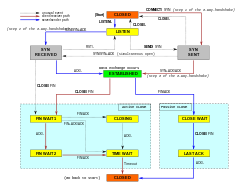
Operacje protokołu TCP można podzielić na trzy fazy. Ustanowienie połączenia jest wieloetapowym procesem handshake, który ustanawia połączenie przed przejściem do fazy transferu danych. Po zakończeniu przesyłania danych, zakończenie połączenia zamyka połączenie i zwalnia wszystkie przydzielone zasoby.
Połączenie TCP jest zarządzane przez system operacyjny poprzez zasób, który reprezentuje lokalny punkt końcowy komunikacji, gniazdo internetowe. Podczas trwania połączenia TCP, lokalny punkt końcowy przechodzi serię zmian stanu:
| Stan | Punkt końcowy | Opis |
|---|---|---|
| LISTEN | Serwer | Oczekuje na żądanie połączenia od dowolnego zdalnego punktu końcowego TCP.point. |
| SYN-SENT | Client | Oczekuje na pasujące żądanie połączenia po wysłaniu żądania połączenia. |
| SYN-RECEIVED | Serwer | Oczekuje na potwierdzenie żądania połączenia po otrzymaniu i wysłaniu żądania połączenia. |
| ESTABLISHED | Serwer i klient | Połączenie otwarte, otrzymane dane mogą być dostarczone do użytkownika. Normalny stan dla fazy przesyłania danych w połączeniu. |
| FIN-WAIT-1 | Serwer i klient | Oczekuje na żądanie zakończenia połączenia ze zdalnego TCP, lub potwierdzenie wcześniej wysłanego żądania zakończenia połączenia. |
| FIN-WAIT-2 | Serwer i klient | Oczekuje na żądanie zakończenia połączenia od zdalnego TCP. |
| CLOSE-WAIT | Serwer i klient | Oczekuje na żądanie zakończenia połączenia od lokalnego użytkownika. |
| CLOSING | Serwer i klient | Oczekuje na potwierdzenie żądania zakończenia połączenia od zdalnego TCP. |
| LAST-ACK | Serwer i klient | Oczekuje na potwierdzenie żądania zakończenia połączenia wysłanego wcześniej do zdalnego TCP (które zawiera potwierdzenie jego żądania zakończenia połączenia). |
| TIME-WAIT | Serwer lub klient | Oczekiwanie na upłynięcie wystarczającej ilości czasu, aby mieć pewność, że zdalny TCP otrzymał potwierdzenie swojego żądania zakończenia połączenia. |
| CLOSED | Serwer i klient | Brak stanu połączenia. |
Nawiązanie połączeniaEdit
Zanim klient spróbuje połączyć się z serwerem, serwer musi najpierw powiązać się z portem i nasłuchiwać na nim, aby otworzyć go na połączenia: nazywa się to pasywnym otwarciem. Gdy pasywne otwarcie zostanie ustanowione, klient może ustanowić połączenie poprzez zainicjowanie aktywnego otwarcia przy użyciu trójstronnego (lub trójstopniowego) uścisku dłoni:
- SYN: Aktywne otwarcie jest wykonywane przez klienta wysyłającego SYN do serwera. Klient ustawia numer sekwencji segmentu na losową wartość A.
- SYN-ACK: W odpowiedzi serwer odpowiada SYN-ACK. Numer potwierdzenia jest ustawiony na wartość o jeden większą od otrzymanego numeru sekwencyjnego, czyli A+1, a numer sekwencyjny, który serwer wybiera dla pakietu, to inna liczba losowa, B.
- ACK: Na koniec klient odsyła do serwera ACK. Numer sekwencji jest ustawiony na wartość otrzymanego potwierdzenia, tj. A+1, a numer potwierdzenia jest ustawiony na wartość o jeden większą niż otrzymany numer sekwencji, tj. B+1.
Kroki 1 i 2 ustanawiają i potwierdzają numer sekwencji dla jednego kierunku. Kroki 2 i 3 ustanawiają i potwierdzają numer sekwencyjny dla drugiego kierunku. Po zakończeniu tych kroków, zarówno klient jak i serwer otrzymują potwierdzenia i komunikacja full-duplex jest ustanowiona.
Zakończenie połączeniaEdit

Faza zakończenia połączenia wykorzystuje czterokierunkowy handshake, przy czym każda strona połączenia kończy połączenie niezależnie. Kiedy punkt końcowy chce zakończyć swoją połowę połączenia, wysyła pakiet FIN, który drugi koniec potwierdza pakietem ACK. Dlatego typowe zakończenie połączenia wymaga pary segmentów FIN i ACK z każdego punktu końcowego TCP. Po tym, jak strona, która wysłała pierwszy FIN odpowie ostatnim ACK, czeka na upłynięcie czasu przed ostatecznym zamknięciem połączenia, w którym to czasie lokalny port jest niedostępny dla nowych połączeń; zapobiega to zamieszaniu spowodowanemu opóźnionymi pakietami dostarczanymi podczas kolejnych połączeń.
Połączenie może być „półotwarte”, w którym to przypadku jedna strona zakończyła swój koniec, ale druga nie. Strona, która zakończyła połączenie nie może już wysyłać żadnych danych do połączenia, ale druga strona może. Kończąca strona powinna kontynuować czytanie danych, aż druga strona również zakończy połączenie.
Możliwe jest również zakończenie połączenia przez 3-way handshake, kiedy host A wysyła FIN i host B odpowiada FIN & ACK (tylko łączy 2 kroki w jeden) i host A odpowiada ACK.
Niektóre systemy operacyjne, takie jak Linux i H-UX, implementują sekwencję zamykania half-duplex w stosie TCP. Jeśli host aktywnie zamyka połączenie, podczas gdy nadal dostępne są nieprzeczytane dane przychodzące, host wysyła sygnał RST (tracąc wszelkie odebrane dane) zamiast FIN. Zapewnia to aplikację TCP, że zdalny proces przeczytał wszystkie przesłane dane poprzez oczekiwanie na sygnał FIN, zanim aktywnie zamknie połączenie. Zdalny proces nie może odróżnić sygnału RST do przerwania połączenia od utraty danych. Oba powodują, że zdalny stos traci wszystkie otrzymane dane.
Niektóre aplikacje używające protokołu TCP open/close handshaking mogą napotkać problem RST przy aktywnym zamykaniu. Jako przykład:
s = connect(remote);send(s, data);close(s);
Dla przepływu programu takiego jak powyżej, stos TCP/IP taki jak opisany powyżej nie gwarantuje, że wszystkie dane dotrą do drugiej aplikacji, jeśli nieprzeczytane dane dotarły na ten koniec.
Zużycie zasobówEdit
Większość implementacji przydziela wpis w tabeli, która mapuje sesję do działającego procesu systemu operacyjnego. Ponieważ pakiety TCP nie zawierają identyfikatora sesji, oba punkty końcowe identyfikują sesję używając adresu i portu klienta. Za każdym razem, gdy pakiet jest odbierany, implementacja TCP musi wykonać odszukanie w tej tabeli, aby znaleźć proces docelowy. Każdy wpis w tabeli jest znany jako Blok Kontroli Transmisji (Transmission Control Block lub TCB). Zawiera on informacje o punktach końcowych (IP i port), status połączenia, bieżące dane o wymienianych pakietach oraz bufory do wysyłania i odbierania danych.
Liczba sesji po stronie serwera jest ograniczona jedynie pamięcią i może rosnąć wraz z napływem nowych połączeń, ale klient musi przydzielić losowy port przed wysłaniem pierwszego SYN do serwera. Port ten pozostaje przydzielony przez cały czas trwania konwersacji i skutecznie ogranicza liczbę połączeń wychodzących z każdego adresu IP klienta. Jeśli aplikacja nie zamknie prawidłowo nieżądanych połączeń, klientowi może zabraknąć zasobów i nie będzie w stanie nawiązać nowych połączeń TCP, nawet z innymi aplikacjami.
Oba punkty końcowe muszą również przydzielić miejsce na niepotwierdzone pakiety i odebrane (ale nieprzeczytane) dane.
Przesyłanie danychEdit
Protokół Kontroli Transmisji różni się kilkoma kluczowymi cechami od protokołu User Datagram Protocol:
- Zamówione przesyłanie danych: host docelowy zmienia kolejność segmentów zgodnie z numerem sekwencyjnym
- Retransmisja utraconych pakietów: każdy skumulowany strumień nie potwierdzony jest retransmitowany
- Bezbłędne przesyłanie danych
- Kontrola przepływu: ogranicza szybkość przesyłania danych przez nadawcę w celu zagwarantowania niezawodnego dostarczenia. Odbiornik nieustannie podpowiada nadawcy, ile danych może zostać odebranych (kontrolowane przez przesuwane okno). Kiedy bufor hosta odbierającego zapełnia się, następne potwierdzenie zawiera 0 w rozmiarze okna, aby zatrzymać transfer i pozwolić na przetworzenie danych w buforze.
- Kontrola zagęszczeń
Niezawodna transmisjaEdit
TCP używa numeru sekwencyjnego do identyfikacji każdego bajtu danych. Numer sekwencyjny identyfikuje kolejność bajtów wysyłanych z każdego komputera, dzięki czemu dane mogą być odtworzone w kolejności, niezależnie od zmiany kolejności pakietów lub utraty pakietów, które mogą wystąpić podczas transmisji. Numer sekwencji pierwszego bajtu jest wybierany przez nadajnik dla pierwszego pakietu, który jest oznaczony jako SYN. Numer ten może być dowolny i w rzeczywistości powinien być nieprzewidywalny, aby obronić się przed atakami TCP sequence prediction.
Potwierdzenia (ACK) są wysyłane z numerem sekwencji przez odbiorcę danych, aby poinformować nadawcę, że dane zostały odebrane do określonego bajtu. Potwierdzenia ACK nie oznaczają, że dane zostały dostarczone do aplikacji. Oznaczają one jedynie, że odbiorca jest teraz odpowiedzialny za dostarczenie danych.
Reliability is achieved by the sender detecting lost data and retransmitting it. TCP wykorzystuje dwie podstawowe techniki do identyfikacji utraty danych. Retransmisja timeout (w skrócie RTO) oraz duplikaty skumulowanych potwierdzeń (DupAcks).
Retransmisja oparta na DupackEdit
Jeśli pojedynczy segment (powiedzmy segment 100) w strumieniu jest utracony, to odbiornik nie może potwierdzić pakietów powyżej nr. 100 ponieważ używa on skumulowanych ACK. Dlatego odbiornik potwierdza pakiet 99 ponownie przy odbiorze innego pakietu danych. To zduplikowane potwierdzenie jest używane jako sygnał utraty pakietu. Oznacza to, że jeśli nadawca otrzyma trzy duplikaty potwierdzeń, retransmituje ostatni niepotwierdzony pakiet. Próg trzech jest używany, ponieważ sieć może zmienić kolejność segmentów powodując duplikaty potwierdzeń. Wykazano, że próg ten pozwala uniknąć fałszywych retransmisji spowodowanych zmianą kolejności. Czasami stosuje się selektywne potwierdzenia (SACK) w celu dostarczenia wyraźnej informacji zwrotnej o odebranych segmentach. To znacznie poprawia zdolność TCP do retransmisji właściwych segmentów.
Retransmisja oparta na czasie
Kiedy nadawca transmituje segment, inicjalizuje licznik czasu z ostrożnym oszacowaniem czasu nadejścia potwierdzenia. Segment jest retransmitowany po upływie timera, z nowym progiem czasowym równym dwukrotności poprzedniej wartości, co skutkuje wykładniczym działaniem backoff. Typowo, początkowa wartość timera to wygładzone RTT + max ( G , 4 × zmienność RTT ) {tekst {smoothed RTT}}+max(G,4 razy {tekst {zmienność RTT}})}.

, gdzie G {{displaystyle G}

to granularność zegara. Chroni to przed nadmiernym ruchem transmisyjnym spowodowanym przez wadliwe lub złośliwe podmioty, takie jak napastnicy man-in-the-middle denial of service.
Wykrywanie błędówEdit
Numery sekwencji pozwalają odbiorcom na odrzucenie zduplikowanych pakietów i prawidłowe uszeregowanie ponownie uporządkowanych pakietów. Potwierdzenia pozwalają nadawcom określić, kiedy należy retransmitować utracone pakiety.
Aby zapewnić poprawność, dołączane jest pole sumy kontrolnej; zobacz sekcję Obliczanie sumy kontrolnej, aby poznać szczegóły dotyczące sumy kontrolnej. Suma kontrolna TCP jest słabym sprawdzianem jak na współczesne standardy. Warstwy łącza danych z wysokim poziomem błędów bitowych mogą wymagać dodatkowych możliwości korekcji/detekcji błędów łącza. Słaba suma kontrolna jest częściowo kompensowana przez powszechne użycie CRC lub lepszej kontroli integralności w warstwie 2, poniżej zarówno TCP jak i IP, jak to jest używane w PPP lub ramce Ethernet. Nie oznacza to jednak, że 16-bitowa suma kontrolna TCP jest zbędna: co ciekawe, wprowadzanie błędów do pakietów pomiędzy węzłami chronionymi przez CRC jest powszechne, ale końcowa 16-bitowa suma kontrolna TCP wyłapuje większość tych prostych błędów. To jest zasada end-to-end w pracy.
Kontrola przepływuEdit
TCP używa protokołu kontroli przepływu end-to-end, aby uniknąć sytuacji, w której nadawca wysyła dane zbyt szybko, aby odbiorca TCP mógł je odebrać i przetworzyć w sposób niezawodny. Posiadanie mechanizmu kontroli przepływu jest niezbędne w środowisku, w którym komunikują się maszyny o różnych prędkościach sieci. Na przykład, jeśli komputer wysyła dane do smartfona, który powoli przetwarza otrzymane dane, smartfon musi regulować przepływ danych, aby nie zostać przeciążonym.
TCP używa protokołu kontroli przepływu z przesuwanymi oknami. W każdym segmencie TCP, odbiorca określa w polu okna odbiorczego ilość dodatkowo odebranych danych (w bajtach), które jest skłonny buforować dla połączenia. Host wysyłający może wysłać tylko do tej ilości danych, zanim będzie musiał czekać na potwierdzenie i aktualizację okna od hosta odbierającego.

Gdy odbiorca ogłasza rozmiar okna równy 0, nadawca przestaje wysyłać dane i uruchamia licznik czasu persist. Timer persist jest używany do ochrony TCP przed sytuacją impasu, która mogłaby powstać, gdyby kolejna aktualizacja rozmiaru okna od odbiorcy została utracona, a nadawca nie może wysłać więcej danych do czasu otrzymania nowej aktualizacji rozmiaru okna od odbiorcy. Kiedy licznik czasu upływa, nadawca TCP próbuje odzyskać dane, wysyłając mały pakiet, aby odbiorca odpowiedział wysłaniem kolejnego potwierdzenia zawierającego nowy rozmiar okna.
Jeżeli odbiornik przetwarza przychodzące dane w małych przyrostach, może wielokrotnie ogłaszać małe okno odbioru. Jest to określane jako syndrom głupiego okna, ponieważ wysyłanie tylko kilku bajtów danych w segmencie TCP jest nieefektywne, biorąc pod uwagę stosunkowo duży narzut nagłówka TCP.
Kontrola zatorówEdit
Ostatnim głównym aspektem TCP jest kontrola zatorów. TCP wykorzystuje szereg mechanizmów w celu osiągnięcia wysokiej wydajności i uniknięcia załamania zatorowego, w którym wydajność sieci może spaść o kilka rzędów wielkości. Mechanizmy te kontrolują szybkość danych wchodzących do sieci, utrzymując przepływ danych poniżej szybkości, która spowodowałaby zapaść. Dają one również w przybliżeniu max-min sprawiedliwy przydział pomiędzy przepływami.
Potwierdzenia za wysłane dane, lub brak potwierdzeń, są używane przez nadawców do wnioskowania o warunkach sieciowych pomiędzy nadawcą i odbiorcą TCP. W połączeniu z timerami, nadawcy i odbiorcy TCP mogą zmieniać zachowanie przepływu danych. Jest to bardziej ogólnie określane jako kontrola zatorów i/lub unikanie zatorów w sieci.
Nowoczesne implementacje TCP zawierają cztery powiązane ze sobą algorytmy: powolny start, unikanie zatorów, szybki retransmisja i szybkie odzyskiwanie (RFC 5681).
Dodatkowo, nadawcy stosują limit czasu retransmisji (RTO), który jest oparty na szacowanym czasie przejścia w obie strony (lub RTT) między nadawcą a odbiorcą, jak również na wariancji tego czasu. Zachowanie tego timera jest określone w RFC 6298. Istnieją subtelności w szacowaniu RTT. Na przykład, nadawcy muszą być ostrożni przy obliczaniu próbek RTT dla retransmitowanych pakietów; zazwyczaj używają algorytmu Karna lub znaczników czasu TCP (patrz RFC 1323). Te indywidualne próbki RTT są następnie uśredniane w czasie, aby stworzyć wygładzony czas podróży w obie strony (Smoothed Round Trip Time – SRTT) przy użyciu algorytmu Jacobsona. Ta wartość SRTT jest ostatecznie używana jako oszacowanie czasu podróży w obie strony.
Ulepszanie TCP w celu niezawodnej obsługi strat, minimalizacji błędów, zarządzania zatorami i szybkiej pracy w środowiskach o bardzo dużych prędkościach to ciągłe obszary badań i rozwoju standardów. W rezultacie, istnieje wiele odmian algorytmu unikania zatorów TCP.
Maksymalny rozmiar segmentuEdit
Maksymalny rozmiar segmentu (MSS) to największa ilość danych, określona w bajtach, którą TCP jest w stanie odebrać w pojedynczym segmencie. Aby uzyskać najlepszą wydajność, MSS powinien być ustawiony na tyle mały, aby uniknąć fragmentacji IP, która może prowadzić do utraty pakietów i nadmiernych retransmisji. Aby spróbować to osiągnąć, zwykle MSS jest ogłaszany przez każdą ze stron za pomocą opcji MSS podczas nawiązywania połączenia TCP, w którym to przypadku jest on wyprowadzany z maksymalnego rozmiaru jednostki transmisji (MTU) warstwy łącza danych sieci, do których nadawca i odbiorca są bezpośrednio podłączeni. Ponadto, nadawcy TCP mogą używać odkrywania MTU ścieżki, aby wywnioskować minimalne MTU wzdłuż ścieżki sieciowej pomiędzy nadawcą i odbiorcą, i używać tego do dynamicznego dostosowania MSS, aby uniknąć fragmentacji IP w sieci.
Ogłoszenie MSS jest również często nazywane „negocjacją MSS”. Ściśle mówiąc, MSS nie jest „negocjowany” pomiędzy inicjatorem a odbiorcą, ponieważ sugerowałoby to, że zarówno inicjator jak i odbiorca będą negocjować i zgadzać się na pojedynczy, zunifikowany MSS, który ma zastosowanie do całej komunikacji w obu kierunkach połączenia. W rzeczywistości, dwie całkowicie niezależne wartości MSS są dozwolone dla dwóch kierunków przepływu danych w połączeniu TCP. Sytuacja taka może mieć miejsce na przykład wtedy, gdy jedno z urządzeń uczestniczących w połączeniu ma niezwykle ograniczoną ilość zarezerwowanej pamięci (być może nawet mniejszą niż całkowite odkryte MTU ścieżki) do przetwarzania przychodzących segmentów TCP.
Potwierdzenia selektywneEdit
Poleganie wyłącznie na schemacie kumulatywnych potwierdzeń stosowanym przez oryginalny protokół TCP może prowadzić do nieefektywności w przypadku utraty pakietów. Na przykład, załóżmy, że bajty o numerach sekwencji od 1,000 do 10,999 są wysyłane w 10 różnych segmentach TCP o równym rozmiarze, a drugi segment (o numerach sekwencji od 2,000 do 2,999) zostaje utracony podczas transmisji. W czystym protokole kumulatywnego potwierdzenia, odbiorca może wysłać tylko kumulatywną wartość ACK równą 2,000 (numer sekwencji bezpośrednio następujący po ostatnim numerze sekwencji otrzymanych danych) i nie może powiedzieć, że otrzymał bajty od 3,000 do 10,999 pomyślnie. Dlatego nadawca może być zmuszony do ponownego wysłania wszystkich danych począwszy od numeru sekwencji 2000.
Aby złagodzić ten problem TCP stosuje opcję selektywnego potwierdzenia (SACK), zdefiniowaną w 1996 roku w RFC 2018, która pozwala odbiorcy na potwierdzenie nieciągłych bloków pakietów, które zostały odebrane poprawnie, oprócz numeru sekwencji bezpośrednio następującego po ostatnim numerze sekwencji ostatniego ciągłego bajtu odebranego kolejno, jak w podstawowym potwierdzeniu TCP. Potwierdzenie może określać liczbę bloków SACK, gdzie każdy blok SACK jest przekazywany przez Lewą Krawędź Bloku (pierwszy numer sekwencji bloku) i Prawą Krawędź Bloku (numer sekwencji bezpośrednio następujący po ostatnim numerze sekwencji bloku), przy czym Blok jest ciągłym zakresem, który odbiorca poprawnie odebrał. W powyższym przykładzie, odbiorca wysłałby segment ACK z łączną wartością ACK równą 2,000 i nagłówkiem opcji SACK z numerami sekwencji 3,000 i 11,000. Nadawca odpowiednio retransmitowałby tylko drugi segment o numerach sekwencji od 2,000 do 2,999.
Nadawca TCP może zinterpretować dostarczenie segmentu poza kolejnością jako segment utracony. Jeśli tak się stanie, nadawca TCP dokona retransmisji segmentu poprzedzającego nieuporządkowany pakiet i zwolni szybkość dostarczania danych dla tego połączenia. Opcja duplicate-SACK, rozszerzenie opcji SACK, która została zdefiniowana w maju 2000 roku w RFC 2883, rozwiązuje ten problem. Odbiornik TCP wysyła D-ACK, aby wskazać, że żadne segmenty nie zostały utracone, a nadawca TCP może przywrócić wyższą prędkość transmisji.
Opcja SACK nie jest obowiązkowa i zaczyna działać tylko wtedy, gdy obie strony ją obsługują. Jest ona negocjowana podczas nawiązywania połączenia. SACK używa opcji nagłówka TCP (patrz struktura segmentów TCP dla szczegółów). Użycie SACK stało się powszechne – wszystkie popularne stosy TCP obsługują to rozwiązanie. Potwierdzenie selektywne jest również używane w protokole SCTP (Stream Control Transmission Protocol).
Skalowanie oknaEdit
W celu bardziej efektywnego wykorzystania sieci o dużej przepustowości można zastosować większy rozmiar okna TCP. Pole rozmiaru okna TCP kontroluje przepływ danych, a jego wartość jest ograniczona do zakresu od 2 do 65 535 bajtów.
Ponieważ pole rozmiaru nie może być rozszerzane, stosuje się współczynnik skalowania. Opcja skalowania okna TCP, zdefiniowana w RFC 1323, jest opcją używaną do zwiększenia maksymalnego rozmiaru okna z 65 535 bajtów do 1 gigabajta. Skalowanie do większych rozmiarów okien jest częścią tego, co jest niezbędne do dostrajania TCP.
Opcja window scale jest używana tylko podczas 3-way handshake TCP. Wartość skali okna reprezentuje liczbę bitów, o które należy przesunąć w lewo 16-bitowe pole rozmiaru okna. Wartość skali okna może być ustawiona od 0 (brak przesunięcia) do 14 dla każdego kierunku niezależnie. Obie strony muszą wysłać tę opcję w swoich segmentach SYN, aby włączyć skalowanie okna w obu kierunkach.
Niektóre routery i firewalle pakietowe przepisują współczynnik skalowania okna podczas transmisji. Powoduje to, że strona wysyłająca i odbierająca przyjmują różne rozmiary okien TCP. Efektem jest niestabilny ruch, który może być bardzo wolny. Problem ten jest widoczny na niektórych stronach za uszkodzonym routerem.
Znaczniki czasowe TCPEdit
Znaczniki czasowe TCP, zdefiniowane w RFC 1323 w 1992 roku, mogą pomóc TCP w określeniu, w jakiej kolejności pakiety zostały wysłane.Znaczniki czasowe TCP nie są zwykle wyrównane do zegara systemowego i zaczynają się od jakiejś losowej wartości. Wiele systemów operacyjnych będzie inkrementować timestamp dla każdej upływającej milisekundy; jednakże RFC stwierdza jedynie, że ticki powinny być proporcjonalne.
Istnieją dwa pola timestamp:
4-bajtowa wartość timestamp nadawcy (mój timestamp) 4-bajtowa wartość timestamp odpowiedzi echa (najnowszy timestamp otrzymany od ciebie).
Znaczniki czasowe TCP są używane w algorytmie znanym jako Protection Against Wrapped Sequence numbers, lub PAWS (zobacz RFC 1323 po szczegóły). PAWS jest używany, gdy okno odbiorcze przekroczy granicę zawijania numerów sekwencji. W przypadku, gdy pakiet został potencjalnie retransmitowany odpowiada on na pytanie: „Czy ten numer sekwencyjny znajduje się w pierwszych 4 GB czy w drugich?”. A znacznik czasowy jest używany do przełamania remisu.
Albo, algorytm wykrywania Eifel (RFC 3522) używa znaczników czasowych TCP do określenia, czy retransmisje występują, ponieważ pakiety zostały utracone lub po prostu są poza kolejnością.
Ostatnie statystyki pokazują, że poziom adopcji znaczników czasowych uległ stagnacji, na poziomie ~40%, z powodu porzucenia wsparcia przez serwer Windows od Windows Server 2008.
Znaczniki czasowe TCP są domyślnie włączone w jądrze Linux…, i domyślnie wyłączone w Windows Server 2008, 2012 i 2016.
Ostatnie daneOstatnie daneEdit
Możliwe jest przerwanie lub przerwanie strumienia w kolejce zamiast czekania na zakończenie strumienia. Odbywa się to poprzez określenie danych jako pilne. To mówi programowi odbiorczemu, aby przetworzył je natychmiast, razem z pozostałymi pilnymi danymi. Po zakończeniu TCP informuje aplikację i powraca do kolejki strumienia. Przykładem jest sytuacja, gdy TCP jest używany do zdalnego logowania, użytkownik może wysłać sekwencję klawiatury, która przerywa lub przerywa działanie programu na drugim końcu. Sygnały te są najczęściej potrzebne, gdy program na zdalnej maszynie nie działa poprawnie. Sygnały te muszą być wysyłane bez czekania, aż program zakończy swój bieżący transfer.
Dane pozapasmoweTCP nie zostały zaprojektowane dla współczesnego Internetu. Pilny wskaźnik zmienia tylko przetwarzanie na zdalnym hoście i nie przyspiesza żadnego przetwarzania w samej sieci. Kiedy dociera do zdalnego hosta, istnieją dwie nieco odmienne interpretacje protokołu, co oznacza, że tylko pojedyncze bajty danych OOB są wiarygodne. Zakładając, że są one w ogóle wiarygodne, ponieważ jest to jeden z najrzadziej używanych elementów protokołu i zazwyczaj jest źle zaimplementowany.
Wymuszanie dostarczenia danychEdit
Normalnie, TCP czeka 200 ms na wysłanie pełnego pakietu danych (Algorytm Nagle’a próbuje grupować małe wiadomości w pojedynczy pakiet). To oczekiwanie tworzy małe, ale potencjalnie poważne opóźnienia, jeśli jest stale powtarzane podczas transferu plików. Dla przykładu, typowy blok wysyłania ma 4 KB, typowy MSS to 1460, więc 2 pakiety wychodzą przez ethernet 10 Mbit/s zajmując ~1.2 ms każdy, po czym trzeci przenosi pozostałe 1176 po 197 ms przerwy, ponieważ TCP czeka na pełny bufor.
W przypadku telnetu, każde naciśnięcie klawisza przez użytkownika jest odsyłane przez serwer zanim użytkownik może zobaczyć je na ekranie. To opóźnienie może stać się bardzo irytujące.
Ustawienie opcji gniazda TCP_NODELAY zastępuje domyślne 200 ms opóźnienia wysyłania. Programy aplikacji używają tej opcji gniazda, aby wymusić wysłanie danych wyjściowych po napisaniu znaku lub linii znaków.
RFC definiuje bit push PSH jako „wiadomość do odbierającego stosu TCP, aby natychmiast wysłać te dane do odbierającej aplikacji”. Nie ma sposobu, aby wskazać lub kontrolować go w przestrzeni użytkownika za pomocą gniazd Berkeley i jest on kontrolowany tylko przez stos protokołu.