Definicje statystyk > Analiza czynnikowa
Zawartość:
- Co to jest analiza czynnikowa?
- Ładunki czynnikowe
- Analiza wieloczynnikowa
- Potwierdzająca analiza czynnikowa
- Eksploracyjna analiza czynnikowa
- Co to jest uogólniona analiza Procrustesa (GPA)
- Co to są zmienne ukryte?
- Co to są zmienne manifestacyjne?
Co to jest analiza czynnikowa?
Analiza czynnikowa jest sposobem na wykorzystanie dużej ilości danych i zmniejszenie ich do mniejszego zbioru, który jest bardziej zarządzany i bardziej zrozumiały. Jest to sposób na znalezienie ukrytych wzorców, pokazanie jak te wzorce się pokrywają i jakie cechy są widoczne w wielu wzorcach. Jest on również używany do tworzenia zestawu zmiennych dla podobnych elementów w zestawie (te zestawy zmiennych nazywane są wymiarami). Może to być bardzo użyteczne narzędzie dla złożonych zbiorów danych obejmujących badania psychologiczne, status społeczno-ekonomiczny i inne zaangażowane koncepcje. Czynnik” jest zbiorem obserwowanych zmiennych, które mają podobne wzorce odpowiedzi; są one związane z ukrytą zmienną (zwaną zmienną zakłócającą), która nie jest bezpośrednio mierzona. Czynniki są wymienione zgodnie z ładunkami czynnikowymi, czyli jak wiele zmienności w danych mogą wyjaśnić.
Dwa rodzaje: eksploracyjna i konfirmacyjna.
- Eksploracyjna analiza czynnikowa jest wtedy, gdy nie masz pojęcia, jaką strukturę mają twoje dane lub ile wymiarów jest w zestawie zmiennych.
- Konfirmacyjna analiza czynnikowa służy do weryfikacji, o ile masz konkretny pomysł na to, jaką strukturę mają Twoje dane lub ile wymiarów jest w zestawie zmiennych.
Obciążenia czynnikowe
Image:USGS.gov
Nie wszystkie czynniki są sobie równe; niektóre czynniki mają większą wagę niż inne. W prostym przykładzie, wyobraź sobie, że Twój bank przeprowadza telefoniczną ankietę na temat satysfakcji klienta, a wyniki pokazują następujące ładunki czynnikowe:
| Zmienna | Faktor 1 | Faktor 2 | Współczynnik 3 | Pytanie 1 | 0.885 | 0,121 | -0,033 |
|---|---|---|---|
| Pytanie 2 | 0,829 | 0,078 | 0,157 |
| Pytanie 3 | 0,777 | 0,190 | 0.540 |
Czynniki, które mają największy wpływ na pytanie (i dlatego mają najwyższe ładunki czynnikowe) są pogrubione. Obciążenia czynnikowe są podobne do współczynników korelacji w tym sensie, że mogą wahać się od -1 do 1. Im bliżej -1 lub 1 znajdują się czynniki, tym bardziej wpływają na zmienną. Obciążenie czynnikowe równe zero wskazuje na brak wpływu.
Back to Top
Analiza wieloczynnikowa
Ten podzbiór analizy czynnikowej jest używany, gdy zmienne są zorganizowane w grupy zmiennych. Na przykład, możesz mieć kwestionariusz zdrowotny dla studentów z kilkoma pozycjami, takimi jak wzorce snu, uzależnienia, zdrowie psychiczne lub trudności w nauce.
Dwa kroki wykonywane w Wielokrotnej Analizie Czynnikowej to:
- Pierwotna Analiza Składowych jest wykonywana na każdym zestawie danych. Daje to wartość własną, która jest używana do normalizacji zbiorów danych.
- Nowe zbiory danych są łączone w unikalną macierz i wykonywana jest druga, globalna PCA.
Wykonanie analizy czynnikowej
Analiza czynnikowa jest niezwykle złożoną procedurą matematyczną i jest wykonywana za pomocą oprogramowania.
Instrukcje dla Stata można znaleźć tutaj.
Instrukcje dla Minitab są tutaj.la SPSS, zobacz ten artykuł.
Test Kaisera-Meyera-Olkina sprawdza, czy dane nadają się do FA.
Back to Top
Czym jest konfirmacyjna analiza czynnikowa?
Potwierdzająca analiza czynnikowa pozwala badaczowi dowiedzieć się, czy istnieje związek między zestawem obserwowanych zmiennych (zwanych też zmiennymi manifestacyjnymi) a leżącymi u ich podstaw konstruktami. Jest ona podobna do Eksploracyjnej Analizy Czynnikowej. Główna różnica między nimi jest następująca:
- Jeśli chcesz zbadać wzorce, użyj EFA.
- Jeśli chcemy przeprowadzić testowanie hipotez, używamy CFA.
EFA dostarcza informacji o optymalnej liczbie czynników wymaganych do reprezentacji zbioru danych. W konfirmacyjnej analizie czynnikowej można określić liczbę wymaganych czynników. Na przykład, CFA może odpowiedzieć na pytania typu: „Czy moja ankieta z dziesięcioma pytaniami dokładnie mierzy jeden określony czynnik?”. Chociaż technicznie ma zastosowanie w każdej dyscyplinie, zazwyczaj jest wykorzystywana w naukach społecznych.
Wdrażanie konfirmacyjnej analizy czynnikowej
Diane Suhr, PhD, na stronie internetowej SAS, sugeruje następujące kroki:
- Przeprowadź przegląd literatury, aby pomóc Ci wybrać odpowiedni model. Na przykład, możesz wybrać diagram lub równania.
- Określ, czy możliwe jest uzyskanie unikalnych wartości dla oszacowania parametrów populacji.
- Zbierz dane.
- Przeprowadź wstępną analizę danych, aby sprawdzić, czy nie występują takie problemy, jak brak danych, współliniowość lub wartości odstające.
- Oszacuj parametry populacji.
- Określ, czy wybrany model działa. Jeśli model jest nieakceptowalny, należy rozważyć wykonanie Wyjaśniającej Analizy Czynnikowej.
- Interpretacja wyników.
Według IBM, EFA wyprzedziła CFA jako sposób analizy czynnikowej. „Dominujące obecnie podejście do CFA polega na traktowaniu CFA jako specjalnego przypadku modelowania równań strukturalnych (SEM). Określa się ładunki czynnikowe jako zestaw twierdzeń regresji od czynnika do obserwowanych zmiennych”. W przypadku EFA możliwe jest określenie kilku czynników i określonej rotacji; następnie można porównać wyniki, aby sprawdzić, czy pasują do modelu.
Przeprowadzanie CFA
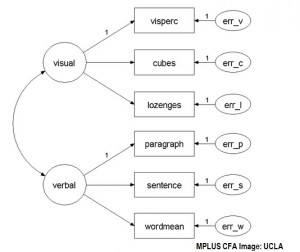
Do przeprowadzenia konfirmacyjnej analizy czynnikowej zwykle potrzebne jest oprogramowanie. SAS może być użyty do przeprowadzenia CFA. W momencie pisania tego tekstu, SPSS jest ograniczony tylko do EFA.
- Procedura SAS CFA.
- Instrukcje dotyczące systemuAMOS (pobierz dokument ze strony East Carolina University).
- Procedury systemuAMOS, LISREL, MPLUS.
Back to Top
Co to jest eksploracyjna analiza czynnikowa?
Eksploracyjna analiza czynnikowa (EFA) jest używana do znalezienia struktury leżącej u podstaw dużego zbioru zmiennych. Redukuje ona dane do znacznie mniejszego zbioru zmiennych podsumowujących.
EFA jest niemal identyczna z konfirmacyjną analizą czynnikową (CFA). Obie techniki mogą (być może zaskakująco) być użyte do potwierdzenia lub eksploracji. Podobieństwa są następujące:
- Ocena rzetelności wewnętrznej miary.
- Badanie czynników lub konstruktów teoretycznych reprezentowanych przez zestawy pozycji. Zakładają one, że czynniki nie są skorelowane.
- Badanie jakości poszczególnych pozycji.
Istnieją jednak pewne różnice, głównie dotyczące sposobu traktowania/używania czynników. EFA jest zasadniczo podejściem opartym na danych, pozwalającym wszystkim pozycjom na obciążenie wszystkich czynników, podczas gdy w przypadku CFA należy określić, które czynniki mają być obciążone. EFA jest dobrym wyborem, jeśli nie ma się pojęcia o tym, jakie wspólne czynniki mogą istnieć. EFA może wygenerować dużą liczbę możliwych modeli dla danych, co może nie być możliwe, jeśli badacz musi określić czynniki. Jeśli mamy pojęcie o tym jak wyglądają modele i chcemy przetestować hipotezy dotyczące struktury danych, CFA jest lepszym podejściem.
Co to jest uogólniona analiza Procrustesa (GPA)?
Analiza Procrustesa jest sposobem na porównanie dwóch zestawów konfiguracji lub kształtów. Pierwotnie opracowana w celu dopasowania dwóch rozwiązań z analizy czynnikowej, technika ta została rozszerzona do uogólnionej analizy Procrustesa, aby można było porównywać więcej niż dwa kształty. Kształty są dopasowywane do kształtu docelowego lub do siebie nawzajem.
GPA wykorzystuje przekształcenia geometryczne (tj. izotropowe przeskalowanie, odbicie, obrót lub przesunięcie) macierzy do porównania zbiorów danych. Poniższy obrazek przedstawia serię przekształceń na zielonym trójkącie docelowym.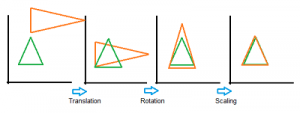
Macierz konsensusu jest (jak sama nazwa wskazuje) wynikiem uśrednienia wszystkich macierzy wejściowych. Macierze utworzone w procesie Uogólnionej Analizy Procrustes’a mogą być wprowadzone do Analizy Składowych Głównych i rzutowane na przestrzeń dwuwymiarową dla uzyskania łatwych do zrozumienia rezultatów.
Użycie w profilowaniu sensorycznym
Uogólniona Analiza Procrustes’a jest sposobem na znalezienie struktury leżącej u podstaw profilowania sensorycznego, które dzieli się na dwie kategorie: profilowanie konwencjonalne i profilowanie swobodnego wyboru.
W przypadku profilowania konwencjonalnego, oceniający mają do dyspozycji ustalony zestaw terminów opisowych. Osoby oceniające są zazwyczaj wysoko wyszkolonymi osobami. Na przykład, można zapytać trzech ekspertów o ich opinie na temat ciała, zapachu i smaku czterech marek wina. Ustalone opisy mogą obejmować rześkość, kanciastość i maślaność. Wyniki mogą być uśredniane, więc możliwe jest zastosowanie analizy czynnikowej lub analizy głównych składowych – jak również GPA – do analizy testu.
Profilowanie swobodnego wyboru daje respondentom swobodę odpowiadania na pytania w ich własnych kategoriach opisowych. Ponieważ nie ma ustalonych terminów do uśrednienia, nie jest możliwe zastosowanie analizy czynnikowej lub PCA. Metody K-sets, podobnie jak PCA, są stosowane w tego typu profilowaniu swobodnego wyboru.
Kategorie są wymiarami uogólnionej analizy Procrustes. W idealnej sytuacji liczba wymiarów jest równa (w tym przykładzie oznaczałoby to, że ekspert przyznał ocenę we wszystkich trzech obszarach). Możliwe jest jednak przeprowadzenie uogólnionej analizy Prokrustesa przy użyciu nierównych wymiarów.
Back to Top
Co to są zmienne ukryte?
 Zmienna ukryta lub „ukryta” zmienna jest ogólnie rozumiana jako zmienna, która nie jest bezpośrednio mierzalna lub obserwowalna. Na przykład, poziom neurozy u danej osoby, sumienność lub otwartość są zmiennymi ukrytymi. Chociaż nie możesz zobaczyć tych ukrytych zmiennych (nie są one częścią zbioru danych eksperymentu), mogą one powodować efekty w wynikach eksperymentu. Zmienne ukryte są również znane jako:
Zmienna ukryta lub „ukryta” zmienna jest ogólnie rozumiana jako zmienna, która nie jest bezpośrednio mierzalna lub obserwowalna. Na przykład, poziom neurozy u danej osoby, sumienność lub otwartość są zmiennymi ukrytymi. Chociaż nie możesz zobaczyć tych ukrytych zmiennych (nie są one częścią zbioru danych eksperymentu), mogą one powodować efekty w wynikach eksperymentu. Zmienne ukryte są również znane jako:
- Konstrukty lub Konstrukty hipotetyczne.
- Faktory.
- Zmienne ukryte.
- Zmienne hipotetyczne.
- Prawdziwe wyniki.
- Zmienne niemierzone.
- Zmienne nieobserwowane.
Jeden z najwcześniejszych przykładów zmiennej ukrytej został opublikowany w 1904 roku, kiedy Spearman zmierzył inteligencję używając analizy czynnikowej. Bardziej precyzyjna definicja zmiennych ukrytych jest czasami używana. Na przykład, MacCallum & Austin(2000) opisuje te zmienne jako „hipotetyczne konstrukty, które nie mogą być bezpośrednio mierzone.” Są one hipotetyczne, ponieważ istnieją tylko w umysłach badacza.
Zmienna ukryta w modelowaniu statystycznym
Zmienne ukryte są czasami używane w technikach modelowania statystycznego, takich jak analiza czynnikowa, gdzie mogą być wywnioskowane dzięki technikom modelowania. Zmienne ukryte są zawsze obecne w prawie wszystkich analizach regresji, ponieważ wszystkie addytywne warunki błędu nie są mierzalne (i dlatego są ukryte).
Metody modelowania statystycznego, które są często używane do identyfikacji zmiennych ukrytych obejmują:
- Algorytmy EM.
- Analiza czynnikowa.
- Hidden Markov Models.
- Latent Semantic Analysis.
- Principal Component Analysis.
- Structural Equation Modeling.
Zmienna ukryta może być również obecna (i uwzględniona w modelu), gdy nie ma celu jej rzeczywistego pomiaru. Melanie Wall z Columbia University oferuje następujące trzy przykłady zmiennych ukrytych, które nie są przeznaczone do pomiaru:
- Nieobserwowana heterogeniczność (np. niedoskonałości w analizie przeżywalności, efekty losowe w danych podłużnych lub danych zagregowanych)
- Brakujące dane
- Przeciwfaktyczne lub 'potencjalne wyniki'
Back to Top
Czym są zmienne manifestacyjne?
Zmienne jawne (zwane również zmiennymi obserwowalnymi) mogą być mierzone lub obserwowane bezpośrednio. Są one przeciwieństwem zmiennych ukrytych. Na przykład, wiek i płeć są zmiennymi obserwowalnymi. Jednak rzadko można mieć 100% pewności co do zmiennej; nawet „płeć”, jeśli jest obserwowana, nie jest w 100% pewna, ponieważ ludzie mogą kłamać w formularzu, ukrywać swoją prawdziwą płeć lub być osobą transgenderową. Dlatego należy używać zmiennych ukrytych, kiedy tylko jest to możliwe.
Referencja:
MacCallum RC, Austin JT. 2000. Applications of structural equation modeling in psychological research. Annu. Rev. Psychol. 51:
201-26
Stephanie Glen. „Factor analysis: Prosta definicja” From StatisticsHowTo.com: Elementarna statystyka dla reszty z nas! https://www.statisticshowto.com/factor-analysis/
—————————————————————————–
Potrzebujesz pomocy w rozwiązaniu zadania domowego lub testu? Dzięki Chegg Study możesz uzyskać rozwiązanie swoich pytań krok po kroku od eksperta w danej dziedzinie. Pierwsze 30 minut z korepetytorem Chegg jest bezpłatne!