamente. Las señales deben enviarse sin esperar a que el programa termine su transferencia actual.
Los datos fuera de banda de TCP no fueron diseñados para la Internet moderna. El puntero urgente sólo altera el procesamiento en el host remoto y no agiliza ningún procesamiento en la propia red. Cuando llega al host remoto hay dos interpretaciones ligeramente diferentes del protocolo, lo que significa que sólo los bytes individuales de datos OOB son fiables. Esto suponiendo que sea fiable en absoluto, ya que es uno de los elementos del protocolo menos utilizados y tiende a estar mal implementado.
Forzar la entrega de datosEditar
Normalmente, TCP espera 200 ms para enviar un paquete completo de datos (el Algoritmo de Nagle intenta agrupar los mensajes pequeños en un solo paquete). Esta espera crea pequeños, pero potencialmente serios retrasos si se repite constantemente durante una transferencia de archivos. Por ejemplo, un bloque de envío típico sería de 4 KB, un MSS típico es de 1460, por lo que salen 2 paquetes en una ethernet de 10 Mbit/s que tardan ~1,2 ms cada uno, seguidos de un tercero que lleva los 1176 restantes después de una pausa de 197 ms porque TCP está esperando un búfer lleno.
En el caso de telnet, cada pulsación del usuario es devuelta por el servidor antes de que el usuario pueda verla en la pantalla. Este retardo llegaría a ser muy molesto.
Configurar la opción de socket TCP_NODELAY anula el retardo de envío de 200 ms por defecto. Los programas de aplicación utilizan esta opción de socket para forzar el envío de la salida después de escribir un carácter o una línea de caracteres.
El RFC define el bit PSH push como «un mensaje a la pila TCP receptora para que envíe estos datos inmediatamente hasta la aplicación receptora». No hay forma de indicarlo o controlarlo en el espacio de usuario usando sockets Berkeley y es controlado por la pila del protocolo solamente.