Jeśli przeczytałeś moje wprowadzenie do formatów plików Hadoop/Spark, będziesz świadomy, że istnieje wiele sposobów na przechowywanie danych w HDFS, S3 lub Blob, a każdy z tych typów plików ma inne właściwości, które czynią je dobrymi (lub złymi) do różnych rzeczy.
Pomimo, że ten artykuł nie jest technicznym wgłębieniem się w temat, zamierzam przedstawić Ci dlaczego (i jak) powinieneś używać Parquet zamiast innego popularnego formatu, Avro.
Co to jest Parquet?
Na wysokim poziomie, Parquet jest formatem pliku do przechowywania danych strukturalnych. Na przykład, możesz użyć parkietu do przechowywania kilku rekordów, które wyglądają tak:
{ id: Integer, first_name: String, last_name: String, age: Integer, cool: Boolean, favorite_fruit: Array}Możesz, w rzeczywistości, przechowywać te dane w prawie każdym formacie pliku, przyjaznym dla czytelnika sposobem przechowywania tych danych jest plik CSV lub TSV. Oto jak niektóre dane w tym schemacie mogą wyglądać w formacie CSV:
1, Matthew, Rathbone, 19, True, 2, Joe, Bloggs, 102, True, W pliku płaskim JSON, każdy wiersz jest przechowywany jako obiekt JSON:
Dla kontrastu, oto zrzut ekranu tych samych danych w ilustracyjnym formacie pliku kolumnowego, który nazywam Columnar CSV (CCSV):
Masz wątpliwości co do kolumnowych formatów plików? Przeczytaj moje wprowadzenie do kolumnowych formatów plików zanim przejdziesz dalej
Całkiem inne, prawda? Parquet idzie o krok dalej – jest formatem binarnym, a nie tekstowym. Nie martw się, istnieje wiele narzędzi, których możesz użyć do sprawdzania i odczytywania plików Parquet, a nawet eksportowania wyników do starego dobrego JSON. Na przykład Parquet Tools
Parquet Cares About Your Schema
Jednym z ograniczeń danych CSV/TSV jest to, że nie wiesz jaki powinien być dokładny schemat, lub pożądany typ każdego pola.
Przykład powyżej, bez schematu, czy wartości 'True' powinny być rzutowane na boolean? Jak możemy być pewni, nie znając wcześniej schematu?
JSON jest lepszy od CSV, ponieważ każdy wiersz zawiera pewne wskazówki dotyczące schematu, ale bez specjalnego wiersza nagłówka, nie ma sposobu na wyprowadzenie schematu dla każdego rekordu w pliku, i nie zawsze jest jasne, jaki typ wartości 'null' powinien być interpretowany jako.
Avro i Parquet z drugiej strony rozumieją schemat danych, które przechowują. Kiedy piszesz plik w tych formatach, musisz określić swój schemat. Kiedy odczytujesz plik z powrotem, mówi ci on o schemacie danych przechowywanych w nim. Jest to bardzo użyteczne dla frameworków takich jak Spark, które mogą wykorzystać te informacje, aby dać ci w pełni uformowaną ramkę danych przy minimalnym wysiłku.
Porozmawiajmy o Parquet vs Avro
Na pierwszy rzut oka, Avro i Parquet są podobne, oba zapisują schemat swoich danych w nagłówku pliku i dobrze radzą sobie z dryfem schematu (dodawanie/usuwanie kolumn). Są tak podobne pod tym względem, że Parquet nawet natywnie obsługuje schematy Avro, więc możesz migrować swoje potoki Avro do magazynu Parquet w mgnieniu oka.
Dużą różnicą w tych dwóch formatach jest to, że Avro przechowuje dane PRZEZ ROW, a Parquet przez KOLUMNY..
- Oh hai! Nie zapomnij o moim przewodniku po formatach plików kolumnowych, jeśli chcesz dowiedzieć się o nich więcej
Zalety Parquet nad Avro
Podsumowując mój przewodnik po formatach plików kolumnowych, zalety Parquet (i formatów kolumnowych w ogóle) są przede wszystkim dwojakie:
- Zmniejszone koszty przechowywania (typowo) vs Avro
- 10-100x poprawa odczytu danych gdy potrzebujesz tylko kilku kolumn
Nie mogę przecenić korzyści 100x poprawy przepustowości zapisu. Zapewnia to naprawdę ogromne i fundamentalne ulepszenie potoków przetwarzania danych, które bardzo trudno jest przeoczyć.
Tutaj znajduje się ilustracja tej korzyści z badania przypadku Cloudera z powrotem w 2016 roku na małym zbiorze danych o pojemności mniejszej niż 200 GB.
Przy zwykłym liczeniu wierszy Parquet zdmuchuje Avro, dzięki metadanym przechowywanym przez Parquet w nagłówku grup wierszy.
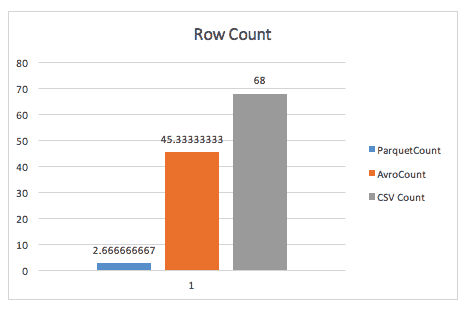
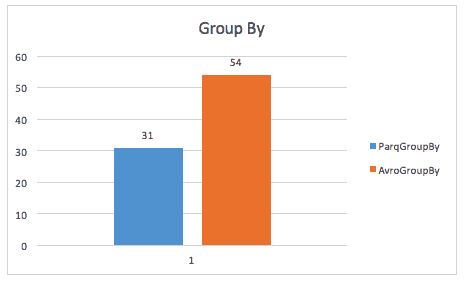
Podczas wykonywania zapytania group-by, parkiet jest nadal prawie 2x szybszy (choć nie jestem pewien dokładnego zapytania użytego tutaj).
To samo studium przypadku znajduje również ulepszenia w przestrzeni dyskowej, a nawet w pełnym skanowaniu tabel, prawdopodobnie z powodu konieczności skanowania przez Sparka mniejszego rozmiaru danych.
Korzyści z Avro nad Parquetem
Słyszałem jak niektórzy ludzie argumentowali na korzyść Avro vs Parquet. Takie argumenty są zazwyczaj oparte na dwóch punktach:
- Gdy czytasz całe rekordy naraz, Avro wygrywa w wydajności.
- Czas zapisu drastycznie wzrasta przy pisaniu plików Parquet vs Avro
Choć te dwa punkty są ważne, są to drobne przypisy w stosunku do ogólnej poprawy wydajności Parquet. Istnieje wiele benchmarków dostępnych online dla Avro vs Parquet, ale pozwól mi narysować wykres z prezentacji Hortonworks 2016 porównujący wydajność formatu pliku w różnych sytuacjach.
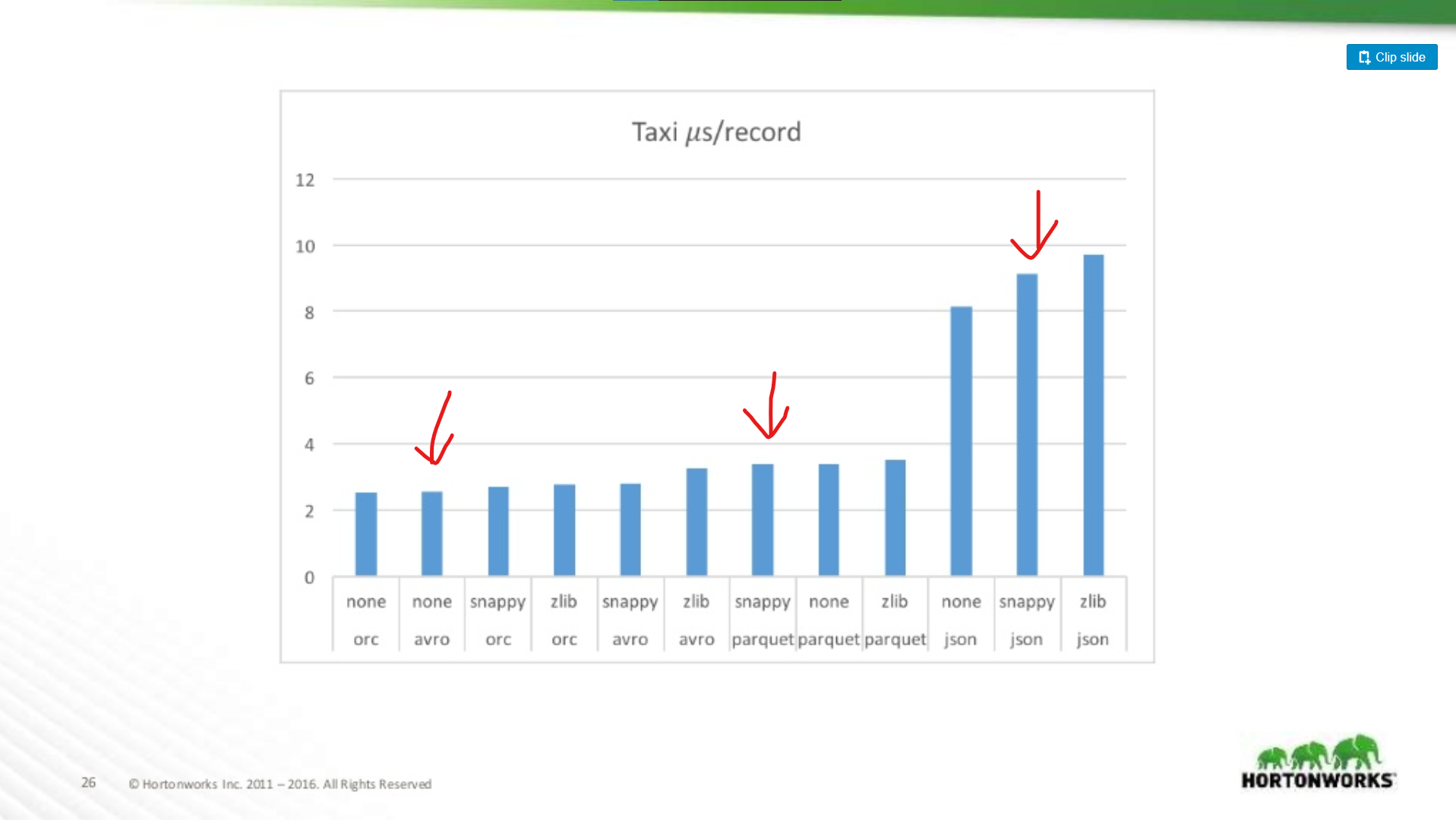
O ile gorszy jest Parquet dla skanowania całych rekordów?
Porównujemy tutaj wydajność Avro, JSON i Parquet na zbiorze danych Taxi zawierającym ~18 kolumn. W tym teście odczytywane były całe rekordy jako część zadania MapReduce, ten typ obciążenia jest najgorszym przypadkiem wydajności Parquet, a tutaj prawie dorównuje wydajności odczytu Avro.
Na drugim końcu spektrum uruchomiono przeciwko zrzutowi danych z Githuba, który miał ekstremalnie 704 kolumny danych na rekord. Tutaj widzimy bardziej znaczącą przewagę Avro:
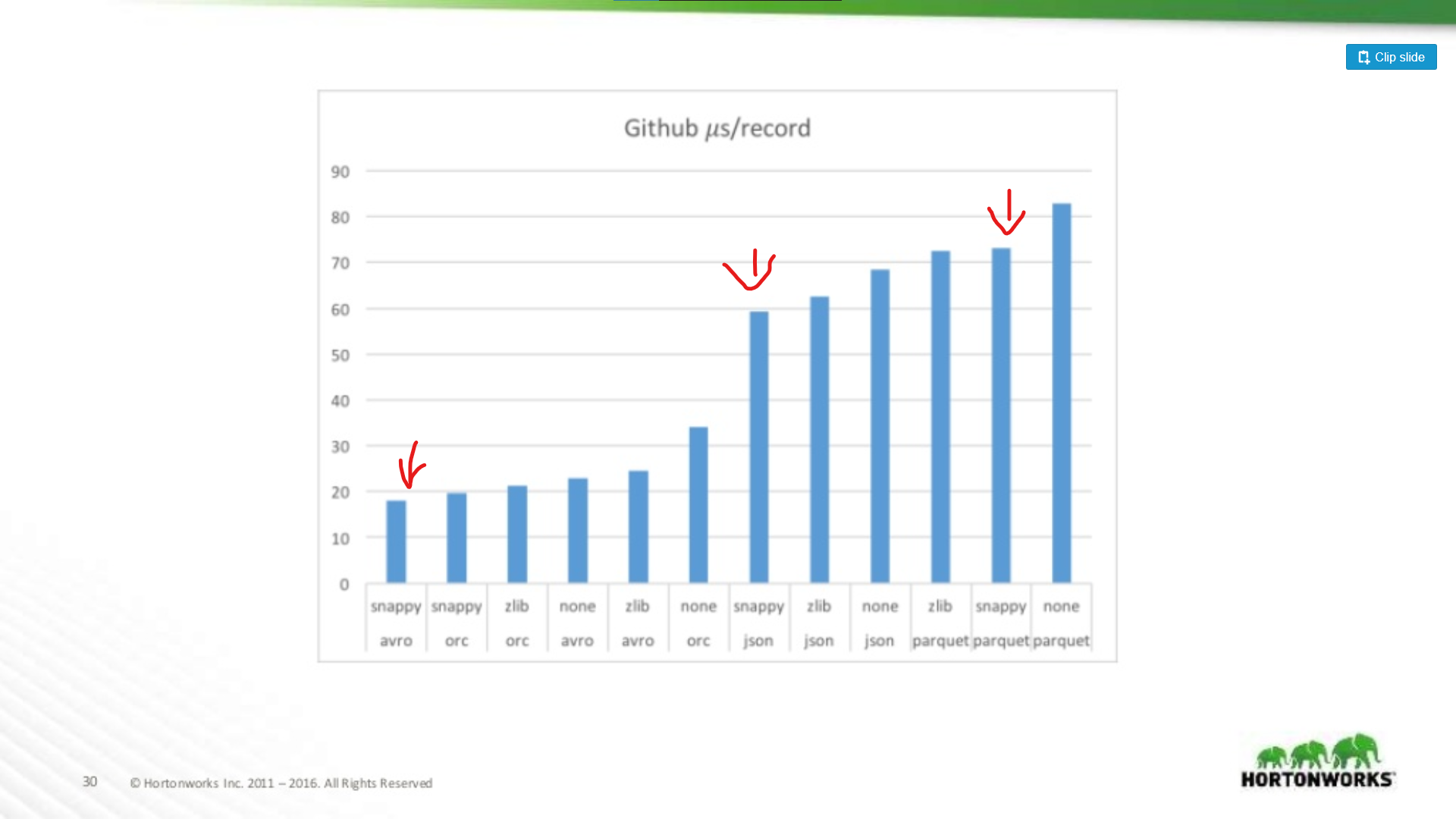
A więc im szerszy zbiór danych, tym gorszy staje się Parquet do skanowania całych rekordów (co ma sens). Jest to skrajny przykład, większość zbiorów danych nie ma 700 kolumn szerokości, dla wszystkiego co rozsądne (< 100) wydajność odczytu Parquet jest wystarczająco bliska Avro, aby nie mieć znaczenia.
Inwestycje w Parquet
Mówiąc to, łagodzenie negatywnych stron Parquet jest przedmiotem znaczących inwestycji. Na przykład zobacz ten artykuł z Cloudera na temat używania wektoryzacji w celu ograniczenia narzutu procesora na Parquet.
Wciąż widzę, że niektórzy ludzie argumentują za Avro zamiast Parquet, nawet jeśli odczyty pełnych rekordów są wolniejsze w Avro. Moja opinia jest taka, że pamięć masowa jest tania! Procesory nie są. Ten sam artykuł pokazuje korzyść z wydajności ponad 200x podczas odczytu tylko pojedynczej kolumny z pliku. Jest to naprawdę znaczące, a w miarę wzrostu zbioru danych pozwoli zaoszczędzić znaczną ilość zasobów obliczeniowych.
Parquet is Probably The Right Choice Either Way
Więc jeśli zbiór danych jest przeznaczony tylko do MapReduce, czy powinien być w Avro? Nie. Możliwość „zajrzenia” do wnętrza zbioru danych i znalezienia szybkich informacji o jego zawartości jest niezwykle pomocna, poza tym wiele frameworków MapReduce dodaje predicate-pushdown do obsługi parkietu. Parquet nie jest tylko dla Analytics!
Nawet ignorując czas działania twoich zadań produkcyjnych, pozwól mi przedstawić kilka moich ulubionych sposobów na wykorzystanie Parquet poza obciążeniami analitycznymi:
-
Weryfikacja danych – potrzebujesz wykonać kilka przybliżonych obliczeń, aby sprawdzić czy twoje dane są kompletne? Z Parquetem takie sprawdzenia można przeprowadzić w kilka sekund, nawet przy zbiorze danych o pojemności 1TB.
-
Quick Metrics Extraction – chcesz zapisać w swoim systemie monitorowania zliczanie podzbioru rekordów w twoim zbiorze danych? Poprzednio przechwytywałem te informacje uruchamiając kolejne potoki, ale z Parquetem jest to bardzo szybkie zapytanie poprzez Hive lub Spark SQL.
-
Mniej redundancji – Potrzebujesz podobnego zbioru danych dla dwóch różnych potoków? Zamiast budować odrębny zbiór danych dla każdego z nich, Parquet pozwala po prostu dynamicznie odpytywać większy, kompleksowy zbiór danych bez kar związanych ze skanowaniem całego pliku.
-
Analityka – Ok, oszukiwałem i umieściłem to w każdym razie. Tak, Parquet jest niesamowity dla analityki, każdy kto korzysta z zapytań SQL podziękuje Ci za zaoszczędzenie godzin dziennie przed monitem SQL, gdy jego zapytania będą działać 1000x szybciej.
Debugowanie – czy Twój potok wykonał właściwą czynność? Czy dodał/usunął/modyfikował właściwe rekordy? Dzięki parkietowi możesz przechwycić szybką i łatwą informację (np. wszystkie unikalne wartości kolumny) w kilka sekund bez skanowania całego pliku.
Moje zdanie: Po prostu użyj Parquet
Mimo, że uważam, że istnieją przypadki użycia Avro zamiast Parquet, te przypadki użycia zanikają.
- Narzędzia przemysłowe skupiają się wokół Parquet jako standardowego formatu przechowywania danych. Zobacz na przykład Amazon Web Services. Dadzą ci zrzut danych użytkowych w Parquet (lub CSV), a ich produkt EMR zapewnia specjalne optymalizacje zapisu dla Parquet. To samo nie dotyczy Avro.
- Frameworki takie jak MapReduce odchodzą na bok na rzecz bardziej dynamicznych frameworków, takich jak Spark, te frameworki sprzyjają stylowi programowania „dataframe”, gdzie przetwarzasz tylko te kolumny, których potrzebujesz, a resztę ignorujesz. To jest świetne dla Parquet.
- Parquet jest po prostu bardziej elastyczny. Podczas gdy nie zawsze musisz wykonywać sparse-query na zbiorze danych, bycie w stanie tego dokonać jest cholernie przydatne w wielu sytuacjach. Tego nie da się zrobić z Avro, CSV czy JSON.